Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Wtyczki MCP równie problematyczne co przeglądarki ze zintegrowanym AI – podatność PromptJacking
Najczęstsze, najgłośniejsze i najpopularniejsze podatności związane z generatywnym AI (a w szczególności z dużymi modelami językowymi) można podzielić ogólnie na dwie podgrupy (co oczywiście stanowi tylko wycinek powierzchni ataku). Pierwsze dotyczą tzw. bezpieczeństwa “miękkiego” i w skrócie polegają na atakowaniu modeli w taki sposób, aby “skłonić” je do pominięcia założonych zasad generowanych wypowiedzi (ang. guidelines) i doprowadzić do tzw. jailbreaka.
TLDR:
- Badacze z Koi odnaleźli trywialną podatność w reklamowanych przez Anthropica wtyczkach do Claude Desktop.
- Podatności te pozwalały na wstrzykniecie własnych poleceń do powłoki systemowej wykorzystywanej przez serwery MCP.
- Skutkiem przeprowadzenia ataku jest całkowite przejęcie podatnego hosta.
- Sytuacji nie łagodzi fakt, że atak może zostać przygotowany i przeprowadzony w trywialny sposób – atakujący z wyprzedzeniem umieszcza spreparowaną treść w Internecie. Jeśli agent AI na nią natrafi, to dojdzie do wykonania kodu.
- Podatność otrzymała nazwę – PromptJacking
O tego typu atakach można myśleć jak o phishingu robotycznego rozmówcy i chociaż często są to wyszukane ataki, to jednak nie wymagają skomplikowanych umiejętności technicznych. Drugi rodzaj ataków skupia się na samych modelach i wykorzystuje np. budowę tychże np. w celu zatrucia modelu (tutaj przykładem może być R.O.M.E lub Concept-ROT). Jednak prawdziwą puszkę pandory otwierają wszelakie integracje zewnętrznych systemów i źródeł danych. W momencie rozszerzenia możliwości modelu i stworzenie tzw. agenta, pojawić się mogą kolejne podatności, które wynikają z samej koncepcji tego typu rozwiązań i są wręcz systemowe. A to oznacza jedno – nie ma jednego, dobrego rozwiązania, które pozwoliłoby podnieść w sposób znaczny bezpieczeństwo. Przytaczane w niniejszym artykule podatności nie są jednak skomplikowane. Mamy wrażenie, że boom na AI powoduje, że wracamy do podatności, które powinny przestać istnieć 30 lat temu.
W mailach i listach od Was, często otrzymujemy pytania o zintegrowane z LLMami przelgądarki – takie jak Atlas czy Comet. Prowadzone badania pokazują, jak łatwo jest wykorzystać atak typu indirect prompt injection na tego typu oprogramowaniu. Jest to szalenie niebezpieczny wektor, ponieważ łączy dwa kluczowe elementy osobistych asystentów – podatność na wstrzykiwanie promptów i łatwość w obchodzeniu wewnętrznych zasad bezpieczeństwa. Dodatkowym czynnikiem jest brak skutecznych ograniczeń i bezpośrednia integracja z systemem. Integracja ta, może być realizowana na wiele sposobów. Jednym z nich jest MCP (Model Context Protocol), rozwiązanie, które nieraz pojawiało się na łamach Sekuraka i pewnie jeszcze nieraz tu zagości. Wynika to z faktu, że koncepcja MCP nie zakłada żadnych mechanizmów bezpieczeństwa. Dając możliwość swobodnego wywoływania narzędzi przez podatny na “sugestie” model, łatwo jest paść ofiarą trywialnego ataku. A ponieważ model uzyskuje możliwość realnej interakcji z systemem, to w efekcie, może dojść do całkowitego przejęcia wykorzystywanego systemu.
Badacze z KOI pod lupę wzięli trzy popularne wtyczki Claude Desktop, czyli środowiska osobistego asystenta od Anthropica. Rozszerzenia te to tak naprawdę serwery MCP opakowane w bardzo prostą integrację ze środowiskiem. Użytkownik może zdecydować, tak samo jak w “sklepie” z rozszerzeniami np. przeglądarki, jakie dodatkowe funkcje chce wprowadzić do swojego asystenta. Przy pomocy kilku kliknięć, możliwości modelu językowego mogą zostać poszerzone o wsparcie zewnętrznych źródeł danych, możliwość kontroli przeglądarki czy komunikatora.
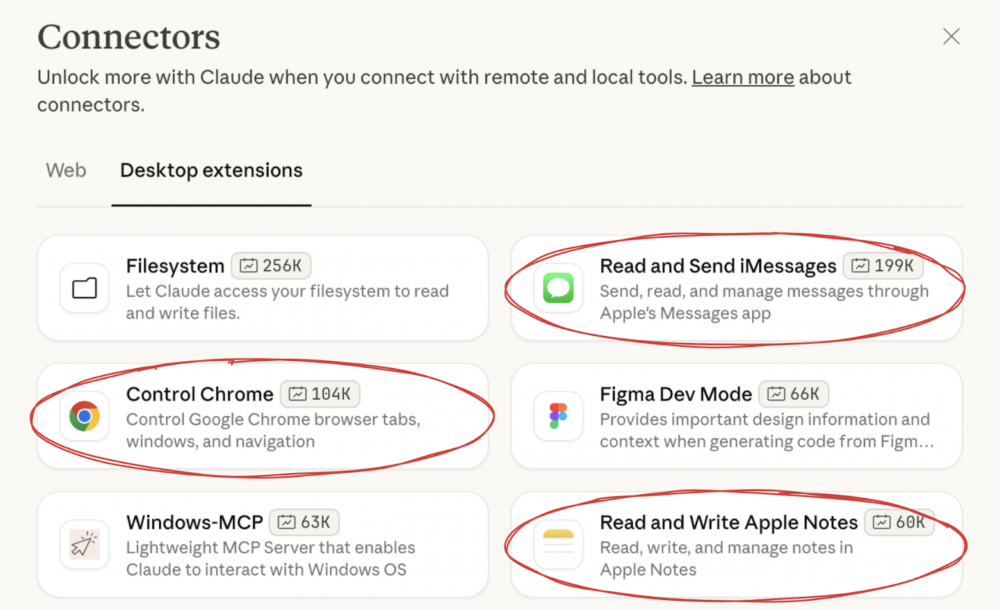
Jednak w odróżnieniu od ekosystemu przeglądarek, w których duży nacisk kładzie się na separację procesów oraz ich ograniczenie np. z wykorzystaniem mechanizmu piaskownic, Claude Desktop nie ogranicza uprawnień zainstalowanych dodatków. To z kolei bardzo obniża trudność ataku na system, który uruchamia tego asystenta. I oczywiście można się spierać, czy jest to wymaganie strukturalne, wymuszone przez przeznaczenie takich dodatków (naszym zdaniem nie zawsze), czy niedopatrzenie programistów w konkretnych przypadkach. Prawdziwy obraz i skalę problemu można dostrzec zapoznając się z odkrytymi błędami. Jak wspominaliśmy na wstępie, lata 90 dzwoniły i prosiły, żeby oddać im ich podatności.
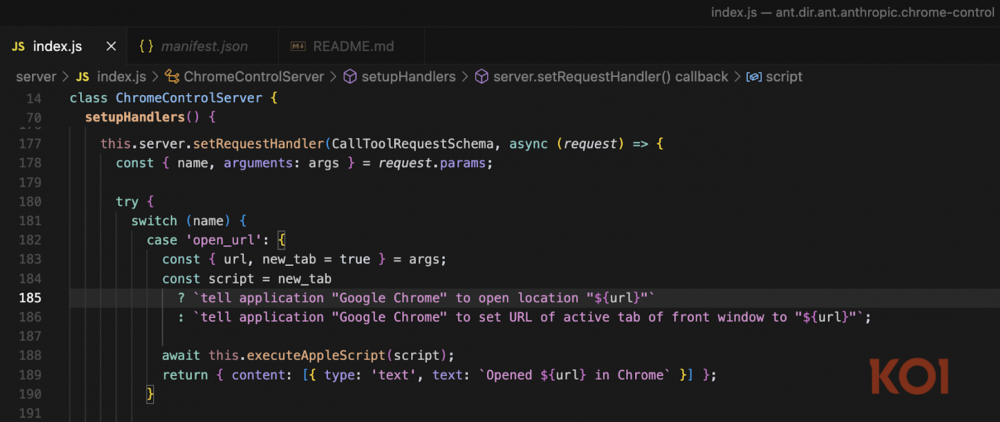
Zaprezentowany na listingu fragment kodu odpowiada za uruchomienie przeglądarki Chrome i odwiedzenie konkretnego adresu URL. Brak filtrowania powoduje, że złośliwie spreparowany URL, będzie zawierał wstrzyknięcie polecenia, które – ze względu na konieczność wywołania przeglądarki wraz z adresem – zostanie wykonane przez serwer MCP.
W tej chwili, część czytelników zauważy, że przecież to podatność równie pociągająca co self-XSS. W teorii to może i nawet da się to wykorzystać, ale w praktyce niewiele jest sensownych zastosowań. Jest to stwierdzenie słuszne, jednak nie bierze pod uwagę ważnego aspektu działania agentów AI czyli czegoś na kształt pętli zwrotnej. Otóż dane wejściowe do agenta, nie muszą trafiać bezpośrednio od użytkownika. Claude Desktop wykorzystujący integrację np. z przeglądarką, będzie przetwarzał też źródła stron WWW. A to otwiera już ciekawe metody ataku oparte o tzw. drive-by. Tym samym atakujący tworząc stronę (lub zamieszczając złośliwą treść na znanym portalu), pozostawia pułapkę, w którą agenty AI wpadną za jakiś czas. Schemat proponowanego ataku został przedstawiony na rysunku 3.
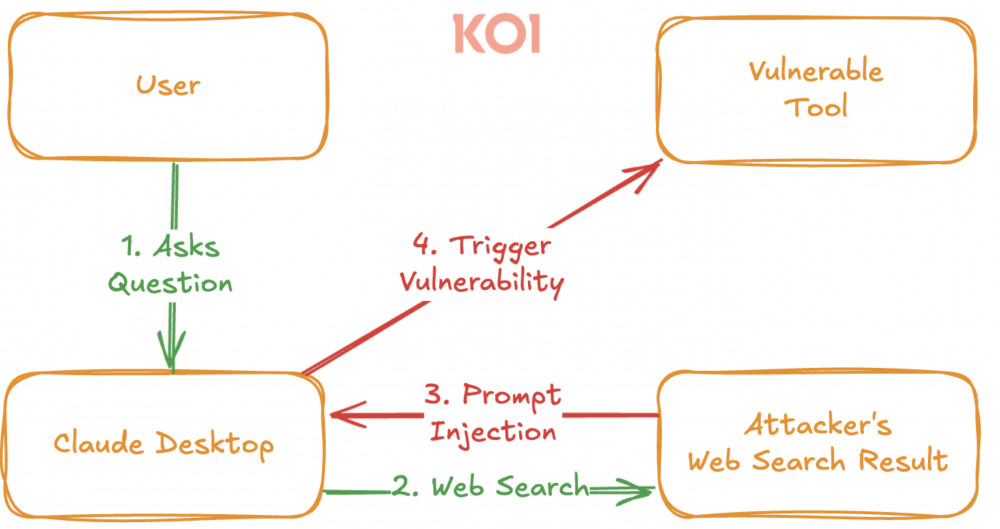
Tym samym atakujący wykorzystuje największe słabości, w tym jedną, dotyczącą tzw. miękkiego bezpieczeństwa, wynikającą wprost z metody działania dużych modeli językowych, a do tego bardzo trudną do stuprocentowego wyeliminowania.
Badacze słusznie zauważyli, że w przypadku command injection, skuteczne wykonanie ataku będzie równoznaczne z pełnym przejęciem systemu, a to oznacza, że łupem atakujących paść mogą również dane znajdujące się na hostach, w tym klucze API (również te pozwalające na wykorzystanie modeli AI w chmurze), ciastka i tokeny sesyjne (w tym przypadku 2FA na niewiele się zda) oraz same zasoby obliczeniowe, które mogą zostać wykorzystane np. do kopania kryptowalut.
Reasumując, przedstawione podatności, chociaż wynikają z bardzo prostych przeoczeń, pokazują kluczowy problem z bezpieczeństwem agentów AI: oprócz filtrowania (które nie zawsze musi być skuteczne) danych trafiających do MCP, za bezpieczeństwo wykonania odpowiada podatny na manipulacje model LLM. A to powoduje, że twórcy takich rozwiązań mają ciężki orzech do zgryzienia i nietrywialny problem do rozwiązania. A my jako użytkownicy nie mamy łatwiej. Zwłaszcza w perspektywie szybkiego dostarczania wielu niedokończonych projektów MCP, które nie przeszły audytu bezpieczeństwa. Sytuacji nie poprawia fakt, że pewnie część trafiających na rynek rozszerzeń została zvibecodowana. Ułamek z nich przeszedł pewnie jakiś audyt. Pytanie czy on też nie został “przeprowadzony” przez AI.
Jak żyć? Na ten moment dobrym pomysłem jest przede wszystkim uruchomienie tego typu rozwiązań na wydzielonych systemach, które nie zawierają krytycznych danych. Ciągły monitoring zarówno hostów jak i ruchu sieciowego oraz zużycia API.
~Black Hat Logan
