Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Ukryte katalogi i pliki jako źródło informacji o aplikacjach internetowych
Ukryte katalogi oraz pliki pozostawione przez nieuwagę na serwerze WWW, mogą stać się nieocenionym źródłem informacji podczas testu penetracyjnego. W skrajnych sytuacjach, takich jak pozostawiony katalog .git lub .svn, pozwalają na dostęp do kodu źródłowego aplikacji, co w rezultacie skutkuje całkowitą kompromitacją i uzyskaniem nieautoryzowanego dostępu oraz możliwością przeprowadzenia statycznej analizy kodu źródłowego i odkrycia wszystkich luk.
Wbrew pozorom, bardzo często można natknąć się na tego rodzaju zasoby. Poniższy artykuł na przykładzie kilku najpopularniejszych katalogów prezentuje praktyczne przykłady wykorzystania informacji w nich zawartych.
Systemy kontroli wersji
Git to jeden z powszechnie wykorzystywanych rozproszonych systemów kontroli wersji. Jego popularność dodatkowo zwiększają serwisy takie jak GitHub czy Bitbucket.
Podstawowe informacje o obiektach Gita
Wszystkie informacje na temat projektu pod kontrolą Gita znajdują się w folderze .git, w głównym katalogu. Jego przykładową strukturę przedstawia rysunek 1.
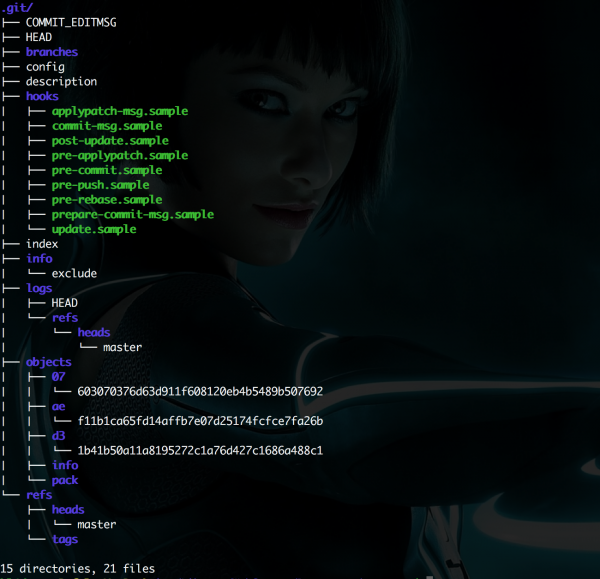
Rysunek 1. Zawartość przykładowego katalogu .git..git.
Przyjrzyjmy się zawartym w nim informacjom z punktu widzenia crackera. W folderze .git/objects znajdują się pliki zawierające wszystkie operacje dokonywane na repozytorium, a także zawartość wszystkich plików w takiej postaci, w jakiej znajdowały się w momencie dokonywania jakiejkolwiek zmiany, np. operacji commit. Nazwami obiektów są 40-znakowe skróty (hasze) SHA-1. Każdy obiekt może być jednym z trzech poniższych typów:
- commit – zawiera informacje na jego temat, takie jak: autor, komentarz oraz hasze obiektów aktualnego drzewa katalogów i plików projektu;
- tree – zawiera skrót (hasz) obiektu przechowującego strukturę plików i katalogów;
- blob – zawiera zawartość pliku zapisaną w postaci binarnej, możliwą do odczytania poleceniem git cat-file -p [hasz SHA1].
Jeżeli programista pozostawił na serwerze folder .git, nic nie stoi na przeszkodzie, aby odczytać zawartość dowolnego pliku, nawet jeśli nie mamy uprawnień do pobrania całego repozytorium poleceniem git clone git checkout.
Jak sprawdzić, czy folder .git znajduje się na serwerze?
Wystarczy sprawdzić, czy url w postaci np. http://adresserwisu/.git zwróci nam odpowiedź HTTP z kodem innym, niż 404 Not Found. Z reguły, konfiguracja serwera nie zezwala na listing zawartości katalogów, wobec czego otrzymujemy odpowiedź 403 Forbidden, co jednoznacznie wskazuje na to, że trafiliśmy na naszą „informacyjną żyłę złota”:
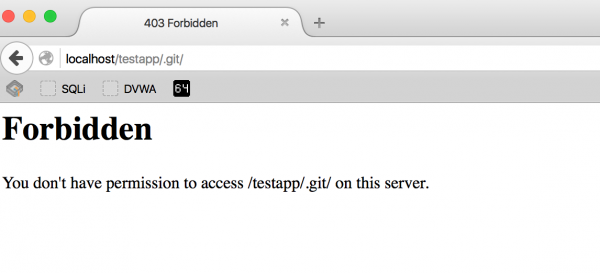
Rysunek 2. Odpowiedź HTTP 403 serwera wskazująca na obecność katalogu .git.
Wiemy, że .git znajduje się na serwerze, ale nie wiemy, jakie skróty SHA-1 identyfikują poszczególne obiekty. Jak uzyskać taką informację?
Cała historia operacji (dostępna po wykonaniu polecenia git log), zapisywana jest w pliku .git/logs/head. Jest to zwykły plik tekstowy, zawierający informacje o wszystkich commitach:

Rysunek 3. Zawartość pliku .git/logs/head.
Przyjrzyjmy się bliżej pierwszemu wpisowi w tym pliku:
0000000000000000000000000000000000000000 07603070376d63d911f608120eb4b5489b507692 bloorq@gmail.com <bloorq@gmail.com> 1452195279 +0000 commit (initial): index.php initial commit
Pierwsze dwa hasze to kolejno: poprzedni i aktualny commit. Ponieważ jest to wpis dotyczący pierwszego commita w tym repozytorium, pierwszy hasz to po prostu same zera.
Zanim zaczniemy pobierać obiekty Gita identyfikowane przez odnalezione hasze, dla ułatwienia stworzymy szkielet repozytorium Git. W tym celu, w konsoli należy wydać polecenie:
$ git init
Wynikiem będzie katalog .git zawierający szkielet repozytorium, w tym folder objects/, gdzie zapisywać będziemy pobrane obiekty. Najpierw musimy jednak odwzorować hasz obiektu na fizyczną ścieżkę w zdalnym repozytorium. Ścieżka składa się kolejno:
- ze stałego fragmentu – git/objects/,
- z dwuliterowej nazwy folderu, będącej dwoma pierwszymi znakami hasza obiektu,
- z nazwy pliku utworzonej z pozostałych 38 znaków hasza:
http:/localhost/testapp/.git/objects/07/603070376d63d911f608120eb4b5489b507692
Po otwarciu w przeglądarce powyższego adresu, powinniśmy ujrzeć okno dialogowe pobierania pliku:
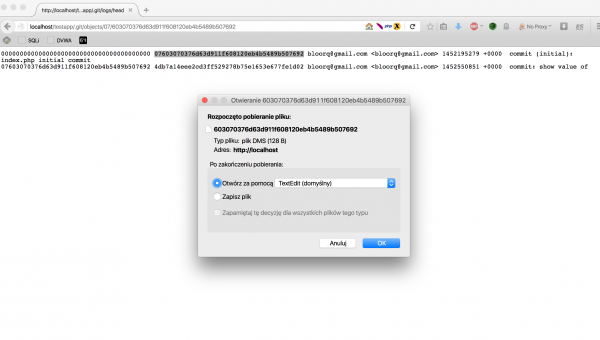
Rysunek 4. Okno dialogowe pobierania pliku w przeglądarce Firefox.
Plik zapisujemy w naszym tymczasowym repozytorium Git, zachowując prawidłową ścieżkę – w folderze .git/objects/07 – jako plik o nazwie 603070376d63d911f608120eb4b5489b507692. Aby móc odwoływać się do tego obiektu w poleceniach, musimy pamiętać o posługiwaniu się pełnym 40-znakowym haszem.
Typ obiektu możemy sprawdzić poleceniem git cat-file -t:
$ git cat-file -t 07603070376d63d911f608120eb4b5489b507692
Polecenie git cat-file -p pozwala na sprawdzenie zawartości obiektu:
$ git cat-file -p 07603070376d63d911f608120eb4b5489b507692
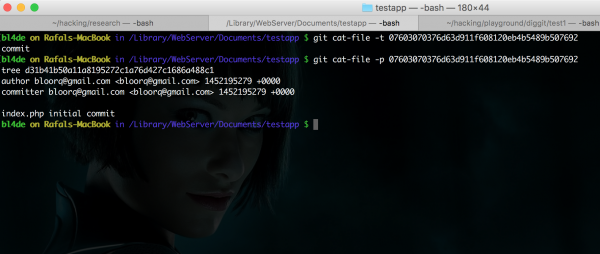
Rysunek 5. Wynik wykonania poleceń git cat-file w oknie konsoli.
Dokładna analiza treści commita pozwoli nam na uzyskanie kolejnej, istotnej informacji: jaki jest hasz reprezentujący drzewo katalogów i plików w repozytorium. Będzie to informacja dotycząca stanu, w jakim znajdowało się ono w momencie wykonania tego commita, a nie aktualnego stanu.
Przykład poniżej:

Rysunek 6. Hasz odpowiadający plikowi index.php w bieżącym drzewie katalogów i plików.
Jak widzimy, po pierwszym commicie w repozytorium znajdował się tylko jeden plik. Mamy również informację o haszu, jego typie (jest to blob, więc obiekt zapisany pod taką nazwą zawiera już dane – w tym wypadku będzie to kod źródłowy pliku index.php):
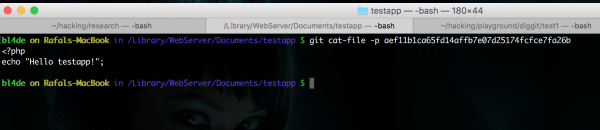
Rysunek 7. Kod źródłowy pliku index.php.
Bingo!
Jak wyżej wspomniałem, zawartość pliku index.php, jaką udało nam się odtworzyć, jest aktualna w momencie zatwierdzania pierwszego commita z odnalezionego repozytorium. Gdy przyjrzymy się plikowi logu, widzimy, że to nie był ostatni commit, i w kolejnym mogły nastąpić jakieś zmiany (w praktyce rzadko będzie nas interesowała zawartość starszych commitów – ostatni zawiera hasz aktualnego drzewa katalogów, które z kolei pozwoli nam uzyskać hasze aktualnych wersji plików).
Sprawdźmy więc, czy commit 4db7a14eee2cd3ff529278b75e1653e677fe1d02 zwróci nam inną zawartość pliku index.php. Postępując w dokładnie ten sam sposób, co wyżej (rysunki 1–6), ostatecznie uzyskujemy kod źródłowy wskazujący, że faktycznie aktualna zawartość pliku jest inna:
$ git cat-file -p a4215057b6545240452087ad4d015bf9b5b817c5 <?php echo "Hello testapp!"; $i = 100; echo "Value of i is $i";
Powyższy przykład prezentuje jedną z kilku dostępnych metod uzyskania dostępu do kodu źródłowego aplikacji webowej. Jednak niezależnie od metody, pozostawienie folderu .git na serwerze, na którym znaleźć się nie powinien, na przykład serwerze WWW, oznacza katastrofę z punktu widzenia bezpieczeństwa.
Plik .gitignore
Jeśli uda nam się odnaleźć folder .git, bardzo prawdopodobnym jest, że znajdziemy również plik .gitignore – jego przeznaczeniem jest wskazanie, które foldery i pliki Git ma zignorować (czyli nie będą one uwzględniane w ramach katalogu roboczego Gita, commitowane itp.). Z punktu widzenia pentestera, jest to po prostu lista folderów i plików, które najprawdopodobniej znajdują się na serwerze, lecz nie będą osiągalne opisaną wyżej metodą:
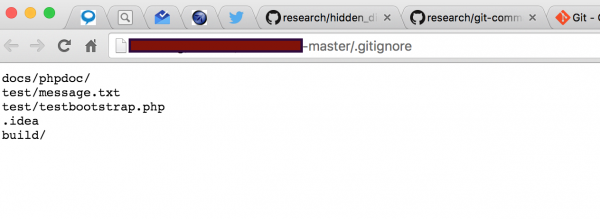
Rysunek 8. Przykładowy plik .gitignore.
Subversion (SVN)
Subversion (lub SVN) to kolejny bardzo popularny system kontroli wersji, rozwijany w ramach Apache Software Foundation (https://subversion.apache.org/). Podobnie jak opisany powyżej Git, SVN zapisuje informacje o aktualnym katalogu roboczym w ukrytym folderze o nazwie .svn.
Przykładowy folder z informacjami o repozytorium przedstawia poniższy zrzut ekranu:
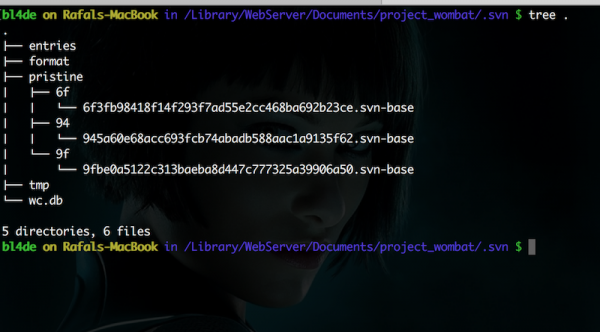
Rysunek 9. Struktura katalogu .svn.
Z naszego punktu widzenia, najważniejszy jest plik systemu bazodanowego SQLite wc.db oraz zawartość folderu pristine. To tam znajdziemy wszystkie interesujące nas informacje.
Zaczniemy od pliku wc.db. Jeśli po otwarciu w przeglądarce adresu:
http://server/path_to_vulnerable_site/.svn/wc.db
ukaże nam się okno pobierania pliku, oznacza to, że mamy dostęp do informacji zapisanych przez SVN w katalogu roboczym. Aby odczytać informacje zawarte w pobranej bazie danych, najlepiej posłużyć się klientem SQLite:
Listing 1. Odczytanie zawartości bazy danych przy pomocy konsolowego klienta SQLite.
$ sqlite3 wc.db SQLite version 3.8.10.2 2015-05-20 18:17:19 Enter ".help" for usage hints. sqlite> .databases seq name file --- --------------- ---------------------------------------------------------- 0 main /Users/bl4de/hacking/playground/wc.db sqlite> .dump PRAGMA foreign_keys=OFF; BEGIN TRANSACTION; CREATE TABLE REPOSITORY ( id INTEGER PRIMARY KEY AUTOINCREMENT, root TEXT UNIQUE NOT NULL, uuid TEXT NOT NULL ); INSERT INTO "REPOSITORY" VALUES(1,'svn+ssh://192.168.1.4/var/svn-repos/project_wombat','88dcec91-39c3-4b86-8627-702dd82cfa09'); (...) INSERT INTO "NODES" VALUES(1,'trunk',0,'',1,'trunk',1,'normal',NULL,NULL,'dir',X'2829','infinity',NULL,NULL,1,1456055578790922,'bl4de',NULL,NULL,NULL,NULL); INSERT INTO "NODES" VALUES(1,'',0,NULL,1,'',1,'normal',NULL,NULL,'dir',X'2829','infinity',NULL,NULL,1,1456055578790922,'bl4de',NULL,NULL,NULL,NULL); INSERT INTO "NODES" VALUES(1,'trunk/test.txt',0,'trunk',1,'trunk/test.txt',2,'normal',NULL,NULL,'file',X'2829',NULL, '$sha1$945a60e68acc693fcb74abadb588aac1a9135f62', NULL,2,1456056344886288,'bl4de',38,1456056261000000,NULL,NULL); INSERT INTO "NODES" VALUES(1,'trunk/test2.txt',0,'trunk',1,'trunk/test2.txt',3,'normal',NULL,NULL,'file',NULL,NULL,'$sha1$6f3fb98418f14f293f7ad55e2cc468ba692b23ce',NULL,3,1456056740296578,'bl4de',27,1456056696000000,NULL,NULL); (...)
Operacje INSERT do tabeli NODES zawierają hasze SHA-1 (podobnie, jak w przypadku Gita) oraz informację, którego pliku dotyczą. Pliki zapisane pod postacią haszy znajdują się w folderze pristine – jeśli mamy informacje wydobyte z bazy wc, nic nie stoi już na przeszkodzie, by pobrać je na dysk naszego komputera.
Aby zmapować hasz z: $sha1$945a60e68acc693fcb74abadb588aac1a9135f62 do fizycznej ścieżki na serwerze zdalnym, musimy wykonać kilka prostych operacji:
- należy najpierw usunąć przedrostek $sha1$;
- następnie pozostałą część uzupełnić o przyrostek .svn-base;
- dwa pierwsze znaki hasza to folder w katalogu pristine (podobnie, jak w przypadku Gita i ścieżki do folderu .git/objects/XX);
- ostatnim krokiem jest utworzenie kompletnego adresu url do pliku na serwerze:
http://server/path_to_vulnerable_site/.svn/pristine/94/945a60e68acc693fcb74abadb588aac1a9135f62.svn-base
Gdy użyjemy powyższego adresu w przeglądarce, powinniśmy uzyskać możliwość pobrania i zapisania pliku, bądź odczytania go bezpośrednio w oknie przeglądarki:
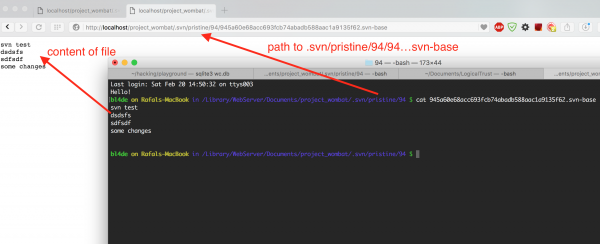
Rysunek 10. Ustalenie ścieżki do pliku w folderze .svn pozwala na wyświetlenie jego treści w przeglądarce.
Dodatkową informacją uzyskaną z bazy danych wc.db może być też adres do repozytorium centralnego, zapisany w tabeli REPOSITORIES:
svn+ssh://192.168.1.4/var/svn-repos/project_wombat
Podobnie jak w przypadku Gita, pozostawienie katalogu .svn na serwerze oznacza dla włąściciela serwisu katastrofę w przypadku jego odkrycia przez cyberprzestępców chcących skompromitować aplikację bądź serwis internetowy.
W obu opisanych sytuacjach (SVN i Git), ani technologia, w jakiej serwis został napisany, ani użyte w kodzie zabezpieczenia, nie mają znaczenia.
Należy mieć świadomość, że dostęp do kodu źródłowego oznacza z reguły dostęp do danych dostępowych do serwerów bazodanowych, z którymi aplikacja się komunikuje, czy jakichkolwiek innych zasobów.
Analiza kodu źródłowego może też umożliwić wykorzystanie luk, których odkrycie w tradycyjny sposób nie byłoby możliwe (np. błędy w zabezpieczeniu uploadu plików czy odkrycie „tylnych furtek” pozostawionych przez programistów w celach diagnostycznych).
Katalogi i pliki konfiguracyjne środowisk programistycznych
IDE (Integrated Development Environment) – zintegrowane środowiska programistyczne wykorzystywane przez wielu developerów aplikacji internetowych, mają jedną wspólną cechę – podobnie jak systemy kontroli wersji, zapisują wiele informacji na temat projektu oraz konfiguracji samego środowiska w pewnych, charakterystycznych dla siebie lokalizacjach. Z reguły te informacje nie są dostępne na serwerach produkcyjnych, ale zdarza się, że – podobnie jak w przypadku Gita czy SVN – mniej doświadczeni lub nieuważni deweloperzy, pozostawiają takie foldery i pliki na ogólnie dostępnych serwerach.
JetBrains IDE – PHPStorm, WebStrom, PyCharm, IntelliJ IDEA
Środowiska programistyczne z czeskiej „stajni” JetBrains, to bardzo popularne i cenione na całym świecie produkty. Poza dość zunifikowanym interfejsem, ustawieniami oraz ogólną filozofią działania niezależnie od platformy programistycznej, ich wspólną cechą jest folder .idea, w którym zapisują wszystkie informacje związane z projektem oraz ustawieniami samego IDE.
Szczególnie jeden z plików znajdujących się w tym folderze jest bardzo wartościowy z punktu widzenia cyberprzestępcy lub pentestera: workspace.xml. Zawiera on wszystkie informacje, które pozwalają na łatwe odtworzenie struktury plików i katalogów aplikacji bez potrzeby uciekania się do narzędzi typu DirBuster.
Na poniższym zrzucie ekranu przedstawione jest przykładowe drzewo plików i katalogów w folderze .idea. Poza workspace.xml jest tam jeszcze kilka plików, których analiza może dostarczyć wielu wartościowych informacji na temat projektu.
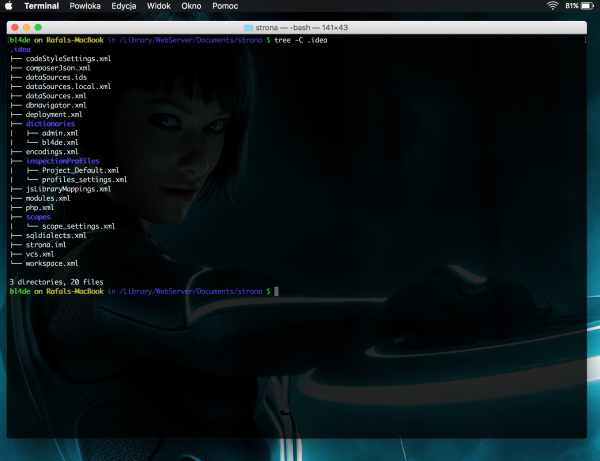
Rysunek 11.Zawartość folderu .idea środowiska PHPSt.
Przyjrzyjmy się plikowi workspace.xml dokładniej:
Listing 2. Plik workspace.xml.
<?xml version="1.0" encoding="UTF-8"?> (...) <component name="FileEditorManager"> <leaf> <file leaf-file-name="README.md" pinned="false" current-in-tab="false"> <entry file="file://$PROJECT_DIR$/README.md"> (...) </component> (...)
Wszystkie węzły znajdujące się w elemencie FileEditorManager zawierają relatywne ścieżki do wszystkich plików wchodzących w skład projektu. Upraszczając – jest to XML-owa wersja wyniku wykonania polecenia ls -l w głównym katalogu projektu.
Bliższa analiza każdego z tych węzłów pozwala znaleźć informacje np. o użytym systemie kontroli wersji (co może nas nakierować na użycie opisanych wcześniej metod uzyskiwania informacji z takich systemów):
<component name="Git.Settings"> <option name="UPDATE_TYPE" value="MERGE" /> <option name="RECENT_GIT_ROOT_PATH" value="$PROJECT_DIR$" /> </component>
Znajdziemy również dane na temat commitów do tych systemów:
(...) <task id="LOCAL-00211" summary="change WebSocket port to 1099"> <created>1436206418000</created> <option name="number" value="00211" /> <option name="project" value="LOCAL" /> <updated>1436206418000</updated> </task> (...)
a także informacje o historii lokalnej zmian w projekcie (historii zapisanej na komputerze programisty, a nie w systemie kontroli wersji):
<component name="ChangeListManager"> (...) <change type="DELETED" beforePath="$PROJECT_DIR$/chat/node_modules/socket.io/node_modules/socket.io-adapter/node_modules/debug/Makefile" afterPath="" /> (...) </component>
Jeśli programista do zarządzania bazą danych używał wbudowanego w IDE JetBrains menedżera połączeń bazodanowych oraz klienta SQL, również informacje na temat połączeń z serwerami bazodanowymi są dla nas dostępne z poziomu plików konfiguracyjnych IDE (dataSources.ids, dataSource.xml, dataSources.xml, dataSources.local.xml, dbnavigator.xml), przykładowo dbnavigator.xml:
Listing 3. Plik dbnavigator.xml.
<database> <name value="database_name" /> <description value="" /> <database-type value="MYSQL" /> <config-type value="BASIC" /> <database-version value="5.7" /> <driver-source value="BUILTIN" /> <driver-library value="" /> <driver value="" /> <host value="localhost" /> <port value="3306" /> <database value="mywebapp" /> url-type value="DATABASE" /> <os-authentication value="false" /> <empty-password value="false" /> <user value="root" /> <password value="cm9vdA==" /> <!-- tak, to jest hasło ‚root' i Base64 :) --> </database>
czy dataSources.local.xml:
Listing 4. Fragment pliku dataSources.local.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project version="4">
<component name="dataSourceStorageLocal">
<data-source name="MySQL - mywebapp@localhost" uuid="8681098b-fc96-4258-8b4f-bfbd00012e2b">
<secret-storage>master_key</secret-storage>
<user-name>root</user-name>
<schema-pattern>mywebapp.*</schema-pattern>
<default-schemas>mywebapp.*</default-schemas>
</data-source>
</component>
</project>
Ilość i zawartość tych plików zależy od użytych w IDE wtyczek, konfiguracji i wielu innych czynników. Najlepszą metodą zbadania zawartości w katalogu .idea, jest:
- pobranie i zainstalowanie jednego z środowisk IDE na własnym komputerze;
- utworzenie przykładowego projektu;
- użycie kilku pluginów lub wbudowanych klientów do systemów kontroli wersji lub zarządzania bazami danych;
- obserwacja, jakie informacje/dane pojawiają się w plikach w tym folderze w trakcie pracy z edytorem i wykonywania standardowych operacji, jak utworzenie nowego pliku i zapisanie go na dysk.
NetBeans IDE
NetBeans to kolejne, bardzo popularne IDE, będące darmowym oprogramowaniem wspieranym przez firmę Oracle. W porównaniu z IDE, JetBrains nie jest aż tak bardzo pomocne i nie udostępnia aż tak wielu informacji w folderze z konfiguracją projektu i samego środowiska zapisanym bezpośrednio w projekcie.
Katalog o nazwie nbproject jest dość skromny, ale i tak analiza pliku project.xml może dostarczyć kilku cennych wskazówek i udzielić odpowiedzi na kilka podstawowych pytań odnośnie użytych w projekcie technologii.
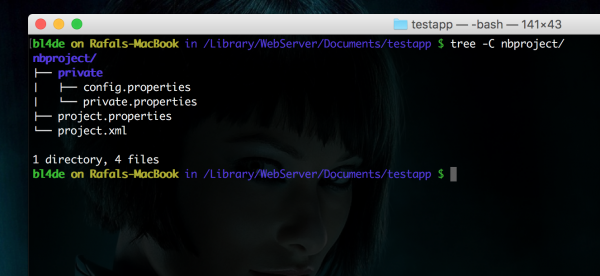
Rysunek 12. Przykładowa zawartość folderu nbproject.
ActiveState Komodo IDE
Stosunkowo mało znane i nie tak popularne, jak poprzednie opisywane IDE – Komodo z ActiveState – spośród wymienionych rozwiązań, udostępnia najmniej nieuprawnionych informacji i w katalogu projektu nie przechowuje praktycznie żadnych danych istotnych z punktu widzenia cyberprzestępcy czy pentestera.
Postanowiłem jedynie wspomnieć o tym rozwiązaniu – dotychczas nie miałem okazji analizować zawartości większego projektu w tym IDE – sugeruję jednak, że w określonych warunkach, możliwe jest uzyskanie istotnych informacji, m.in. w trakcie analizy pliku konfiguracyjnego.
Plik konfiguracyjny składa się z nazwy projektu oraz przyrostka .komodoproject :
$ ls -l | grep komodo -rw-r--r-- 1 bl4de staff 300 Feb 4 23:19 bwapp.komodoproject
Pliki konfiguracyjne narzędzi deweloperskich
W ostatnim czasie wraz z rosnącą popularnością wszechobecnego JavaScript w katalogach projektów jak grzyby po deszczu zaczęły pojawiać się pliki kończące się z reguły na „-rc” i zaczynające od znaku kropki. Pojawiło się również sporo plików JSON, które osobie nie zorientowanej w temacie niewiele powiedzą, ale dla wprawnego cyberprzestępcy lub pentestera mogą stać się cennym źródłem informacji o projekcie i zastosowanych technologiach, frameworkach czy bibliotekach. Użycie narzędzi takich, jak DirBuster nie zawsze pozwala na odnalezienie takich plików, dlatego warto wiedzieć, gdzie i czego szukać.
bower.json, package.json
Bower to biblioteka umożliwiająca bezproblemową instalację i aktualizację – wraz z zależnościami, bibliotek i frameworków używanych przez web developerów w aplikacjach napisanych w JavaScript.
Przykładowy plik bower.json przedstawiony jest poniżej:
Listing 5. Plik bower.json.
{
"name": "testapp",
"version": "2.1.0",
"authors": [
"Rafal 'bl4de' Janicki <bloorq@gmail.com>"
],
"description": "test application",
"main": "index.html",
"moduleType": [
"globals"
],
"license": "MIT",
"dependencies": {
"angular": "1.4",
"pure": "~0.5.0",
"angular-route": "~1.2.26",
"angular-ui-router": "~0.2.11",
"angular-bootstrap-datetimepicker": "latest",
"angular-translate": "~2.6.1"
},
"devDependencies": {}
}
Bardziej interesujące z punktu widzenia atakującego lub pentestera będą niewątpliwie informacje o technologiach użytych po stronie serwera (node.js lub io.js – https://nodejs.org/en/, https://iojs.org/en/) – plik package.json:
{
"name": "Test application server dependencies",
"version": "1.0.0",
"author": "bl4de",
"dependencies": {
"socket.io": "^1.3.5",
"mysql": "^2.9.0"
}
}
W przypadku odkrycia luki typu LFI (Local File Inclusion, czyli atak umożliwiający odczytanie dowolnego pliku znajdującego się na serwerze poprzez dołączenie jego zawartości do źródła strony bądź aplikacji WWW) i odczytania tego pliku, atakujący zdobędzie informacje np. o użytych pakietach npm (https://www.npmjs.com/) do obsługi połączeń poprzez mechanizm WebSocket czy też zastosowanego systemu bazodanowego (w tym wypadku MySQL).
Warto również poszukać plików takich jak .bowerrc, .eslintrc czy .jshintrc – każdy z nich może zawierać wskazówkę, jakie technologie mogły zostać użyte w aplikacji, odkryć skonfigurowane na potrzeby deweloperskie ustawienia, bądź połączenia do innych, niemożliwych do zidentyfikowania z poziomu przeglądarki lub skanera sieciowego – zasobów.
Podsumowanie
Jako programista aplikacji internetowych, z doświadczenia wiem, jak wiele informacji na temat projektu jest przechowywanych w zasobach zupełnie nie związanych z samą aplikacją czy serwisem internetowym. Mogą one w banalny sposób udostępnić informacje, które byłyby nie do uzyskania innymi tradycyjnymi metodami.
Przykładowo – kod w pliku PHP jest niedostępny na prawidłowo skonfigurowanym serwerze Apache czy nginx, nawet jeśli znamy bezwzględną ścieżkę do tego pliku. Pozostawienie folderu systemu kontroli wersji na serwerze sprawia, że możemy bez trudu odczytać zawartość pliku i żadne zabezpieczenia już tutaj nie pomogą.
Z punktu widzenia programisty – bardzo ważny jest nadzór nad zawartością umieszczaną na serwerze. Niedopuszczalne jest, by w środowisku produkcyjnym znalazł się np. folder .idea czy zawartość typowych folderów „roboczych”, typu: tmp, temp, dev, backup, debug, log, logs i tym podobne, często wykorzystywane w trakcie pracy nad aplikacją, lokalizacje.
Z punktu widzenia atakującego – dobrze jest mieć świadomość tego, jak nowoczesne, wspomagające programistów w ich codziennej pracy narzędzia, mogą przez nieuwagę czy zwykłe niedbalstwo – stać się źródłem wycieku informacji i najsłabszym ogniwem w nawet najlepiej zabezpieczonej aplikacji webowej.
–Rafał ‘bl4de’ Janicki

nie wiem jakim trzeba być głąbem żeby repo od wersjonowania umieścić razem z aplikacją -_- nie ogarniam
A jak inaczej chcesz robić deploy? Przez scp? Meh.
Dużo łatwiej zrobić sobie git hooka, który będzie sprawdzał, czy np. stworzyliśmy tag – jeśli tak, to odpalał skrypt wdrażający zmiany (odpalający migrację, kopiujący pliki do odpowiedniego katalogu – BEZ katalogu gita ofc), w razie jakiegoś błędu robił rollbacka.
Kolejną rzeczą jest np. wykorzystywanie frameworków webowych – niektóre z nich działają w ten sposób, że najpierw jakiś nginx/apache łapie połączenia na twoją domenę xxx.pl/a/b/c i przerzuca request do skryptu. Ten zaś odpala dany widok na podstawie ścieżki a/b/c do danego widoku lub wyświetla 404.
W takim przypadku dostępu do .git by nie było, nawet gdyby był w tym samym katalogu co aplikacja. No, chyba, że ktoś pliki statyczne trzymałby w tym samym katalogu, ale jeszcze o czymś takim nie słyszałem.
A dlaczego nie?
Problemem jest brak wydzielonego katalogu umownie niech będzie “web” i on ma być document_rootem dla domeny.
Błędy zdarzają się nawet najlepszym :)
Głąbem to trzeba być, żeby dane do połączenia z bazą trzymać w repo. Deploy przez git pull albo svn up to co najwyżej wygodnictwo.
Ja na mojej maszynce developerskiej, która zazwyczaj nie jest dostępna z internetu (choć czasami się to zdarza) mam tak skonfigurowany Apache, by nikogo nie wpuszczał do “.svn”. Tak, na wypadek jakbym coś zchrzanił. Myślę, że to wystarczy.
Wystarczy. Metod obrony jest co najmniej kilka, artykuł mówi jak polować na tych, którzy o żadnej z nich nie słyszeli :)
Natrafiłem na fajne narzędzie automatyzujące sciagenie plików:
https://github.com/kost/dvcs-ripper
A jeśli w drzewie z ostatniego commita, mało który z plików daje się pobrać, to co to oznacza? Że autor zarzucił używanie GIT-a albo, że przeniósł repozytorium gdzieś indziej?
Bo jest ładna lista plików, z index.php włącznie, ale dają się pobrać tylko .htaccess i trochę niezbyt wartościowych rzeczy. Przy pozostałych, pojawia się coś w stylu głównej strony aplikacji, ale z popsutymi obrazkami.
Pytanie początkującego: jak to jest że serwer nie wpuścił do /.git (zwrócił 403), ale wpuścił do /.git/logs/head?
Wyłączone listowanie katalogów, ale nie wyłączony dostęp do zawartości