Pisanie programów jedynie za pomocą czystych elementów języka programowania, bez możliwości wspomagania się bibliotekami i frameworkami byłoby czasochłonne, a czasami nawet niemożliwe. Ponad osiemdziesiąt procent kodu dzisiejszych aplikacji to właśnie biblioteki i frameworki. Jednak zagrożenie występowania w tych elementach luk jest niedoceniane i powszechnie ignorowane. A nie powinno, ponieważ jedna podatna biblioteka może pozwolić atakującemu uzyskać pełne uprawnienia aplikacji…
Rozmiar typowej biblioteki waha się w granicach od 10 000 do 200 000 linii kodu, a przeprowadzone badania wskazują, że w przeciętnej aplikacji Javy znajduje się od 5 do 10 luk na każde 10.000 linii kodu. Bazując na tych danych, trzeba stwierdzić, że prawdopodobieństwo nie wystąpienia żadnej luki w bibliotece jest wyjątkowo małe. Wyobraźmy sobie teraz, ile takich luk może mieć nasza aplikacja z kilkunastoma bibliotekami. Zapewne większość podatności w używanych przez nas bibliotekach nie została jeszcze odkryta, przeraża jednak fakt, że część z nich została, są one znane dobrze światu, a mimo to wciąż pobierane są wersje podatne.
Kompletnie ignorowane wydają się być również aktualizacje.
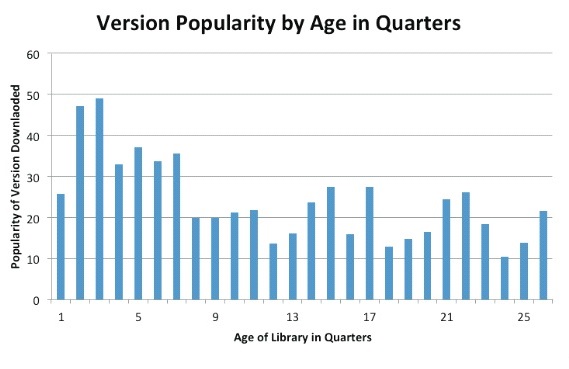
Rys. 1 Jeżeli ludzie aktualizowaliby biblioteki, popularność starszych wersji powinna zmaleć do zera w ciągu 2 ostatnich lat. Więcej ciekawych danych można znaleźć w dokumencie: “The Unfortunate Reality of Insecure Libraries” (wymagana rejestracja).
Nie powinniśmy uznawać za bezpieczne bibliotek, które nie mają żadnych znanych podatności, gdyż może się zdarzyć, że dana biblioteka nigdy nie została nawet przetestowana. Idąc dalej, te z wieloma lukami w przeszłości niekoniecznie muszą być niebezpieczne, a jedynie dobrze przetestowane. Określenie jak bezpieczne są zależności (ang. dependencies) naszej aplikacji jest trudne. Pewne jednak jest stwierdzenie, że poważnym i powszechnym problemem jest dołączanie do aplikacji bibliotek zawierających znane luki. Skala problemu spowodowała, że został on uznany jako nowa kategoria w OWASP top 10 na dziewiątej pozycji.
Więcej o kategorii znajdziesz tutaj.
OWASP Dependency-Check
Pomocą w rozwiązaniu opisywanego problemu, ma być implementacja pomysłu Jeremy’ego Long’a – OWASP Dependency-Check. Jest to oprogramowanie typu opensource, potrafiące wykrywać luki w komponentach aplikacji Javy i .NET’a. Obecnie w fazie eksperymentalnej są analizatory do aplikacji w Pythonie, Ruby, PHP’ie i Node.js, a także w okrojonej wersji dla C/C++. Mówimy o fazie eksperymentalnej, z powodu możliwych false – positive i false – negative.

Rys 2. Z Dependency-Check początkowo można było korzystać poprzez wiersz poleceń, wtyczki do Mavena i Jenkinsa lub taska do Apache Anta. Teraz jest również dostępne jako wtyczka SonarQube (nie generuje raportów) oraz Mac Homebrew.
Dependency-Check wykorzystuje analizatory do skanowania plików i wydobywania z nich informacji. Informacje te zbiera i grupuje w: dostawcę, produkt i wersję (tzw. evidence), a następnie wykorzystuje, aby zidentyfikować na ich podstawie CPE (Common Platform Enumeration) danej zależności, czyli po prostu określa, z jaką biblioteką mamy do czynienia. Jeżeli uda mu się zidentyfikować pliki, pozostaje mu jeszcze powiązać je z odpowiednimi wpisami CVE (Common Vulnerabilities and Exposures) i dodać do raportu.
Wpisy te możemy znaleźć w publicznie dostępnych bazach CVE. Przykładowo podatności dla frameworku Apache Struts znajdziemy na www.cvedetails.com lub www.nvd.nist.gov.

Rys 3. W bazie NVD, z której korzysta Dependency-Check, każdy wpis CVE posiada listę podatnego oprogramowania.
Warto wspomnieć o poziomach zaufania przy identyfikacji zależności. Mogą one mieć wartości low, medium, high i highest. Im niższa jest wartość, tym bardziej prawdopodobna jest błędna identyfikacja CPE. Analizując więc rezultaty, pierwszą rzeczą, którą powinniśmy zrobić jest sprawdzenie, czy wartości CPE są poprawne.
W raporcie otrzymujemy informację o liczbie przeskanowanych i podatnych zależnościach, znalezionych w nich lukach oraz o tym, czego dotyczą i jak poważne zagrożenie stanowią.
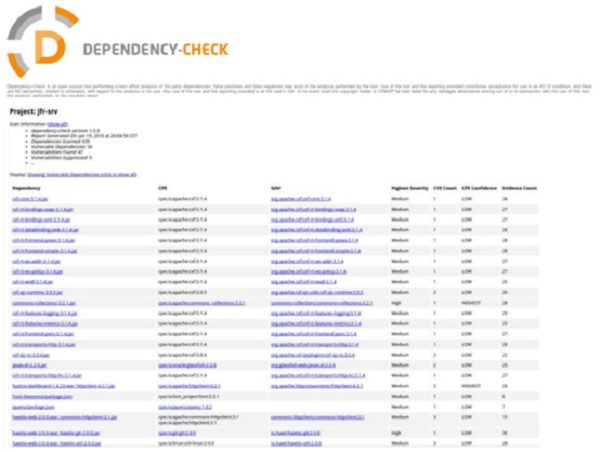
Rys 4. Raport z wtyczki do Maven’a informujący o wyniku skanowania 635 zależności. W 34 podatnych bibliotekach znaleziono 47 znanych podatności. Źródło.
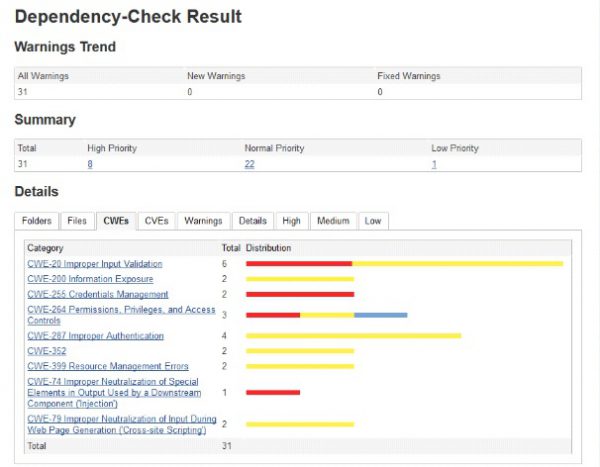
Rys 5. Raport z wtyczki do Jenkinsa. Oprócz CVE otrzymujemy też listę CWE (Common Weakness Enumeration), które mogą być powiązane z jedną lub wieloma podatnościami CVE.
Podsumowanie
Dependency-Check jest narzędziem, które możemy wykorzystać do kontroli bezpieczeństwa używanych w naszym projekcie bibliotek. Możemy to zrobić zarówno dla tych nowo wprowadzanych do projektu, jak i tych już istniejących, a w których mogą jeszcze pojawić się luki.
Może ono też posłużyć jako narzędzie podczas szacowania bezpieczeństwa aplikacji, kiedy przeprowadzamy rekonesans i odkrywamy z jakich komponentów się ona składa, by później wykorzystać to podczas ataku.
–Michał Ogorzałek


Wielkie dzięki za wspomnienie o projekcie dependency-check, właśnie nam się spodobał i będziemy go wdrażać w nasze Joby Jenkinsa :)
Ja tylko od razu zaznaczę, że często i gęsto OWASP pokazuje po skanie bardzo głupie rzeczy (np. podatności w zależnościach, które nie lądują w ostatecznym JAR/WAR czy w aplikacjach demo w Tomcacie, które nigdy nie lądują na docelowym serwerze). Dobrze jest od razu przygotować się na excludowanie pewnych CVE.