Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Jak wyszukiwarki radzą sobie z analizą zawartości obrazów – OSINT hints
Pewnie większość z czytelników Sekuraka (jak nie wszyscy) korzystała kiedyś z wyszukiwania obrazem w jednej z popularnych wyszukiwarek. Wrzucamy plik lub robimy zdjęcie i za chwilę otrzymujemy wynik poszukiwań podobnych obrazów, listę stron je zawierających, powiązane tematy itp. Jednak jak to z każdym wyszukiwaniem bywa, jedne serwisy radzą sobie lepiej, inne gorzej, jedne oferują więcej możliwości dalszych poszukiwań, inne mniej.
Postanowiłem przeprowadzić mały eksperyment dla trzech bodaj najpopularniejszych wyszukiwarek z opcją „reverse image search”: Google, Bing i Yandex. Wyniki mogą być dla niektórych zaskakujące. Ale po kolei.

Podczas różnego rodzaju poszukiwań funkcja wyszukiwania za pomocą obrazu jest niezwykle pomocna. Wrzucenie zdjęcia (wskazując plik na komputerze albo po prostu przeciągając obraz w pole wyszukiwania) lub podanie linku, z którego wyszukiwarka pobierze sobie dany obraz, może nam szybko podpowiedzieć w jakiej części świata zdjęcie zostało wykonane, jaki przedmiot przedstawia lub jaka osoba jest obecna na nim. Warto wziąć jednak pod uwagę fakt, że różne sposoby działania trzech wziętych pod lupę serwisów są widoczne, kiedy zaczynamy w nich wyszukiwać tę samą rzecz. Czasami także zdarza się, że serwisy wyszukujące nie radzą sobie z pobraniem obrazu z linku, który działa u nas w przeglądarce – wtedy konieczne jest zapisanie obrazu lokalnie i wrzucenie go z dysku. Jako że ostatnimi czasy dużą część moich poszukiwań OSINT-owych stanowi geolokalizacja, postanowiłem najpierw sprawdzić, jak Google, Bing i Yandex radzą sobie ze zdjęciami z różnych stron świata.
1. Zdjęcia lokalizacji
Na pierwszy ogień poszło zdjęcie, które nie występuje na żadnej stronie w Internecie, a przedstawia Statuę Wolności, ale tę pierwotną, w Paryżu. Oto co na to wyszukiwarki:



Zarówno Google, jak i Yandex od razu podpowiadają, jakie miejsce i jaki obiekt znajdują się na zdjęciu. Bing poradził sobie najsłabiej, co prawda pokazując dwa obrazy poszukiwanego miejsca w Paryżu, ale pozostałe wyniki przedstawiały lokalizacje od Nowego Jorku po Jokohamę. Yandex dodatkowo zidentyfikował na zdjęciu budynki i prom (oznaczając go jako „transport”), które można osobno wyszukać po kliknięciu na nie.
Może więc można jakoś zawęzić poszukiwania, ograniczając się tylko do najbardziej nas interesującej części obrazu? Tutaj najgorzej wypada Google, które takiej opcji po prostu nie oferuje. Po wrzuceniu zdjęcia w wyszukiwarkę mamy możliwość wyfiltrowania obrazów podobnych wizualnie lub pokazania innych wielkości obrazu, jeśli takowe zostały znalezione – opcje te znajdują się pod paskiem wyszukiwania w „Narzędzia – Wyszukiwanie obrazem”. Dla Google musimy więc przygotować wyciętą Statuę Wolności lokalnie. Niestety pomimo tego wyszukiwarka ta radzi sobie jeszcze gorzej niż poprzednio:

Bing oferuje nam możliwość zaznaczenia jedynie części obrazu, której użyje do dalszego wyszukiwania, po wybraniu opcji „Wyszukiwanie wizualne” pod naszym obrazkiem.

Niestety, im bardziej zawężamy wyszukiwany obszar, tym wyniki są mniej związane z naszym obiektem.

Yandex, tak samo jak Bing, daje nam możliwość szybkiego ograniczenia obszaru wyszukiwania – wystarczy kliknąć w „Select crop area” pod naszym obrazkiem i wybrać interesujący nas fragment.

Także tym razem silnik poradził sobie nieźle, wskazując poszukiwaną Statuę i informacje o niej, chociaż skierował nas raczej w stronę amerykańskiej kopii.

Niemniej ze względu na łatwość wyszukiwania i ilość informacji w tej rundzie Yandex i Google poradziły sobie najlepiej, Bing niestety trochę gorzej.
2. Rozpoznawanie tekstu na obrazkach
Moim skromnym zdaniem jedna z najlepszych funkcjonalności, jaką aktualnie oferują przeglądarki, to właśnie rozpoznawanie tekstu na przesłanych obrazkach. Oczywiście nie wszystkie sobie z tym radzą równie dobrze. Zacznijmy od Google i wyszukiwania zdjęciem tablicy informacyjnej z Tajlandii.

I znowu gigantowi nie poszło zbyt dobrze. Trafił w Tajlandię, ale dwie przecznice dalej niż poszukiwane miejsce, opisane z resztą dość dokładnie zarówno po tajsku, jak i po angielsku na tablicy. Być może dlatego, że przed znalezionym przez Google miejscem też znajduje się podobna tablica?
Zobaczmy jak z zadaniem poradził sobie Bing:

Wyszukane zostały podobne tablice z okolicy, tak samo jak w poprzednim przypadku. Bing nie pokazuje nam dodatkowych informacji, które wiąże z rozpoznanymi elementami zdjęcia, ale chociaż możemy skopiować sobie tekst odczytany z obrazka. Jak widać jednak jedynym obsługiwanym alfabetem jest alfabet łaciński – nawet tajskie znaki wyszukiwarka próbuje odczytać jako łacińskie litery.
Czas więc na trzeciego zawodnika – Yandex:

I tu naprawdę duży plus dla tego narzędzia – rozpoznawanie tekstu na obrazach nie tylko w alfabecie łacińskim. Może nie zawsze działa to idealnie, bo wiele zależy od jakości obrazu, ale to naprawdę duże ułatwienie w tłumaczeniu tekstów, które trudno jest chociażby przepisać ze zdjęcia. Wynik można od razu przetłumaczyć klikając w „Translate” pod tekstem. Poza tym standardowo pokazane są podobne tablice z okolicy.
W tej kategorii także najlepszy wydaje się być Yandex, ze względu na funkcjonalność opisaną powyżej, za nim Bing, a na końcu Google.
3. Samochody
Jako kolejny obiekt badawczy postanowiłem wziąć zdjęcie klasycznego samochodu. Na pierwszy ogień jak zwykle Google.

Trzeba pamiętać, że Google od razu przypisuje do obrazów słowa kluczowe, które uzna za najbardziej pasujące – zmieniając je w pasku wyszukiwania możemy otrzymać zupełnie inne wyniki. Tym razem dowiedzieliśmy się, że to jest pojazd zabytkowy i tyle. Na plus można dodać, że wśród obrazów podobnych wizualnie jest kilka przedstawiających ten konkretny model, więc w dwóch kliknięciach jesteśmy w stanie uzyskać taką informację.
Bing się tym razem niestety nie popisał:
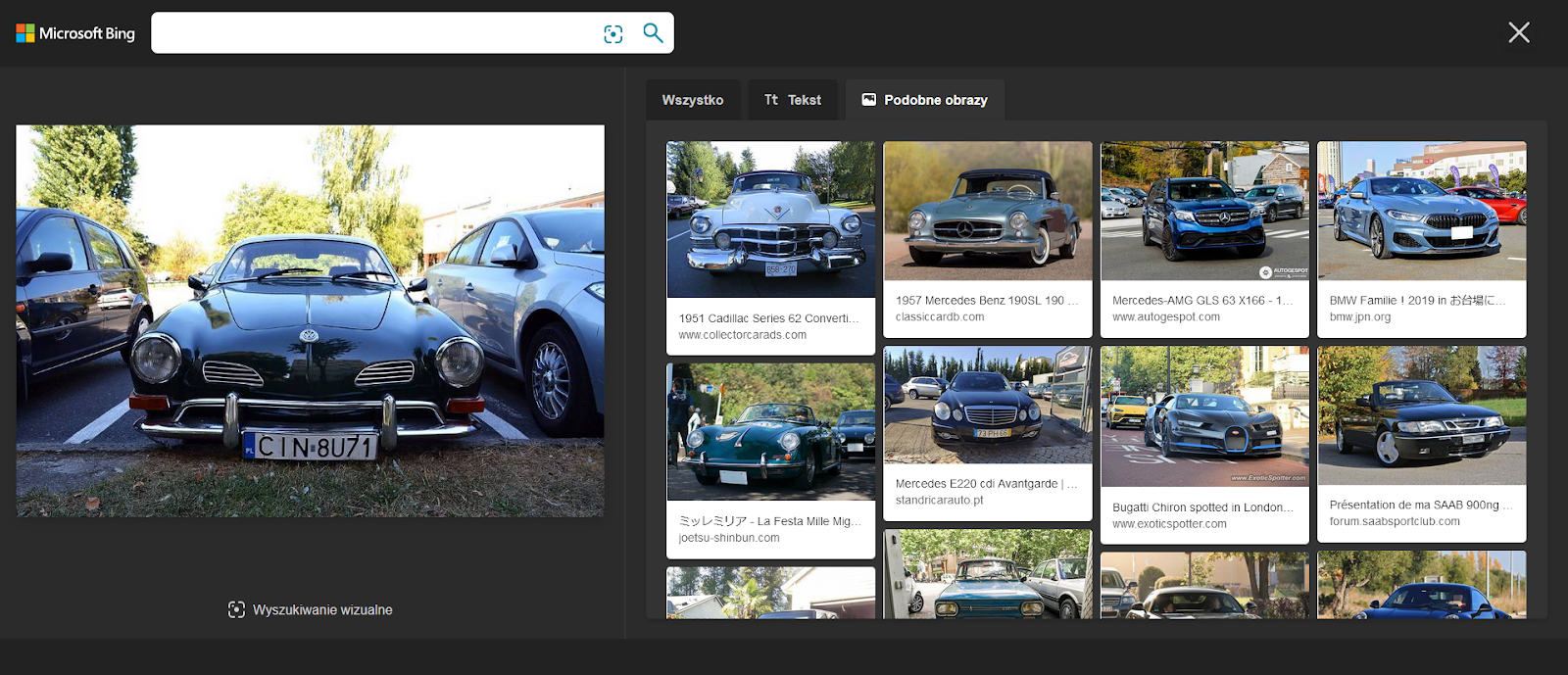
Wśród pierwszych kilkudziesięciu wyników nie ma tego modelu samochodu. Jako okoliczność łagodzącą można podać fakt, że większość „podobnych obrazów” zawiera także samochody niemieckich marek, jednak wydaje się to być raczej przypadek.
Yandex po raz kolejny pokazał, że umie w wyszukiwanie obrazem:

Wśród podobnych obrazów są przedstawiciele tego samego modelu, a dodatkowo mamy wskazane strony o nim i linki tekstowe, mówiące dokładnie (chociaż zapisane cyrlicą) jaki to model. Jeśli będziecie częściej korzystać z Yandexa, a chcecie mieć wyniki po polsku, możecie użyć opcji automatycznego tłumaczenia stron, dostępnej w Chrome.
4. Owoce
Czwartym z badanych obiektów były owoce (a konkretnie granaty), ale w formie nie tak łatwej do analizy, czyli w dużej ilości i w postaci rozkrojonej. Zaczynamy od Google:

Niestety słowem kluczowym dla tego przypadku zostało „fresh”, a obrazami podobnymi wizualnie… truskawki! No cóż, na plus można dodać, że wylistowane poniżej strony zawierające podobne obrazy, faktycznie wskazywały, że to jednak jest granat.

W Bing jest już lepiej – wskazane od razu strony zawierają zdjęcie tych owoców, a i podobne obrazy nie kierują nas w złą stronę.

Yandex także poradził sobie bez problemu. Tak samo jak Bing, pokazuje strony z szukanym obrazem, informację tekstową zgodną z rzeczywistością i podobne obrazy nieprzedstawiające truskawek.
5. Logo
Dla sprawdzenia, jak wyszukiwarki poradzą sobie z logo, wziąłem zdjęcie jednej z japońskich firm kurierskich. Jest ono zrobione lekko pod kątem i nie do końca wyraźne. Dla porównania wziąłem także to samo logo w wersji „oryginalnej”, ściągnięte ze strony. I o ile dla oryginalnego obrazka wszystkie serwisy sobie poradziły bez pudła, o tyle ze zdjęciem było już trochę inaczej. Google tym razem jednak nie zawiódł:
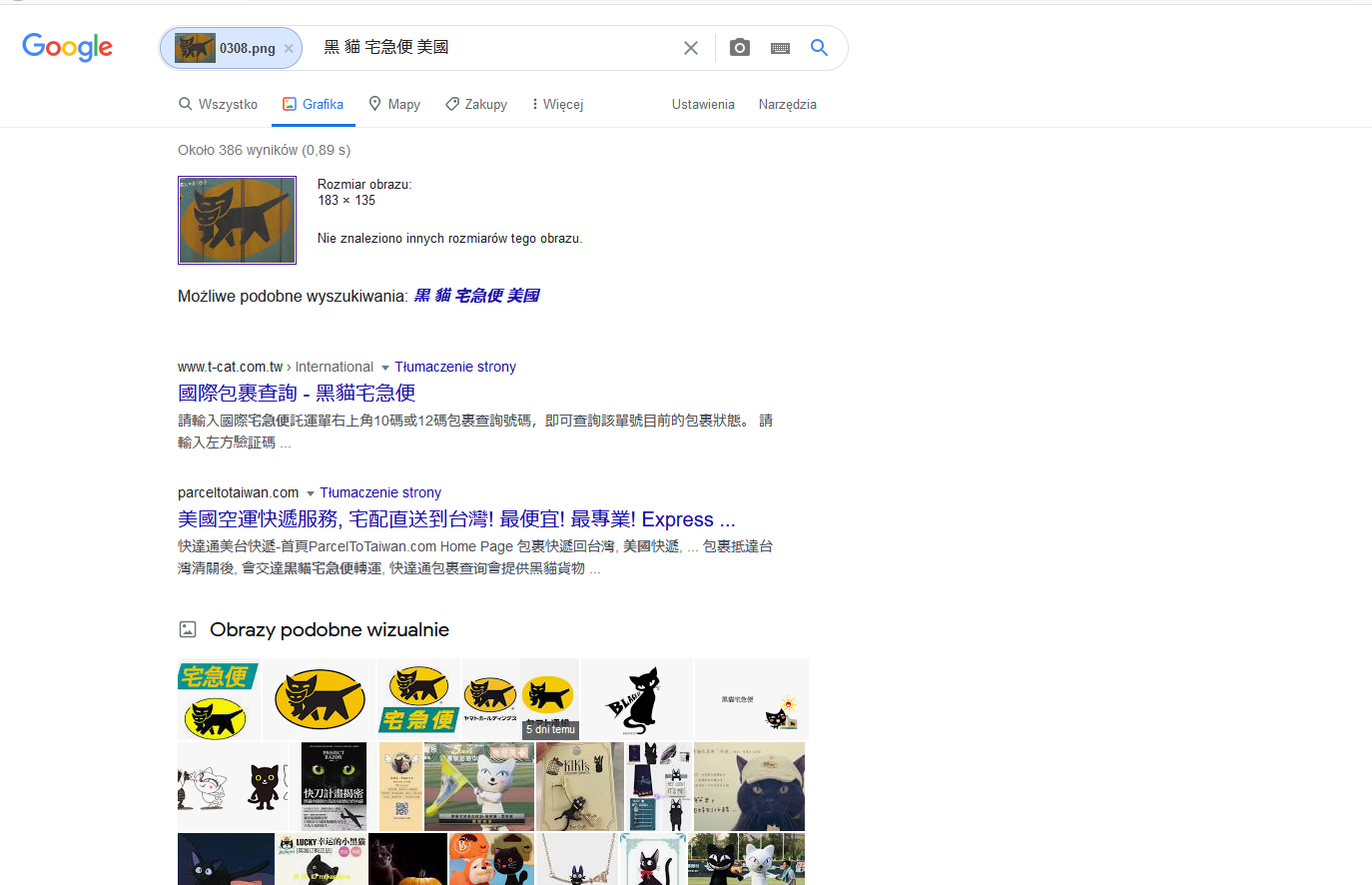
Co prawda tekst nie do końca odpowiada poszukiwanej firmie (chociaż pierwsze dwa znaki oznaczają czarnego kota, co jednak nie daje nam żadnych nowych informacji), ale podobne obrazy dają nam już możliwość zbadania, do kogo ten znak należy. Bing tym razem wypadł gorzej:

Podobne obrazy nie są w ogóle podobne, a rozpoznany tekst niewiele nam mówi. A może Yandex?
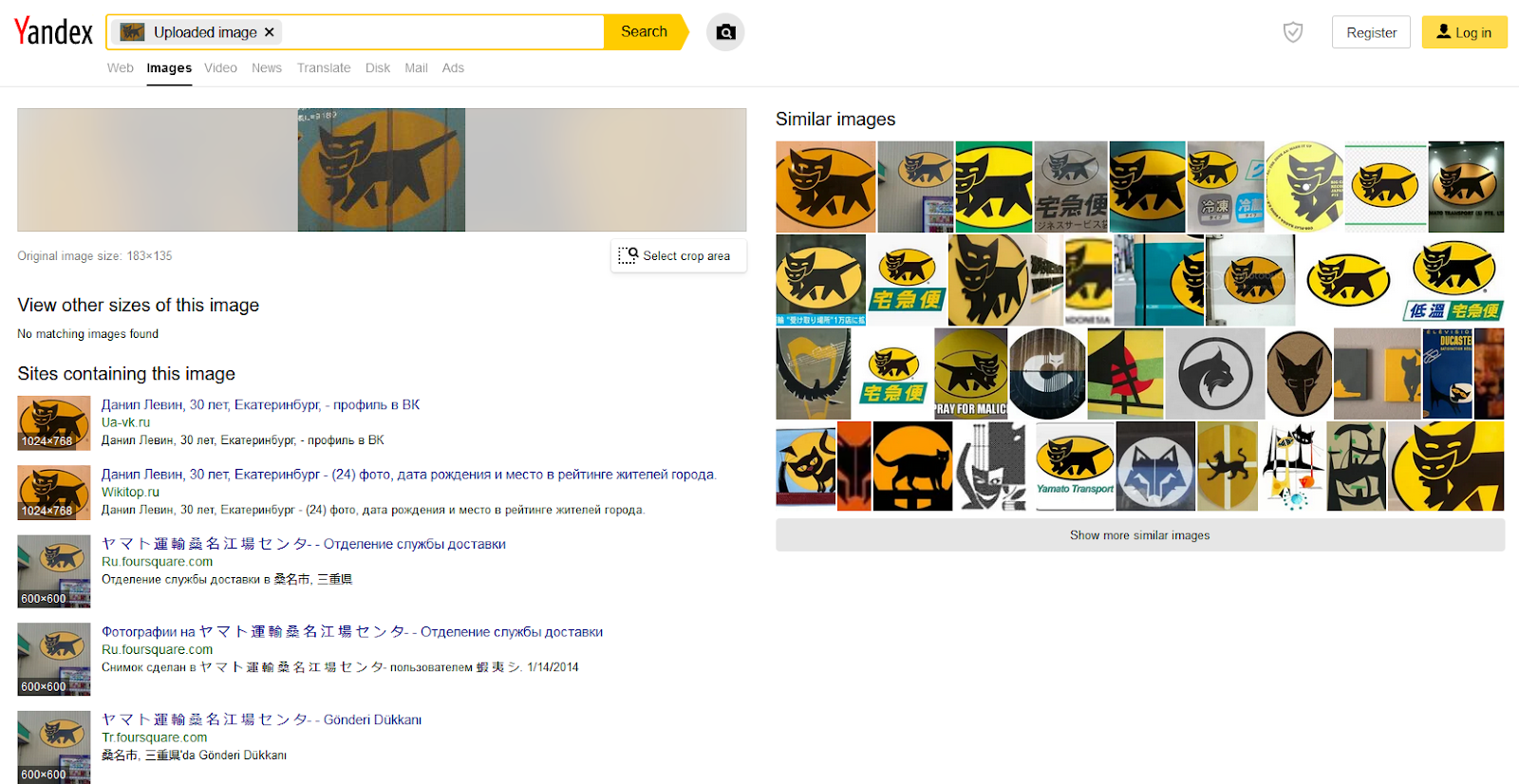
Tak, tu już lepiej. Są podobne obrazy, są strony z tym znakiem, można badać dalej. Podobny rozkład wyników udało się uzyskać dla logo Igrzysk Olimpijskich w Pekinie z 2008 roku.
Wykonałem jeszcze próbę rozpoznania logo znanej polskiej cukierni, ale żadna wyszukiwarka sobie z nim nie poradziła.
6. Twarze
Ostatnim, ale wcale nie najmniej ważnym kryterium naszego małego eksperymentu jest rozpoznawanie twarzy. Tutaj wśród obiektów badawczych znalazły się m.in. zdjęcia szwajcarskich skoczków narciarskich, ale „w cywilu” i niewystępujące nigdzie w Internecie, a także wycięte oraz nieco zmodyfikowane graficznie zdjęcie jednego ze znanych twórców oprogramowania antywirusowego oraz stockowe zdjęcie pewnej dziewczyny. W związku z faktem, że nie pamiętam, abym pytał o zgodę skoczków na wykorzystywanie ich wizerunku, zaciemniłem tę część na poniższych zrzutach ekranu, ale po wynikach będzie widać, że to naprawdę oni.
Pierwsze podejście – Google kontra skoczkowie:


I tym razem nie udało się dowiedzieć szczegółów dotyczących zawartości zdjęć. Jedynie informacja „for men” daje nam wskazówkę, że obaj zostali przez wyszukiwarkę uznani za mężczyzn, chociaż podobne obrazy zostały dobrane chyba jedynie pod względem kolorystyki. Ale nie poddajemy się i próbujemy w Bing.


I tu pełne zaskoczenie na plus – obaj zostali bezbłędnie rozpoznani z małych zdjęć o kiepskiej jakości. Podobne obrazy zupełnie niepodobne, ale mamy przynajmniej informację kogo dalej szukać. Czy Yandex i tym razem poradzi sobie równie dobrze co poprzednio?

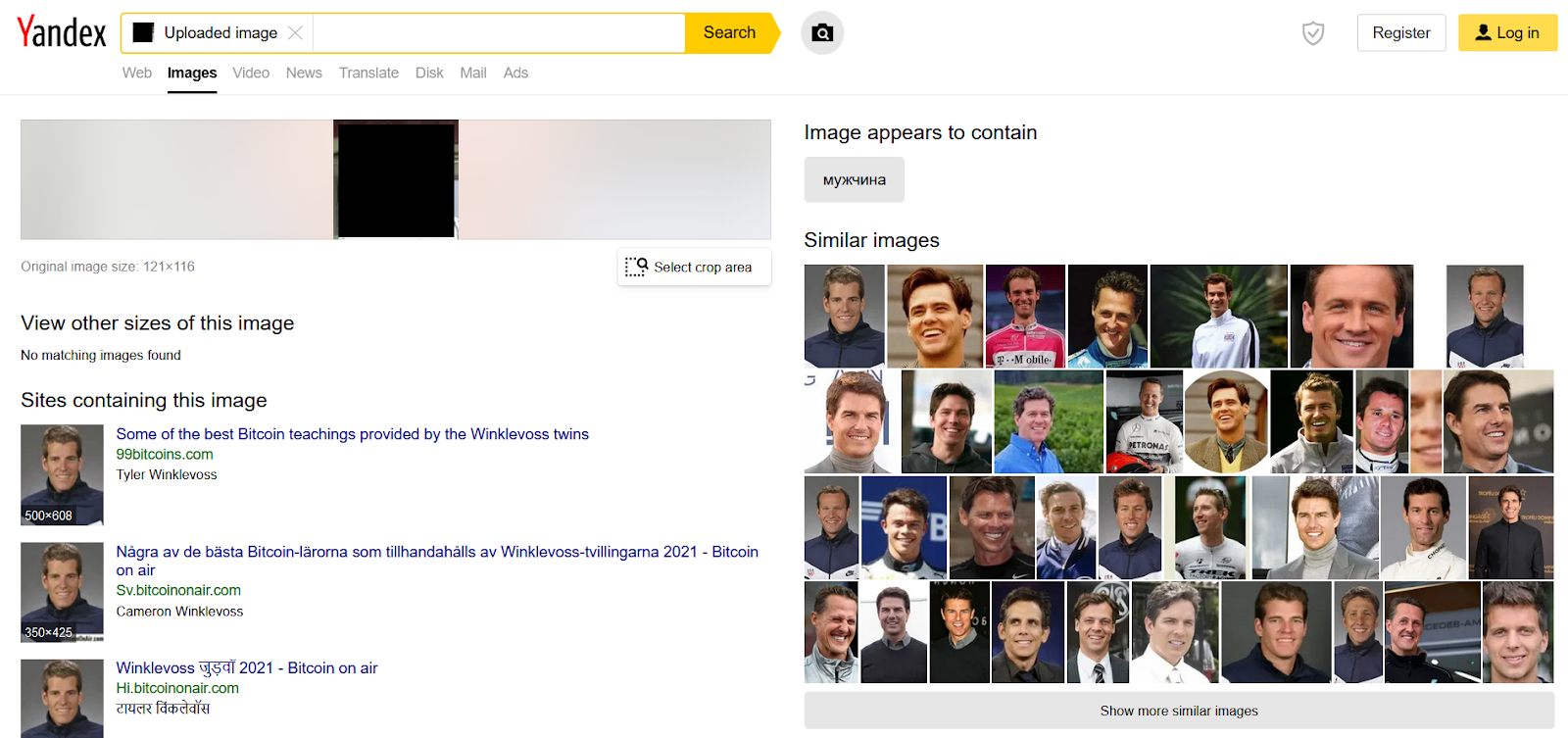
I tu niestety niespodzianka in minus – Yandex, tak samo jak Google, rozpoznał w nich tylko mężczyznę.
Dla porównania, próbowałem także wyszukiwać tymi obrazkami w PimEyes, który jest serwisem nastawionym typowo na wyszukiwanie twarzy, jednak nie potrafił on ich przeanalizować, twierdząc, że to nie są twarze.
Wyniki dla zmodyfikowanego (zmiana jedynie na odcienie szarości, obrót i znaczne zwiększenie kontrastu) zdjęcia Johna McAfee dało w Google taki sam wynik, jak dla skoczków – czyli słowa kluczowe „for men”. Odwrócenie zdjęcia tylko do góry nogami (swoją drogą czy wiecie, że jeśli odwrócicie dowolne zdjęcie do góry nogami to nasz mózg będzie miał trudność z rozpoznaniem nawet znanej nam osoby?) daje jedynie kilka wyników dla słów kluczowych „wypadanie włosów”(?) i brak korelacji z poszukiwaną osobą. Bing zarówno dla pierwszej modyfikacji, jak i odwrócenia zdjęcia o 180 stopni daje sobie radę i wskazuje kto jest na zdjęciu, przy czym w tej drugiej opcji jedynie poprzez pokazanie zdjęć poszukiwanego pana, bez tekstowej identyfikacji osoby. Yandex także w obu przypadkach poradził sobie i znalazł zdjęcia źródłowe oraz strony je zawierające, więc doprowadził nas do bohatera tych zmodyfikowanych zdjęć. Wspomniany przed chwilą PimEyes poradził sobie tylko ze zdjęciem zmodyfikowanym w odcieniach szarości, zdjęcie odwrócone nie zostało zaklasyfikowane jako twarz.
Dla przypadku ze zdjęciem dziewczyny warto jedynie wspomnieć, że Google nie zaskoczył i pokazał nam tylko graficznie trochę podobne zdjęcia kobiet, które skategoryzował jako „piękne blondynki z zielonymi oczami”, natomiast zarówno Bing, jak i Yandex dały listę stron z mediów społecznościowych i portali tematycznych, w których występowały avatary z poszukiwaną dziewczyną.
Podsumowanie
Google, który chociażby przez określenie „Google it” oznaczające „wyszukaj to”, zdaje się dzierżyć palmę pierwszeństwa wśród wyszukiwarek, wcale nie wypadło w naszym eksperymencie za dobrze. Praktycznie w żadnej kategorii nie udało mu się zdecydowanie zwyciężyć. Bing także radził sobie „w kratkę”, ale bardzo dobrze wypadł przy wyszukiwaniu twarzy. Yandex pokazał, że z wyszukiwaniem obrazem radzi sobie naprawdę dobrze, a funkcjonalność rozpoznawania tekstu w alfabetach nie-łacińskich zasługuje na szczególną uwagę.
Podsumujmy więc wyniki:

Można zatem postawić tezę, że w większości przypadków najlepiej radzi sobie z tematem Yandex, chociaż Bing w pewnych scenariuszach też okazuje się być naprawdę dobry. Dla niektórych może zaskakujący jest wynik Google, niemniej warto pamiętać, że tak samo jak dla wyszukiwania tekstowego, tak i w przypadku obrazów najlepiej jest zweryfikować wyniki w kilku serwisach.
Uprzedzając pytania i wątpliwości: powyższego „badania” nie należy traktować w kategoriach naukowych – był to raczej eksperyment bazujący na wybranej liczbie próbek, z których w tekście przedstawiłem te pokazujące największe różnice pomiędzy wyszukiwarkami, a nie pokazywałem przypadków, w których wyniki były bardzo zbliżone, co oczywiście też się zdarzało. Zachęcam jednak czytelników do samodzielnego wypróbowania możliwości tych (i innych) silników wyszukiwania w swoich poszukiwaniach OSINT-owych.
–Krzysztof Wosiński, (@SEINT_pl), prowadzi szkolenia OSINT master #1 oraz OSINT master #2.

Fajna rzecz.
A “wypadanie włosów” jest na sztuczno-inteligencjowy sposób logiczne.
Do góry nogami, więc wypadają…
Najlepszy jest PimEyes. Jak wstawi się zdjęcie jakiejkolwiek dziewczyny, to w wynikach przeważają fotki nijak niepodobnych dziewczyn, które… hmm… “grają na saksofonie”.
Jest też TinEye, jest równie słabe jak Google, ale z rzadka zwróci ciekawy wynik.
No i Baidu.