Mega Sekurak Hacking Party w Krakowie! 20.10.2025 r. Bilety -30%

Analiza malware w praktyce – procedury i narzędzia
W pierwszej części artykułu mieliśmy okazję zapoznać się z powszechnym dzisiaj zagrożeniem – infekcją złośliwym oprogramowaniem. W wyniku szybkiej analizy udało nam się ustalić kilka podstawowych informacji, które teraz wykorzystamy operacyjnie.
Artykuł skierowany jest zarówno do obrońców, którzy na co dzień muszą lub będą musieli zmagać się z takimi wyzwaniami, jak również obeznanych technicznie praktyków, którzy chcieliby dołączyć omówione narzędzia i taktyki do wachlarza swoich umiejętności. Odchodzimy również powoli od tematu analizy w kierunku wykorzystania jej wyników do obrony.
Pierwsza część artykułu jest bardziej teoretyczna. Pokazuje, że analiza złośliwego oprogramowania jest tylko fragmentem większego procesu – obsługi incydentu oraz wypracowywania odpowiedniego podejścia do bezpieczeństwa w organizacji.
W drugiej części artykułu w bardzo zwięzły sposób pokazuję kolejne narzędzia które można wykorzystać w defensywie – dołożyłem starań, aby zawarte w niej informacje można było w szybki sposób zastosować w praktyce oraz zostawiam szerokie pole do eksperymentowania.
Cele i priorytety
Nim ponownie rzucimy się w wir walki, powinniśmy zdać sobie sprawę, jaki stawiamy przed sobą cel. Jeżeli jest to obrona organizacji przed nieznanym i niewykrywanym zagrożeniem, powinniśmy z całego procesu wyciągnąć stosowne wnioski na przyszłość.
Działania operacyjne „ad-hoc” nie zastąpią długoterminowej strategii, mogą natomiast pomóc w identyfikacji słabych punktów, budowie zaplecza oraz gromadzeniu środków pozwalających na efektywną walkę z malware w przyszłości.
Reagowanie na incydenty
1. Jak reagować na incydenty?
W zależności od przyjętej interpretacji, sama infekcja stacji może być lub nie – incydentem bezpieczeństwa. O ile pierwsze przychodzi naturalnie, to drugie stwierdzenie, które na początku może wydawać się niefortunne – okazuje się tym prawidłowym.
Sytuację tę można porównać do przebicia opony w samochodzie. Jeżeli nie jechaliśmy z zawrotną prędkością, udało nam się zatrzymać samochód i mieliśmy przygotowany plan (w postaci zapasowej opony), to bez większego problemu wyjdziemy z tej opresji bez szwanku.
Wykonanie obcego kodu – o ile nie jest nam w stanie wyrządzić poważnej szkody, wcale nie musi stawiać wszystkich na baczność. Dla przykładu – koń trojański, który nie może „zadzwonić do domu”, ransomware, który zaszyfrował pliki, ale można je szybko odtworzyć z backupu, lub VBKLIP zainstalowany na stacji developera.
Oprogramowanie szpiegowskie wymaga od operatorów czasu na osiągnięcie zamierzonego celu – od rozpoznania środowiska przez identyfikację celu, po wykonanie ostatecznego zadania. Wszystko zależy od tego czy rozumiemy zagrożenie i czy jesteśmy na taką sytuację odpowiednio przygotowani.
Na drugiej szali znajduje się nieopanowana infekcja robakiem, która może szybko rozprzestrzeniać się po sieci wewnętrznej i wywołać prawdziwy chaos. Zainfekowane urządzenie przenośne może tylko czekać na powrót do firmy. Dropper może zostać wykorzystany do instalacji wielu różnych odmian malware naraz, a autorzy złośliwego oprogramowania prześcigają się w metodach ukrywania i przetrwania infekcji, nawet po jej wykryciu. W swojej karierze autor spotkał się już zbyt wiele razy z niecałkowicie usuniętymi infekcjami, powracającymi jak obietnice wcześniejszych emerytur w kampaniach wyborczych.
2. Szczęście sprzyja przygotowanym – planuj, że coś pójdzie źle
Doświadczenie autora podpowiada, że nie należy pytać 'czy’ będziemy atakowani, lecz 'kiedy,’ i co możemy zrobić, aby zmniejszyć negatywne skutki. Jednym z powszechnych błędów jest myślenie, że mnie lub mojej organizacji problem podatności na ataki nie dotyczy. W tym kontekście istotne znaczenie ma właściwe podejście, tj. uznanie problemu i planowanie polegające na możliwie najlepszym przygotowaniu się na ataki. Jednym z kluczowych elementów jest tzw. postawa pro-aktywna, a więc wspomniane wcześniej przygotowanie zawczasu na ewentualne niepożądane i niebezpieczne zdarzenia.
Po praktyczne szczegóły dotyczące obsługi incydentów odsyłam tutaj.
W tej części zaprezentuję natomiast kilka dobrych praktyk i praktycznych sztuczek.
Jak zabrać się do przygotowania obrony?
1. Model zagrożeń – w procesie modelowania zagrożeń pod uwagę bierze się zasoby, które chcemy chronić (assets), określa się klasy napastników i zagrożeń (threats) oraz enumeruje poszczególne scenariusze. W zależności od przyjętej metodyki, wynikiem takiego modelowania może być lista zabezpieczeń (blokujących oraz monitoringu) dla danych zagrożeń.
Idealnie, jeżeli w proces modelowania zaangażowana jest grupa osób złożona między innymi z reprezentantów IT security (świadomość zagrożeń), administratorów sieci (architektura sieci, sprzęt i jego konfiguracja), administratorów systemów, obsługi technicznej (stan bieżący) oraz biznesu (ocena wpływu zagrożenia na biznes, w szczególności na kluczowe procesy). Przy braku zasobów, modelowanie można oczywiście przeprowadzić w mniejszym gronie. Tu dobry przykład samego procesu:
2. Defense in depth – strategia mówiąca, że przełamanie/niezadziałanie pojedynczych elementów nie może prowadzić do kompromitacji całego systemu. Każdy dodatkowy krok i zabezpieczenie oddala napastników od celu oraz zwiększa prawdopodobieństwo wykrycia i powstrzymania ataku (dla tych którzy nie boją się otwierać PDF od NSA).
3. Przygotowany wcześniej systematyczny monitoring – zarówno pojedyncze infekcje, jak i całościowy obraz sytuacji jest znany zespołowi obsługi incydentów, a zespół posiada wystarczające informacje i środki, aby sprawnie reagować.
4. Poznaj swój system oraz swojego przeciwnika. Jeżeli atakujący będzie znał Twój system lepiej, będzie miał nad tobą przewagę.
Powyższa lista nie wyczerpuje tematu. Poniżej krótki przykład scenariuszy ataku i zabezpieczeń dla hipotetycznej sytuacji – ransomware w dziale kadr, który w arkuszach kalkulacyjnych na zasobie sieciowym przechowuje listę płac.
Wykaz jest celowo niepełny, aby zachęcić czytelnika do przeprowadzenia pilotażowego modelowania (w nawiasach wymieniono po kilka przykładowych zabezpieczeń).
1. Przyczyny wystąpienia (i możliwe zabezpieczenia) – infekcja stacji roboczej w wyniku:
- otwarcia pliku w załączniku e-maila (okresowa edukacja pracowników w zakresie phishingu, niebezpiecznych/podejrzanych wiadomości e-mail, AV na bramce pocztowej, wyłączenie możliwości odbierania załączników spoza zdefiniowanej listy bezpiecznych rozszerzeń, wyłączenie wykonywania makr w programach do obsługi dokumentów, …);
- kliknięcia na link w treści e-mail, pobranie pliku wykonywalnego (zablokowanie dostępu do Internetu dla niektórych stacji, sprawdzanie przez AV linków przychodzących w mailu, …);
- wykonania kodu w wyniku wykorzystania podatności w przeglądarce internetowej/programie pocztowym (…);
- …
2. Wykonanie kodu na stacji pracownika
- z katalogu tymczasowego (ograniczenie uruchamiania aplikacji do konkretnych katalogów, ograniczenie wykonywania konkretnych typów plików, …);
- uruchomiono nieznaną aplikację (wymuszana białą listą oprogramowania wcześniej zatwierdzanego, monitoring i blokowanie uruchomienia oprogramowania spoza listy, …);
- …
3. niedostępność plików/zasobów
- · …
Wstępne zestawienie propozycji zabezpieczeń utworzone z listy powyżej i wygenerowane bez narzucania ograniczeń racjonalizuje się i uzupełnia o priorytety, następnie wybiera się, które i kiedy będą realizowane.
Dodatkowym plusem systematycznego planowania jest to, że gdy w przyszłości pojawi się nowe zagrożenie (kiedyś mogło nie być ransomware, mogło nie być problemem lub nikt o nim nie pomyślał) nie trzeba zaczynać całego procesu od nowa.
3. Wskaźniki kompromitacji (IOC)
Wróćmy do przykładu złośliwego oprogramowania. W trakcie analizy pliku binarnego natrafiliśmy na kilka szczególnych cech jego obecności. Postaramy się teraz wykorzystać je w celu wykrycia innych zarażonych stacji oraz powstrzymania infekcji.
W zależności od rodzaju, cechy te (nazywane IOC – Indicator Of Compromise), możemy podzielić na:
- objawy widoczne dla użytkownika (np. charakterystyczna wiadomość e-mail),
- specyficzne dla systemu operacyjnego (od sum MD5 plików zawierających malware przez ścieżki, w których się znajdują, klucze rejestru i ustawienia OS),
- charakteryzujące ruch sieciowy (adresy IP, nazwy domen, anomalie w wykorzystaniu protokołów),
- globalne IOC (wykonywane przez atakujących czynności operacyjne, jak np. wykorzystanie PTH lub innych specyficznych ataków, tworzenie użytkowników systemowych itp.).
IOC możemy również podzielić ze względu na czas życia (rysunek poniżej) – w zależności od tego, jak mocno atakujący przywiązani są do danej cechy. Na dole skali, z bardzo krótkim czasem życia, znajdują się sumy MD5 plików – z uwagi na to, że wystarczy drobna zmiana w pliku i hash będzie różny od oryginału. Nie od dziś możemy obserwować pliki generowane praktycznie per wysłany e-mail w celu uniknięcia wykrycia przez systemy AV.
Dłuższy czas życia (czasami liczony w godzinach lub dniach) mają adresy IP i stałe nazwy domenowe.
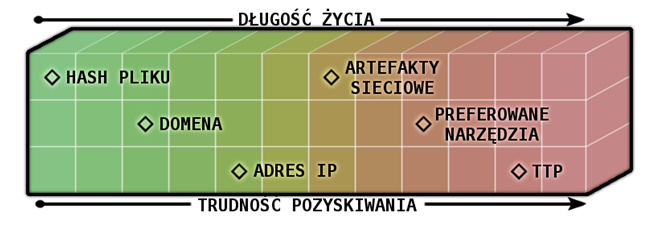
Rys. 1. Spodziewany czas życia cech charakterystycznych dla ataków.
Tu na szczególną uwagę zasługują algorytmy generowania nazw domen, do których łączy się malware – DGA (Domain Generation Algorithm). Ponieważ w niedawnej historii zapisane na stałe nazwy domen stały się pojedynczym punktem awarii botnetów – wystarczyło je sinkhole’ować (np. operacja przeprowadzona przez CERT Polska). Część rodzin złośliwego oprogramowania generuje i sprawdza w krótkim czasie ich duże ilości, aby w końcu trafić na tą jedną, zarejestrowaną przez operatorów i z niej czerpać konfigurację. W momencie zamknięcia domeny, powtarzają proces ponownego wyszukiwania. Autorzy malware, znając algorytm generowania domen, mogą z wyprzedzeniem wykupić te, które zostaną odwiedzone w przyszłości.
Przykłady domen wygenerowanych przez DGA, zależne od aktualnego czasu (Conficker):
- fupwo.cd
- rcilgcgk.co.uk
- wwwlmy.com.hn
- zxszv.com.ar
- zfmflv.tc
- jttbrq.co.id
- lfjxj.co.kr
List. 1. Przykładowe domeny wygenerowane za pomocą DGA.
Najdłużej żyjące, a tym samym najcenniejsze z punktu widzenia obrony, są IOC opisujące wszelkie „działania operacyjne”. Czasami jest to błąd popełniony przez osoby piszące malware (próba logowania na nietypowe, nieistniejące konto domenowe), przywiązanie do konkretnej techniki ataku czy narzędzia. Cechy te, poza tym że pozwalają identyfikować nawet kolejne generacje tego samego zagrożenia – identyfikują z dużym prawdopodobieństwem samych atakujących.

Rys. 2. Działanie mechanizmu generowania domen – DGA.
4. Jak i gdzie szukamy symptomów infekcji
Dobre dowody wystąpienia infekcji to takie, które z bardzo dużym prawdopodobieństwem wystąpią w trakcie ataku (najlepiej zawsze), ale jednocześnie jest znikome prawdopodobieństwo ich samoistnego pojawienia się. Autorzy malware często dodają również „zaciemniacze”, aby utrudnić budowę dobrych sygnatur. Złośliwy plik wykonuje na przykład żądania do dobrych, popularnych stron, które w przypadku stworzenia sygnatury lub zablokowania, wygenerują wiele fałszywych pozytywów (np. http://www.google.com, lub niedawne http://z3s.pl – https://zaufanatrzeciastrona.pl/post/pozdrowienia-od-thomasa-czyli-nowy-zlosnik-ktory-odwiedza-z3s-pl/).
Podstawowe narzędzia
Wiele narzędzi, które wykorzystamy, jest zapewne doskonale znana administratorom. W zależności od środowiska, w którym przyszło nam pracować, będzie to wspomniany już wcześniej szeroko rozumiany shell, czy to w postaci oprogramowania GNU w przypadku Linuksów, czy też PowerShell, dla tych których sercu bliższy jest Windows.
Natomiast środowisko biurowe oparte prawie w całości o system Windows wcale nie oznacza, że osoby lepiej czujące się w otwartym odpowiedniku nie mają tam czego szukać – wręcz przeciwnie.
1. Serwer Logów
Początek przygody zaczyna się właśnie na serwerze logów – maszynie, na którą spływają logi z różnych systemów. Postawienie takiej maszyny jest bardzo proste. W dużym skrócie – wymaga zainstalowania oprogramowania zbierającego przychodzące do niego logi, zapisującego je na dysku i finalnie, co jakiś czas, rotującego je (usuwającego starsze dane).
Do tego celu wykorzystamy poniższe, darmowe oprogramowanie:
- system operacyjny Linux,
- oprogramowanie będące serwerem syslog – protokołu zaprojektowanego do przesyłania logów (np. syslog-ng),
- automat do organizacji plików z logami – zmieniania nazw na dane dla konkretnego dnia, kompresowania danych i usuwania ich po zadanym okresie.
Konfiguracja sprowadza się w swojej najprostszej wersji do zdefiniowania w plikach konfiguracyjnych następujących elementów:
1.Syslog-ng:
source s_net { udp( ip(0.0.0.0) port(514) ); };
destination d_router_allow { file("/var/log/router_allow.log"); };
filter f_host_router { host("10.0.0.10"); };
filter f_router_allow { match("ALLOW:" value("MESSAGE")) };
log { source(s_net); filter(f_host_router); filter(f_router_allow); destination(d_router_allow); };
Pierwsza linijka – „source” mówi o nasłuchiwaniu na porcie UDP 514 przychodzących danych.
Druga linijka – „destination” wskazuje, gdzie mają być zapisane logi.
Trzecia i czwarta linijka – „filter” wskazują, które dane mają być wyfiltrowane i finalnie trafić do pliku (tylko z danego adresu IP i zawierające frazę „ALLOW”).
Ostatnia linijka – „log” spina wszystkie te elementy w całość (ponieważ na tym samym porcie w zależności od ustawionych filtrów logi można zapisywać do różnych plików).
2.Logrotate:
/var/log/router_allow.log
{
rotate 90
create 660 root root
daily
missingok
compress
delaycompress
sharedscripts
postrotate
invoke-rc.d syslog-ng reload > /dev/null
endscript
}
Główne punkty to: rotowanie raz dziennie (daily), trzymane ostatnie 90 plików, po zrotowaniu wykonaj polecenie przeładowania serwera syslog-ng (tak, żeby mógł pisać do nowego pliku).
3.Teraz wystarczy ustawić w miejscu generowania logów przesyłanie na serwer logów na port UDP 514.
Logować warto przede wszystkim te zdarzenia, na podstawie których chcielibyśmy później móc wykrywać i wyjaśniać incydenty. Niska jakość samych logów znacząco utrudnia korelację zdarzeń, więc warto mieć to na uwadze.
Poniżej lista tylko niektórych źródeł danych zasilających serwer logów oraz przykład ich wykorzystania.
Logi pocztowe
Tu do dyspozycji będziemy mieli najprawdopodobniej jedynie adresy nadawcy i odbiorcy, adres zwrotny, tytuł wiadomości oraz kilka mniej istotnych informacji w kontekście malware. Należy oszacować przybliżony zakres poszukiwań (wystarczająco szeroki, aby nic nie umknęło naszej uwadze). Nawet duże ilości logów przeszukuje się szybko.
Moja propozycja to:
- Zapisanie do pliku „slowa_kluczowe.txt” wszystkich cech (po jednej linii) które znamy i chcieli byśmy wyszukać (np. nietypowy fragment nazwy wiadomości, egzotyczna domena, z której przyszedł SPAM).
@malicious-domain.com New pics for you Really importnant documents MalwareSales Report
- Przeszukanie narzędziem FGREP zadanego zakresu logów (tu do naszej decyzji zostaje, czy dodamy parametr „-i” i przeszukamy zasoby niezależnie od wielkości występujących znaków). W poniższym przykładzie – od wczoraj do 7 dni wstecz:
$ zfgrep -f slowa_kluczowe.txt /var/logs/poczta.{1..7}.gz > wynik.txt
- Przeglądamy wyniki i jeżeli pojawiają się jakieś nowe istotne cechy (np. wiadomości były wysyłane z większej liczby domen, ale miały taką samą nazwę, to dodajemy kolejne cechy do pliku i powtarzamy proces – plik wyjściowy zostanie nadpisany rozszerzonymi wynikami.
Gdy już mamy listę odbiorców niebezpiecznych wiadomości, warto powiadomić ich, by nie otwierali niebezpiecznej przesyłki i skontaktowali się z nami, jeżeli zostali zainfekowani.
Po obsłudze incydentu, dobrze znaleźć chwilę czasu na przygotowanie szablonu komunikacji na przyszłość, żeby nie tworzyć jej ponownie, oraz zautomatyzowanie części powyższego procesu. Dzięki prostemu skryptowi, powyższe kroki będą mogły być powtarzane np. raz dziennie bez naszego udziału, a jeśli w przyszłości przyjdzie niechciana poczta, będziemy o tym wiedzieli.
Należy też pamiętać, że logi (z tego bądź innego systemu) pomogą nam zazwyczaj w analizie tego, co już się stało i ew. dojścia do przyczyn. Nie powstrzymają jednak samego ataku.
Więcej na temat phishingu można znaleźć na sekuraku np. tutaj.
2. Firewall
W przypadku logów z FIREWALL do dyspozycji będziemy mieli zapewne wyłącznie adresy IP źródłowy, docelowy i ewentualnie port. Poza techniką przeszukiwania jak powyżej, warto jako quick-win zwrócić uwagę na dziwne porty oraz połączenia wychodzące w godzinach nocnych.
Przykładowo: dlaczego jedna z maszyn łączy się z zewnętrznym serwerem IRC lub przez całą noc pinguje serwer HTTP w kraju podwyższonego ryzyka (RU/CN/…)?
23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.50 service 22 s_port 1808 23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.51 service 22 s_port 4414 23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.52 service 22 s_port 1810 23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.53 service 22 s_port 1811 23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.54 service 22 s_port 1812 23:17:48 reject fw >qe0 proto tcp src 10.0.13.69 dst 10.0.13.55 service 22 s_port 1813
3. PROXY Internetowe oraz DNS dla ruchu wychodzącego
Organizacja ruchu sieciowego użytkowników przez PROXY ma wiele zalet. Jedną z nich jest możliwość inspekcji niechcianych połączeń oraz ich zablokowanie. Większość rozwiązań tego typu pozwala podpiąć różne blacklisty. O tym, czym można je wypełnić, dowiemy się więcej w rozdziale o Threat Intelligence w jednej z kolejnych części artykułu.
Tak jak w poprzednich dwóch przykładach, PROXY powinno umożliwiać zapisywanie oraz przeszukiwanie logów w formacie tekstowym. Tutaj znów nieoceniony okazuje się FGREP. Dodatkową, bezcenną umiejętnością jest opisywanie wzorców za pomocą wyrażeń regularnych. Malware często próbuje ukryć ruch pod postacią losowych fragmentów, które zazwyczaj daje się całkiem dobrze opisać za pomocą takich wyrażeń (jak w omawianym przez nas ostatnio malware). Trzeba mieć jednak na uwadze, że takie przeszukiwanie jest dużo bardziej czasochłonne niż poszukiwanie stałych ciągów tekstowych.
Dwie rzeczy, na które należy zwrócić uwagę podczas planowania wykorzystania PROXY, to:
- zdejmowanie SSL (poprzez podstawienie własnego certyfikatu, który trzeba zainstalować na stacjach) oraz
- brak kompletnych zapytań (zależnie od zastosowanego rozwiązania).
W wielu sytuacjach same URI będą wystarczające, ale autorzy malware coraz częściej starają się ukryć złośliwy ruch w HTTPS.
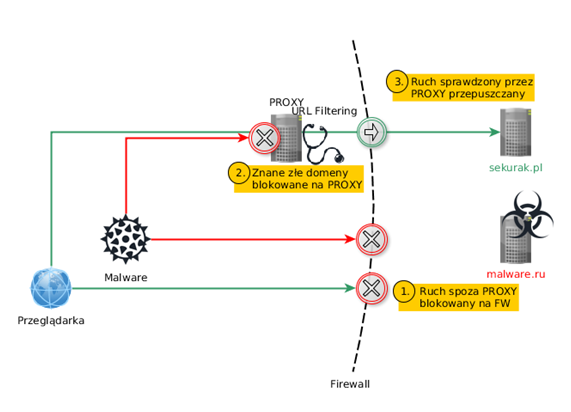
Rys. 3. Wykorzystanie PROXY do inspekcji ruchu wychodzącego.
Na rynku wskazano rozwiązania, które zgodnie z opisem mogą zostać zintegrowane z pocztą/proxy i pozwalają na analizowanie w środowisku sandbox plików docierających do użytkownika. Umożliwiają one również blokowanie ruchu na tej podstawie.
Nie proponuję, nie odradzam ani nie oceniam tutaj tych rozwiązań. Zostały zamieszczone dla kompletności, a czytelnicy, w których budżecie się one mieszczą, sami powinni rozważyć ich zastosowanie.
4. IDS/IPS – Snort
Snort jest darmowym, ale co ważniejsze – bardzo dobrym systemem IDS (Intrusion Detection System), który zainstalowany na jednej z maszyn nasłuchuje ruch sieciowy (poprzez sniffing). Pozwala na napisanie w prostym języku reguł, które, gdy zostaną wykryte, generują alarm wraz z otaczającymi je informacjami – w szczególności pakietem, w którym został wykryty, wraz z adresem źródłowym i docelowym.
Sygnaturowy tryb pracy oznacza też, że, aby takie rozwiązanie miało szansę zadziałać, samo zagrożenie musi być wcześniej znane i musi dla niego powstać odpowiednia sygnatura.
Tym razem wykorzystamy SNORT jako uzupełnienie ewentualnych ograniczeń w możliwościach monitoringu przez poszczególne narzędzia. Część z nich nie pozwala na logowanie lub działanie w oparciu o którąś z istotnych dla nas cech.
Reguły tworzy się w postaci wpisów tekstowych w pliku konfiguracyjnym. Wraz ze standardową instalacją dostarczany jest pokaźny zbiór sygnatur na znane ataki. Z uwagi na swój otwarty i edytowalny charakter są one doskonałym źródłem do nauki zarówno o tym, jak wyglądają ataki na niektóre podatności, ale także – jak budować własne sygnatury.
W pewnych sytuacjach może się okazać, że mechanizm PROXY nie daje nam wystarczającej elastyczności do skutecznego wykrywania ataków (lub w ogóle nie mamy dostępu do PROXY). Jednym z rozwiązań w tej sytuacji może być wykorzystanie SNORT w celu inspekcji ruchu wychodzącego.
Poniższa reguła wykryje wszystkie żądania HTTP wykonywane z naszej sieci (w zmiennej HOME_NET) na jeden z domyślnych portów HTTP zewnętrznego serwera. Wymagamy w niej wyłączenie, żeby w URL pojawiła się fraza „/gate.php”.
alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS (msg:"Malware – Trojan Zeus URI"; flow:to_server, established; content:"/gate.php"; fast_pattern:only; http_uri; classtype:test; sid:1000001; rev:1;)
Kolejna przykładowa reguła, znajdzie wszystkie żądania, w których nagłówek „User-Agent” zawierał będzie słowo „Mazilla” (np. Mazilla/5.0). Znaki „|3A 20|” to odpowiedniki dwukropka i spacji.
alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS (msg:"Malware – Trojan Upatre UA"; flow:to_server, established; content:"User-Agent|3A 20|Mazilla"; fast_pattern:only; http_header; classtype:test; sid:1000002; rev:1;)
Powyższe reguły mogą wydawać się sztucznie proste, ale są to praktyczne przykłady wykrywania niektórych wersji złośliwego oprogramowania. Przyjrzyjmy się zatem kilku otwartym i bardziej zaawansowanym regułom z projektu EmergingThreats:
#by pedro marinho # alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"ET MALWARE AskSearch Spyware User-Agent (AskSearchAssistant)"; flow:to_server,established; content:"AskSearch"; http_header; fast_pattern:only; pcre:"/User-Agent\x3a[^\n]+AskSearch/iH"; threshold:type limit, count 2, seconds 360, track by_src; reference:url,doc.emergingthreats.net/2003493; classtype:trojan-activity; sid:2003493; rev:10;)
W skrócie, wyszukuje on częste (powyżej 2 razy w ciągu 5 min.) pojawianie się frazy „AskSearch” w nagłówku User-Agent przeglądarki. Sygnatura pochodzi z pliku emerging-malware.rules.
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN W32/Upatre.Downloader Encoded Binary Download Request"; flow:established,to_server; content:"/mandoc/"; fast_pattern; http_uri; depth:8; content:".pdf"; distance:0; http_uri; content:"Accept|3A| text/*, application/*|0D 0A|User-Agent|3A 20|"; depth:43; http_header; reference:url,phishme.com/evolution-upatre-dyre/; classtype:trojan-activity; sid:2020294; rev:2;)
Powyższa reguła z pliku emerging-trojan.rules wyszukuje natomiast żądania do specyficznego katalogu „/mandoc/” i pliku „.pdf”. Jak widać, na podstawie dwóch powyższych przykładów, autorzy reguł powinni dbać zarówno o wydajność przeszukiwania (fast_pattern, distance, depth), jak i maksymalną redukcję przypadkowych dopasowań (szczegółowe kryteria dopasowania).
5. YARA
YARA jest narzędziem pozwalającym na opisanie reguł dopasowania do samych plików. Zazwyczaj służy ono do klasyfikacji zbiorów próbek (np. przy prowadzeniu badań), ale z powodzeniem wykorzystamy je do zweryfikowania, czy któryś z plików nie przypomina znanej nam próbki (trochę jak antywirus). W plikach sygnatur opisujemy zawartość pliku (ciągi znaków, danych binarnych) lub nawet jego zachowanie (co robi).
 Podczas wyboru cech powinniśmy kierować się ich unikalnością (powinien zawierać je wyłącznie malware – nie chcemy, aby inne pliki były błędnie wykrywane) oraz niezmiennością (wykrywanie niezależnie od drobnych różnic i zmian w pliku). Przykładowo możemy się posłużyć unikalnymi ciągami znakowymi w pliku (strings), fragmentami dołączonych zasobów/obrazków (w naszym przypadku ikona) lub fragmentami odpowiedzialnymi za specyficzne funkcje w pliku (to niestety wymagałoby głębszej analizy statycznej).
Podczas wyboru cech powinniśmy kierować się ich unikalnością (powinien zawierać je wyłącznie malware – nie chcemy, aby inne pliki były błędnie wykrywane) oraz niezmiennością (wykrywanie niezależnie od drobnych różnic i zmian w pliku). Przykładowo możemy się posłużyć unikalnymi ciągami znakowymi w pliku (strings), fragmentami dołączonych zasobów/obrazków (w naszym przypadku ikona) lub fragmentami odpowiedzialnymi za specyficzne funkcje w pliku (to niestety wymagałoby głębszej analizy statycznej).
W analizowanym przeze mnie pliku nie ma charakterystycznych ciągów znakowych (np. niepowtarzalne ścieżki do plików), więc wykorzystam inną cechę. Do wydobycia zasobów z pliku możemy posłużyć się narzędziem Resource Hacker, który następnie otwieramy w hex edytorze i znajdujemy niewielki ciąg (najlepiej z jak najbardziej różnorodnych bajtów z okolic środka pliku).
Tworzymy nową sygnaturę w języku rozumianym przez Yara. Zależy nam na wykryciu wszystkich plików, które zawierają poniższy ciąg bajtów (ciąg w hex to bajty wyciągnięte z ikony):
rule PodejrzanaIkona {
meta:
description = „Podejrzana ikona zachecajaca do otwarcia (PDF)”
in_the_wild = true
strings:
$ikona = { fc ff 7a 7a fd ff f6 f6 fb ff f6 f6 fb ff c6 c6
ff ff 70 70 f9 ff f5 f5 fb ff f5 f5 fb ff 97 97 }
condition:
$ikona
}
Teraz wystarczy użyć Yara na podejrzanych przez nas plikach (np. wszystkie pliki .EXE w katalogach, w których zapisuje złośliwe oprogramowanie):
$ yara malware.rule C:\Documents and Settings\Administrator\Application Data\Microsoft\*.exe
W wyniku powinniśmy otrzymać listę plików, które pasują do sygnatury.
Kolejny przykład został skopiowany wprost z dokumentacji. Sprawdza on EntryPoint pliku – zarówno PE (Windows), jak i ELF (Linux). Entry Point jest adresem pamięci, od którego program zostanie uruchomiony po załadowaniu go przez loader. Adres ten nie był ustawiany arbitralnie i był swoistą sygnaturą dla różnych programów. Przy tym rzadko był zmieniany w polimorficznych programach, przez co historycznie wykorzystywano go do wykrywania zagrożeń:
rule EntryPointExample1 {
strings:
$a = { E8 00 00 00 00 }
condition:
$a at entrypoint
}
Bardziej zaawansowane reguły mogą bazować np. na warunkach logicznych (AND, OR), adresach startu (EntryPoint) aplikacji czy zewnętrznych modułach jak np.:
- Yextend do obsługi skompresowanych archiwów,
- Cukoo do opisywania zachowania pliku w środowisku sandbox,
- Math pozwalający np. sprawdzić entropię pliku.
O tym, czym jest entropia pliku oraz o sposobach pakowania plików (a dla dociekliwych nawet zbudowanie własnego packera), można poczytać po polsku na inspirującym blogu Gynvaela.
6. SSDeep
W wielu przypadkach wykorzystuje się sumy kryptograficzne do identyfikacji plików (MD5, SHA1, SHA256). Sumy kryptograficzne stworzone zostały jednak w innym celu – dla najdrobniejszych nawet różnic w pliku, wynikowy hash powinien różnić się jak najbardziej. Atakujący skrzętnie wykorzystują tą własność w celu tworzenia trudno wykrywalnego złośliwego oprogramowania.
W celu pokonania tego wyzwania, środowisko analityków malware zaadoptowało rozwiązanie stosowane podczas wykrywania SPAM-u. SSDeep jest programem (dostępnym również pod Linuxem), który wylicza sumy rozmyte w oparciu o bloki, a nie całą zawartość pliku. Pozwala to na identyfikację plików podobnych oraz określenie stopnia ich podobieństwa. Pomimo kilku wad (rozmiar bloku jest uzależniony od rozmiaru pliku), nadaje się znacznie lepiej do identyfikacji plików, a jego zastosowanie bynajmniej nie kończy się na plikach binarnych (np. pozwala znaleźć podobne pliki konfiguracyjne, które w swojej naturze mają drobne zmiany i różnice).
Użycie narzędzia jest stosunkowo proste. Zakładając, że mamy dwa różne pliki:
Nazwa pliku
(ignorowana) Suma MD5 Opis
INV 53.PDF.exe 0aecb730b8c1a06534cf393f5c0f01fd Oryginalna próbka
INV 53.PDF-2.exe 8ad731ed6ffff178f5c50d8233ed499 Zmodyfikowany plik
Wyliczamy rozmyty skrót oryginalnego pliku i zapisujemy do pliku np. malware.ssdeep:
$ ssdeep INV\ 53.PDF.exe ssdeep,1.1--blocksize:hash:hash,filename 3072:5m4nfbQCJmrAfYmpwoJgX7wlBxo7lx+ylpT5lPDZ6ECXtYxASewHjZD86JOlI0de:7J+gaoJgX8y7yyl5ZEyM0up3wR9,"INV 53.PDF.exe"
Następnie sprawdzamy, czy zmodyfikowany plik pasuje do hash (w tym wypadku w 99%):
$ ssdeep -m malware.ssdeep INV\ 53.PDF-2.exe INV 53.PDF-2.exe matches malware.ssdeep:INV 53.PDF.exe (99)

Rys. 4. Wynik porównania kolejnych bloków plików.
Wystarczy zatem dopasować wszystkie podejrzane pliki do hasha oryginalnego pliku, a w wyniku otrzymamy stopień ich podobieństwa.
Rysunek 4 przedstawia graficznie porównanie dwóch plików, podobnie jak wykonałby to SSdeep. W praktyce stosowana jest tam metoda „przesuwnego okna” i obejmuje inną ilość bajtów – rysunek obrazuje wyłącznie samą koncepcję.
7. Profesjonalne narzędzia antywirusowe
Pod tym terminem kryją się produkty mniej lub bardziej rozpoznawalnych marek. W przypadku wyboru warto natomiast zastanowić się nad przygotowaniem formalnej ewaluacji tych rozwiązań, jeżeli mamy taką możliwość. Warto tu dodatkowo podeprzeć się doświadczeniami innych zespołów.
Należy jednak pamiętać przed czym chronią takie rozwiązania. Ponieważ są to narzędzia sygnaturowe, nie rzadko aktualizowane raz dziennie – wykrywają prawie wyłącznie znane już wcześniej i popularne zagrożenia.
Autorzy malware, jak i ich klienci, doskonale zdają sobie sprawę ze słabości tych systemów. W powszechnym użyciu są zarówno packery zaciemniające i utrudniające wykrycie, jak i mechanizmy utrudniające automatyczną oraz heurystyczną analizę takich zagrożeń. Kolejną z powszechnie używanych metod jest okresowe badanie przez nie odmian za pomocą różnych programów antywirusowych i dalsze modyfikowanie kodu w przypadku przekroczenia zdefiniowanego progu wykrywalności. W połączeniu z generowaniem bardzo dużej – z punktu widzenia AV – ilości odmian, dochodzącej czasami do rzędu jednej odmiany per infekowany klient, jego identyfikacja w ten sposób jest znacząco utrudniona.
Biorąc pod uwagę umiarkowaną skuteczność rozwiązań AV, celowe zaciemnianie kodu czy w końcu brak możliwości wykrycia ataków dedykowanych – czy warto zrezygnować z użycia go jako kolejnej linii obrony?
Moim zdaniem, nie warto.
Po pierwsze, nie zawsze naszą bolączką będzie cieplutki i świeżutki jeszcze malware. Zarówno Internet, jak i środowiska mniej doświadczonych atakujących przesycone są odmianami dobrze już poznanymi i skutecznie wykrywanymi.
Po drugie, pozwalają one przesunąć przynajmniej częściowo – ciężar defensywy na twórców oprogramowania AV, przez których środowiska i zespoły przechodzi ogromna ilość próbek.
Finalnie, jest to kolejna linia obrony i jeżeli wszystkie inne zawiodą, ta daje dodatkową szansę na identyfikację zagrożenia.
Niektórzy producenci AV dają też możliwość przesłania im próbki, a w przypadku wykupionego „wsparcia” mogą również przygotować odpowiednie szczepionki lub sygnatury. Z doświadczenia autora wynika jednak, iż w takim modelu czas odpowiedzi jest stosunkowo długi, jak i znikome są sukcesy w przypadku trwającej kampanii. Niemniej, firmy antywirusowe po części opierają swoje sukcesy właśnie na próbkach przekazywanych przez klientów (zarówno automatycznymi, jak i ręcznymi metodami), więc warto, żeby byli dobrze poinformowani.
8. Rozwiązania „Threat Intelligence”
Na rynku pojawia się również coraz więcej rozwiązań mających na celu ustrzeżenie nas przed tego typu atakami (a przynajmniej tak reklamowanych). W zależności od produktu, łączą one niektóre z powyższych rozwiązań (np. AV, Sandbox, Web Proxy i Spam Filtering) z opisem (zazwyczaj również w formie sygnatur) dostarczanych przez dostawcę rozwiązania.
Na ocenę praktyczną tych rozwiązań w rzeczywistych warunkach pewnie będziemy musieli jeszcze trochę poczekać. Niewątpliwie, wraz ze wzrostem ich popularności, rynek złośliwego oprogramowania będzie starał się omijać takie zabezpieczenia.
Należy też przed ewentualnym zakupem mieć świadomość ich ograniczeń. I tak, słabym punktem systemów sygnaturowych jest konieczność posiadania wcześniej opracowanych i dopasowanych sygnatur.
9. Sysinternal Tools
Jako nieocenione wsparcie przy analizie nieznanych procesów mogą służyć dwa kolejne narzędzia z darmowego pakietu Sysinternal, wspomnianego w ostatniej części artykułu.
10. Process Explorer
Możliwości tego narzędzia nie kończą się bynajmniej na listowaniu aktywnych procesów. Daje on możliwość dodania kolumn, w których pojawią się takie informacje, jak to, czy plik został podpisany cyfrowo i czy ten certyfikat jest prawidłowy (Verified Signer), oraz to, czy hash pliku jest znany w serwisie VirusTotal (i jeżeli tak, to przez ile antywirusów został uznany za zagrożenie). Poza dodaniem odpowiednich kolumn należy jeszcze włączyć właściwe opcje w menu „Options” (zaznaczone na screenshot), przy czym wymagają one aktywnego połączenia z Internetem.
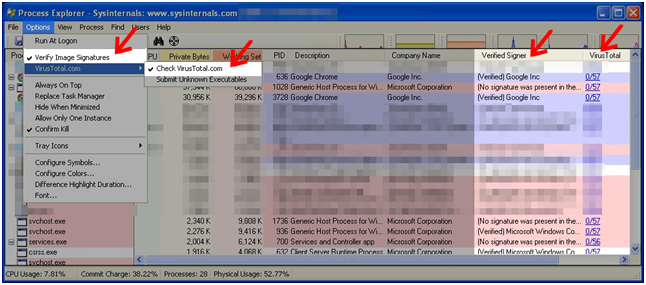
Rys. 5. Weryfikacja sygnatur oraz hashy plików w Process Explorer.
Dodatkowo informacja o tym, czy plik binarny jest spakowany, jest zakodowana w kolorze procesu (fioletowy). Jeśli proces jest usługą (service), ma kolor różowy. Procesy spakowane powinny podnieść nasz poziom podejrzliwości, ale nie oznaczają automatycznie, że plik jest złośliwy.
Inną przewagą, którą daje Process Explorer nad standardowymi narzędziami, jest możliwość zatrzymania procesu (bez jego ubijania). Niektóre warianty złośliwego oprogramowania uruchamiają dodatkowe procesy – „pomocników”, którzy monitorują czy główny proces nie został zamknięty i uruchamiają go ponownie, nim administrator zdąży ręcznie je zamknąć. Zazwyczaj daje się go jednak zamknąć po wcześniejszym uśpieniu każdego z procesów z osobna.
Niektóre odmiany złośliwego oprogramowania próbują nawet wykrywać uruchomienie narzędzi z pakietu SysInternals. Warto spróbować wtedy zmienić nazwę pliku lub uruchomić go na innym wirtualnym pulpicie.
O tych oraz innych sztuczkach Process Explorer oraz AutoRuns można posłuchać od ich autora tutaj („Malware Hunting with Mark Russinovich and the Sysinternals Tools”).
11. AutoRuns
System Windows posiada niezliczoną wręcz ilość punktów automatycznego uruchamiania z systemem. Program AutoRuns posiada ich pokaźną bazę i pokazuje programy z nich uruchamiane. Dodatkowo pozwala również zastosować powyższe sztuczki i ukryć wszystkie pliki z poprawną sygnaturą należące do Microsoft lub gdy zostały wskazane jako niegroźne w serwisie VirusTotal.
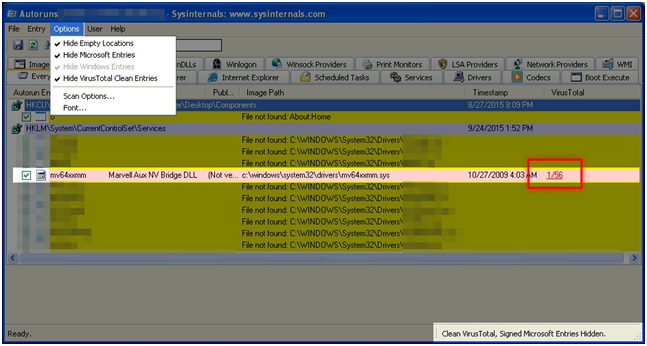
Rys. 6. Weryfikacja hashy plików w programie Autoruns.
Podsumowanie
Mimo iż w artykule opisanych zostało wiele narzędzi pozwalających przeprowadzić analizę ad-hoc, nic nie zastąpi odpowiedniego przygotowania. Obecnie przy ogromnej ilości zagrożeń przenoszonych codziennie w wiadomościach e-mail, nośnikach czy poprzez zainfekowane strony nie tylko analiza, ale i sprzątanie po każdej infekcji może być bardzo czasochłonnym zadaniem. Dlatego należy wypracować rozwiązania, które pozwolą automatycznie ograniczyć ilość incydentów oraz wesprą w ich analizie.
Równolegle z rozbudowywaniem kompetencji oraz zaplecza technicznego, warto rozważyć wdrożenie programu uświadamiającego, który okresowo będzie podnosił świadomość pracowników w zakresie najistotniejszych zagrożeń (nie tylko malware).
Mnogość scenariuszy infekcji, szybkość ewolucji złośliwego oprogramowania oraz jedna z najskuteczniejszych praktyk wypracowanych przez lata w bezpieczeństwie – defense in depth – podpowiadają, że dobrym pomysłem może być wzmocnienie obrony na całej linii, a nie tylko na stacjach użytkowników czy administratorów (ochrona bliżej chronionych zasobów). Finalnie, wykrycie infekcji oraz analiza malware staną się częścią większego procesu.
Kolejną część artykułu ponownie rozpocznę od tematów „ogólnorozwojowych”. Zaprezentuję także kilka narzędzi Microsoft, które możemy wykorzystać podczas budowania defensywy (EMET, AppLocker, GPO) oraz poruszę szerzej temat Threat Intelligence. Zobaczymy również mniej znanego, ale bardzo wszechstronnego „kuzyna” SNORT-a – BRO IDS „w akcji”.
–Aleksander Janusz

Jest szansa na wersje pdf?
Tak – w http://sekurak.pl/sekurak-offline/ za jakiś czas.
Dlaczego Kolega nie zrobi sobie z tego PDF’a? Zdaje się że nie jest większym problemem w dzisiejszych czasach. Pozdrowienia.
A można tak analizować system Windows wraz z bibliotekami?
To zależy o co dokładnie pytasz. Jeżeli o sprawdzenie bibliotek DDL załadowanych do pamięci jednego z procesów (np. explorer.exe, firefox.exe) to
wystarczy zaznaczyć [View] -> [Lower Pane View (CTRL+D)]. W panelu na dole będzie lista „normalnie” (API) załadowanych bibliotek wraz ze sprawdzonymi sygnaturami (DLL to prawie EXE) oraz wynikiem z VT (o ile te kolumny są włączone).
Jeżeli pytasz o dokładniejszą instrumentację bebechów systemu, to warto spojrzeć na całkiem niezły debuger od MS – windbg (https://msdn.microsoft.com/en-us/library/windows/hardware/ff553382(v=vs.85).aspx) i zestaw symboli lub możliwość debugowania zdalnie (ogólnie, dobrym pomysłem jest nie wstrzymywanie systemu na którym się pracuje ;).
Bardzo ładnie wszystko opisane. Świetny artykuł. Tyle że Process Explorer którego używam od lat do różnych zadań to już chyba M$. Czy to tylko taki patronat? :D Pozdrowienia.
Wcześniej tylko „SysInternals”, obecnie „Windows SysInternals”.