Żądny wiedzy? Wbijaj na Mega Sekurak Hacking Party w maju! -30% z kodem: majearly

Statyczna analiza bezpieczeństwa kodu aplikacji (część 1.) — wprowadzenie
Statyczna analiza kodu jest metodą zwiększania jakości wytwarzanego oprogramowania przez częstą, automatyczną analizę kodu źródłowego.
W jaki sposób przenieść taką analizę, która zazwyczaj przeprowadzana jest przez samych programistów, na barki inżyniera bezpieczeństwa?
Jak automatycznie weryfikować kod, nie tyle tropiąc złe praktyki programistyczne, lecz analizując go ściśle pod kątem znajdywania błędów bezpieczeństwa?
Analiza kodu źródłowego jest procesem niezwykle żmudnym, jednak jest to jedna z najskuteczniejszych metod znajdywania podatności oprogramowania. Proces ten jest bardzo dobrze znany programistom, którzy na co dzień używają tej techniki podczas wytwarzania oprogramowania, wykorzystując narzędzia wbudowane w środowisko programistyczne lub nawet sam kompilator.
W tym cyklu artykułów spróbujemy zrozumieć sens działania narzędzi dedykowanych statycznej analizie kodu, poznać ich mocne oraz słabe strony.
Z tego cyklu dowiesz się:
- czym jest statyczna analiza kodu,
- w jaki sposób dzięki niej można zwiększać bezpieczeństwo aplikacji oraz jakie rodzaje błędów nie zostaną przez nią wykryte,
- jak przeprowadzać statyczną analizę kodu pod względem bezpieczeństwa w aplikacjach .NET, PHP oraz Java z wykorzystaniem darmowych narzędzi.
Czym jest, a czym nie jest statyczna analiza kodu
Samo pojęcie statycznej analizy kodu jest nieco rozmyte. W kontekście tego artykułu przyjmijmy definicję, która opisuje statyczną analizę kodu, jako badanie źródeł oprogramowania przy wykorzystaniu narzędzi (automatów). Celem analizy jest znajdywanie nieefektywnych konstrukcji oraz fragmentów kodu, które noszą znamiona złych praktyk programistycznych czy nawet błędów bezpieczeństwa.
Powyższa definicja kładzie nacisk na automatyzację testów jakości kodu źródłowego. Minimalizuje się tutaj ingerencję człowieka w cały proces — odróżnia to analizę statyczną od inspekcji kodu (ang. „code review”), która zajmuje dużo więcej czasu (ale jest bardziej dokładna).
Warto zaznaczyć, że statyczna analiza kodu przeprowadzana jest, nomen omen, bezpośrednio na kodzie aplikacji, co oznacza, że aplikacja nie jest uruchamiana. Testy, które wymagają uruchomienia aplikacji, nazywamy analizą dynamiczną (ang. „dynamic analysis”).
Zostawiając etymologię, zastanówmy się, jakie są zalety statycznej analizy kodu oraz w jakich sytuacjach jest ona wykorzystywana.
Metoda ta służy do wykrywania fragmentów kodu, które noszą znamiona złych praktyk programistycznych, niewydajnych konstrukcji, a nawet oczywistych błędów — w tym błędów wykonania lub błędów bezpieczeństwa, które mogą pojawić się przy specyficznych danych wejściowych.
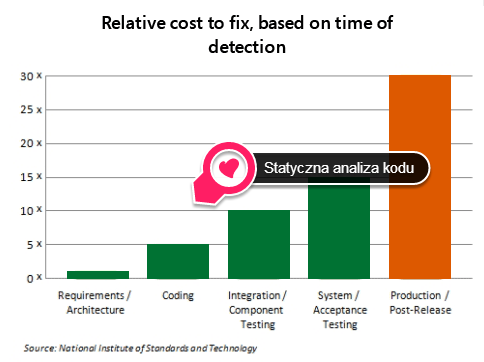
Statyczna analiza kodu jest dobrze znana programistom — narzędzia przeprowadzające tego rodzaju testy często dodawane są do środowisk programistycznych lub do procesów budowania aplikacji, aby nie pozwolić na wypuszczenie kodu niskiej jakości. Statyczna analiza kodu stanowi więc często element cyklu wytwarzania oprogramowania (ang. „Software Development Lifecycle”; SDLC). Pozwala na szybkie wykrywanie błędów, których naprawa jest prosta i mało kosztowna.
W metodykach bezpiecznego wytwarzania oprogramowania, takich jak np. Microsoft Security Development Lifecycle (SDL), statyczna analiza kodu pod kątem bezpieczeństwa jest procesem wymaganym oraz powtarzalnym. Diagram poniżej pokazuje powiązanie metodyki Agile z SDL, w której wymagane jest, aby analiza statyczna była przeprowadzana w każdej iteracji („every-sprint”). W takim wypadku błędy będą poprawiane w sprintach, gdzie zostaną wykryte, i nie będzie potrzeby rozszerzania tzw. Product Backlogu. Analiza statyczna często staje się elementem Definition of Done.

Diagram 1. Statyczna analiza kodu w cyklu bezpiecznego wytwarzania oprogramowania — Microsoft SDL; źródło.
Metody analizy
Analizatory kodu nie są prostymi regułami dla programu grep. Narzędzia przetwarzające kod wykonują analizę przepływu danych dla zmiennych, obiektów lub kontrolerów, sprawdzają kontekst wywołania, użycie niebezpiecznych funkcji oraz wiele innych rzeczy, które wykonywane są podczas inspekcji kodu.
Badania mogą być przeprowadzane zarówno na kodzie źródłowym, jak i pośrednim. Narzędzia muszą być tworzone z myślą o konkretnych językach programowania. Duże wyzwanie dla automatów stanowią języki dynamiczne oraz słabo–typowane, gdzie sama definicja reguł syntaktycznych gramatyki języka programowania może być niezwykle skomplikowana.
Wyżej wymienione wyzwania stawiane automatom do statycznej analizy kodu sprawiają, że twórcy narzędzi wykorzystują wiele algorytmów i podejść, które ostatecznie pozwalają znaleźć uchybienia w kodzie. Najpopularniejszymi metodami przetwarzania kodu źródłowego są:
- Analiza przepływu danych (ang. „Data Flow Analysis”) — polega na sprawdzeniu zasięgu, czasu życia zmiennych oraz zależności między nimi. Identyfikowane są tzw. bloki podstawowe, tworzone są grafy kontroli przepływu (ang. „Control Flow Graph”), a następnie analizowane są przepływy danych przy wykorzystaniu tych grafów. Dobry wstęp do tematu analizy przepływu danych opisuje angielska Wikipedia.
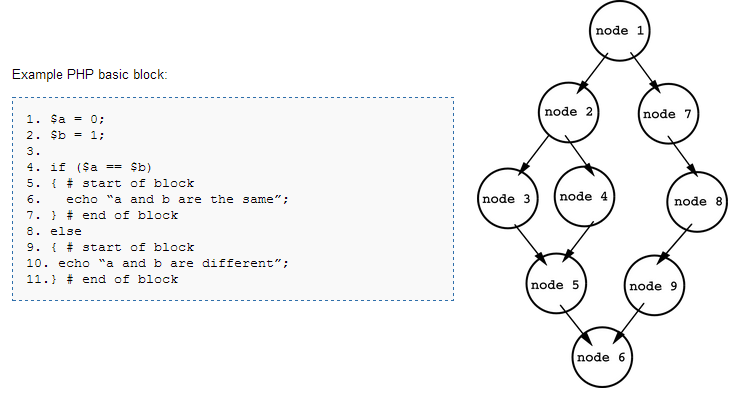
Diagram 2. Analiza przepływu danych — identyfikacja bloków podstawowych oraz tworzenie grafu kontroli przepływu.
- Taint Analysis — polega na identyfikacji zmiennych kontrolowanych przez użytkownika, oznaczeniu ich (jako „brudne”), a następnie sprawdzeniu przez jakie funkcje zmienne te są wykorzystywane. Sprawdzane są z góry zdefiniowane funkcje, które mogą stwarzać problemy bezpieczeństwa — funkcje te nazywa się z angielskiego „Sink”. Jeżeli zmienna kontrolowana przez użytkownika przechodzi przez „Sink” i nie jest uprzednio odpowiednio kodowana czy transformowana, wtedy oznaczana jest jako zagrożenie.
- Analiza leksykograficzna (ang. „Lexical Analysis”) — jest to analiza gramatyczna kodu pod kątem wykrywania popularnych konstrukcji powodujących błędy bezpieczeństwa. Ogólnie metoda ta polega na wyodrębnianiu pojedynczych jednostek leksykalnych (leksemów, tokenów), które pozwalają przeprowadzać analizę w sposób bardziej abstrakcyjny — przykładowo z pominięciem nazw zmiennych. Następnie wykrywa się niebezpieczne konstrukcje, dopasowując tokeny do słownika niebezpiecznych konstrukcji (wyrażeń).

Diagram 3. Analiza leksykograficzna.
Narzędzia
Istnieje bardzo dużo narzędzi do statycznej analizy kodu — zarówno darmowych, jak i komercyjnych.
Darmowe narzędzia skupiają się raczej na konkretnych językach programowania — rzadko można znaleźć dobre narzędzie wykonujące testy dla kilku środowisk. W związku ze słabym rozwojem tego rodzaju automatów, darmowe analizatory są raczej przystosowane do przeprowadzania podstawowych testów — badanie skomplikowanych bibliotek, frameworków i innych rozszerzeń języków oprogramowania jest dużym wyzwaniem, któremu darmowe automaty często nie potrafią sprostać.
Stosunkowo mała aktualność, małe pokrycie testowanego kodu oraz duża liczba błędów false positives to niestety główne cechy darmowych programów do statycznej analizy kodu.
Popularnymi darmowymi narzędziami do statycznej analizy kodu są m.in.:
- CAT.NET — przeprowadzający analizę stricte pod kątem bezpieczeństwa dla aplikacji .NET;
- FxCop — podobny do CAT.NET, jednak skupiający się na wykrywaniu ogólnie błędów programistycznych aplikacji .NET, nie tylko pod względem bezpieczeństwa;
- PMD, Findbugs oraz Checkstyle — popularna trójka narzędzi do analizy kodu Java, jego poprawności, wydajności, stylu oraz oczywiście — bezpieczeństwa;
- RIPS — narzędzie skupiające się na analizie bezpieczeństwa aplikacji PHP,
- VisualCodeGrepper (VCG) — wizualizuje kod aplikacji oraz analizę ją pod kątem bezpieczeństwa C++, C#, VB, PHP, Java oraz PL/SQL;
- i wiele, wiele innych…
Powyższe narzędzia zostaną szczegółowo opisane w kolejnych częściach tego cyklu.
Komercyjne narzędzia radzą sobie zdecydowanie lepiej od bezpłatnych alternatyw, jednak koszty ich używania są bardzo wysokie — trzeba się nastawić na kwoty rzędu dziesiątek, a czasem nawet setek tysięcy złotych rocznie za dostęp do platformy testowej. Jest to spory wydatek, który całkowicie dyskwalifikuje użycie takich automatów w mniejszych projektach, startupach czy projektach open source. Narzędzia te rozwijane są jednak z dużo większą starannością, dzięki czemu stają się ciekawą inwestycją dla firm wytwarzających duże ilości oprogramowania.
Znanymi rozwiązaniami komercyjnymi są m.in. Codesecure firmy Armorize, narzędzia firmy Veracode, Parasoft lub Checkmarx. Co ciekawe, w dużej liczbie narzędzi komercyjnych istnieje możliwość umówienia się na wysłanie próbek programów, dzięki czemu dostaniemy bardzo dobre informacje na temat skuteczności narzędzi. Oczywiście trzeba pamiętać, że nie zawsze chcemy wysyłać kod rozwijanej aplikacji — jednak z powodzeniem można wysłać kod projektów OpenSource i sprawdzić, w jaki sposób narzędzie poradzi sobie np. ze znanymi podatnościami z list bugtracq.
Wady kontra zalety
Największą zaletą statycznej analizy kodu jest łatwość użycia oraz prostota wdrożenia w cykl wytwarzania oprogramowania. Testy zazwyczaj nie zajmują dużo czasu, więc mogą być wykonywane nawet przy najmniejszych zmianach solucji. Zarówno programiści, jak i inżynierowie bezpieczeństwa szybko dostają informacje zwrotne o podstawowych problemach kodu i mogą od razu zwiększać jego jakość.
Nie bez znaczenia jest fakt analizy samego kodu, bez potrzeby uruchamiania aplikacji i całego ekosystemu z nią związanego. Gdy inżynier bezpieczeństwa — audytor, pentester — ma dostęp do kodu źródłowego, powinien zacząć przegląd kodu właśnie od analizy statycznej, która da mu podstawowe informacje o najważniejszych problemach.
Niestety statyczna analiza kodu nie wykryje dużej grupy ataków, w szczególności tych, które związane są z konfiguracją lub logiką biznesową. Ze względu na skomplikowane algorytmy, automaty cechują się dużą liczbą błędów false positives, a nawet false negative — często zdarza się, że narzędzia nie dostrzegają niektórych modułów, nawet gdy wprost wskazujemy je do analizy.
Problemem są głównie skomplikowane (mieszane) konteksty w kodzie aplikacji (np. kontekst C#/Razor/HTML/JS) lub aspekty dodawane przez frameworki. W zasadzie im bardziej skomplikowana architektura — tym niższa skuteczność narzędzi.
Niemniej, mimo wielu wad, automaty do statycznej analizy kodu są pierwszą linią obrony przeciwko dekoncentracji programistów. W imię zasady dogłębnej ochrony, narzędzia te powinny pojawić się w każdym projekcie programistycznym — im mniej błędów, szczególnie tych najprostszych — tym mniejsze prawdopodobieństwo zostawienia luki bezpieczeństwa w oprogramowaniu.
W kolejnej części poznamy pierwsze narzędzie do statycznej analizy bezpieczeństwa kodu aplikacji .NET — Code Analysis Tool for .NET (CAT.NET), a potem: FxCop.
—Adrian “Vizzdoom” Michalczyk

O, ciekawych rzeczy się można dowiedzieć z Sekuraka, nawet nie podejrzewałem… Dzięki i czekam na kolejną część cyklu! :D
Ba. Trochę tych ciekawych cykli czy większych opracowań by się znalazło ;) Kilka z brzegu:
http://sekurak.pl/kompendium-bezpieczenstwa-hasel-atak-i-obrona/
http://sekurak.pl/lamanie-hasel-z-wykorzystaniem-cpugpu/
http://sekurak.pl/bezpieczenstwo-sieci-wi-fi-czesc-1/
http://sekurak.pl/praktyczna-implementacja-sieci-vpn-na-przykladzie-openvpn/
http://sekurak.pl/more-information-about-tp-link-backdoor/
Wiem, część czytałem, a pozostałe czekają w Pocket na lepsze czasy, śledzę wsio przez RSS. Niemniej z każdym kolejnym cyklem nie przestajecie mnie zaskakiwać. :D
:]
Po cyklu z analizy kodu, przyjdzie czas na cykl o DDoS-ach. Co więcej – całość już jest prawie gotowa do publikacji.
W takim razie czekam z niecierpliwością. :D
Bardzo wartościowy tekst, wiedza warta upowszechniania!
Drobna aktualizacja – Armorize zostało właśnie przejęte i jak próbowałem z nimi rozmawiać o testowaniu ich narzędzia pod kątem ewentualnego zakupu to się nawet nie raczyli odezwać.
Poza tym warto też wspomnieć o skanowaniu run-time, które modnie nazywa się „interaktywnym” (IAST). Testowałem Quotium Seeker i Aspect Contrast i oba wymiatają, a Contrast jest na dodatek bardzo tani.
Świetny artykuł. Czekam na dalszą część (części?) ;)
Po małym poszukiwaniu:
1. FxCop wchodzi teraz w skład Microsoft Windows SDK For Windows 7. Nie ma już samodzielnego instalatora. Tutaj (http://codeblog.vurdalakov.net/2012/05/how-to-download-fxcop-100.html) jest instrukcja jak go wydobyć z ISO, żeby nie instalować całego pakietu.
2. Status Cat.NET na chwilę obecną jest chyba „zamrożony”. Ostatnia wersja jaką udało mi się znaleźć działa z VS 2010 a i to po pewnych kombinacjach. Wersja 64 bit działa tylko z linii poleceń. Może komuś udało się znaleźć więcej informacji.
@MarcusCornus
Sprawa zarówno z FxCopem oraz CAT.NETem jest trochę bardziej skomplikowana, ale w przybliżeniu dobrze nakreśliłeś „problematykę” tych narzędzi.
Mimo tego, jeżeli wiesz jak działają te narzędzia i jakie są ich mocne/słabe strony, możesz bardzo łatwo wdrożyć je do obecnych projektów, co da BARDZO dużo dobrego.
Ale wszystkie te ciekawostki opiszę w kolejnych częściach tego cyklu – musisz troszkę poczekać :) Gwarantuję Ci, że warto używać tych programów i nawet jeśli MS nie będzie ich rozwijał, to długo jeszcze będą fajnie działać w zespołach programistycznych.
Bardzo fajny artykuł, czekam na kontynuację, widzę już artykuł o CAT.NET ale najbardziej czekam na wpisy zahaczające o PHP w którym aktualnie najwięcej pisze.
Pozdrawiam
@ziggurad – z pewnością się nie zawiedziesz, chociaż trochę jeszcze trzeba będzie poczekać :)