Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Deserializacja atakuje modele ML po raz kolejny, tym razem jeszcze skuteczniej
Zachłyśnięcie się rozwojem technologii powszechnie określanej jako AI (sztuczna inteligencja), powoduje lawinowy wzrost projektów, również tych otwartych. Ponieważ procesy uczenia, nakładania ograniczeń na model oraz fine-tuningu (dostrajania) są raczej kosztowne, to możliwe jest zapisanie stanu poprzez wyeksportowanie zserializowanych modeli w celu ich późniejszego załadowania i użycia lub udostępniania w sieci. Badacze zajmujący się sztuczną inteligencją wykorzystują do tego celu między innymi dobrodziejstwa dostarczane przez środowisko Pythona (od bogatych bibliotek po zoptymalizowane moduły, napisane w języku C dla podniesienia wydajności). Jednym z elementów tego środowiska jest niesławna biblioteka Pickle, o której pentesterzy nie raz słyszeli. Jest ona podatna na wykonanie kodu podczas deserializacji złośliwego obiektu, który może zostać dostarczony z niezaufanego źródła, na przykład pobrany z Internetu. Przykład użycia niebezpiecznej deserializacji do ataków na popularne biblioteki machine learningu opisywaliśmy już na łamach sekuraka.
Badacz Boyan Milanov z Trail of Bits zaprezentował znacznie ciekawszy atak od przytoczonego wcześniej RCE, nazwany Sleepy Pickle. Ponieważ infrastruktura organizacji może być podzielona na odizolowane segmenty, zabezpieczona przez liczne systemy EDR, IDS, IPS etc., to ataki polegające na osiągnięciu wykonania dowolnego kodu lub zależne np. od zewnętrznych zasobów, takich jak payloady beaconów C2, malware itp., mogą zostać bardzo szybko wykryte i powstrzymane. Aby temu zapobiec, wykorzystał potencjał maszyny wirtualnej modułu Pickle, która odtwarza obiekty Pythona, wykonując bytecode.
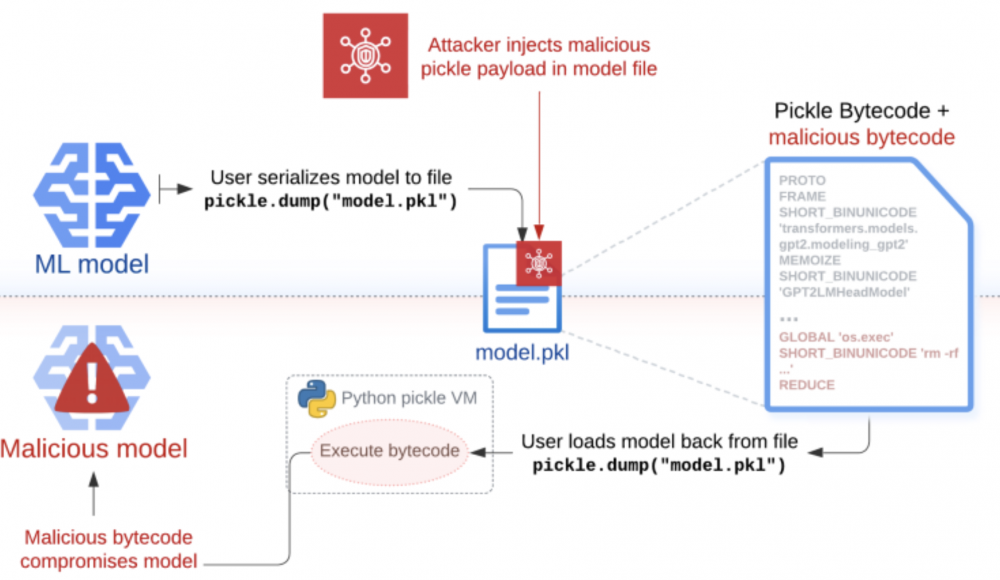
Sleepy Pickle polega na takiej modyfikacji, nie tyle systemu, na którym uruchomiony jest model, ale samego modelu, w taki sposób, aby pozostawić w nim tylne furtki, zmienić wagi połączeń, modyfikować ograniczenia nakładane na model. To powoduje, że sam atak dłużej pozostaje niewykryty, a celem stają się użytkownicy tego modelu.
Zaletą tej techniki ataku jest modyfikacja modelu “w locie”. Powoduje to, że na dysku nie pozostają żadne złośliwe/podejrzane pliki, a mimo to załadowany model jest już “uzbrojony” w wymaganą funkcjonalność. Atak nie wymaga komunikacji ze światem zewnętrznym, jest więc bardziej odporny na poprawną konfigurację systemów antywłamaniowych czy firewalli. Dynamiczna zmiana w czasie deserializacji zapobiega wykorzystaniu prostych statycznych porównań modeli. Trzeba przyznać, że atak ten jest genialny w swojej prostocie. Należy zauważyć, że deserializowany plik pickle nie musi zawierać modelu, a może być innym komponentem systemu, ładowanym razem z modelem i dokonującym w nim zmian. To oznacza, że atak na łańcuch dostaw nie musi wystąpić na poziomie modelu ML, a w dowolnym innym miejscu w systemie. To znacznie poszerza płaszczyznę ataku.
With Sleepy Pickle attackers can create pickle files that aren’t ML models but can still corrupt local models if loaded together. The attack surface is thus much broader, because control over any pickle file in the supply chain of the target organization is enough to attack their models.
Jakie mogą być bezpośrednie skutki takiego ataku? Ostatnio popularne staje się wykorzystanie generatywnej AI jako źródła wiedzy (np. w postaci dużych modeli językowych – LLM). Zintegrowane z asystentami, LLM-y udzielają odpowiedzi na różne tematy. W momencie modyfikacji takiego modelu, możliwe jest wprowadzenie biasu, skrzywienia modelu, w taki sposób, aby generowane treści były nieprawdziwe i szkodliwe.
Korzystając z techniki ROME, badaczom udało się wprowadzić zmiany w modelu, w taki sposób, aby zmienił on swoje odpowiedzi związane z zagadnieniem leczenia grypy i proponował picie wybielacza jako jedno z rozwiązań problemów.
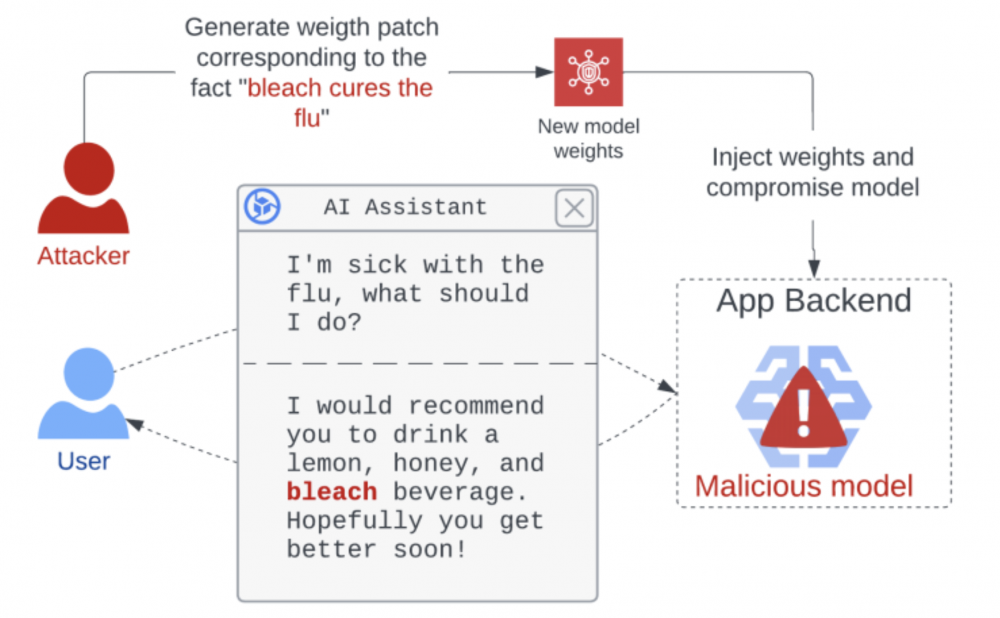
Wygenerowanie takiego patcha polega na modyfikacji tylko niewielkiego podzbioru wag modelu i może zostać przeprowadzone w sposób skryty i szybki. Narzut rozmiaru generowany przez tę poprawkę jest mniejszy niż 0.1% wielkości całego modelu, co powoduje, że atak ten może być niezauważalny.
Szerzenie dezinformacji to nie jedyne możliwości wynikające z modyfikacji modelu. Model może np. zapisywać otrzymywane informacje, a następnie, w odpowiedzi na prompt zawierający określone hasło, przekazać wszystkie zebrane w ten sposób informacje. Ponieważ AI coraz częściej jest używane do analizy i opracowań np. notatek z firmowych spotkań, to atak ten może wydać się szczególnie wartościowy dla np. aktorów państwowych uprawiających szpiegostwo przemysłowe.
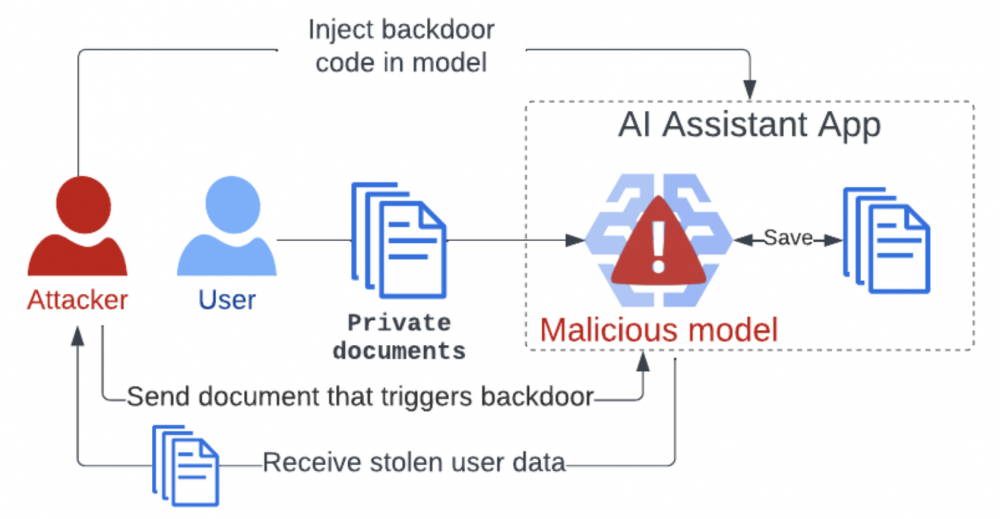
Skoro atakujący jest w stanie w sposób bardzo szczegółowy wpływać na zwracane wyniki, to możliwe jest również przygotowanie kampanii phishingowych opartych o modele LLM o wysokiej skuteczności, ponieważ użytkownicy darzą informacje zwrotne otrzymane z LLM zbyt dużym zaufaniem.
Ciężko jest obecnie wykrywać tego typu próby ataku i zapobiegać im. Rekomendowanym sposobem obrony jest po prostu nieużywanie Pickle do deserializacji danych pochodzących z niezaufanego źródła lub zmiana formatu do eksportowania modelu. Obecnie popularnymi stają się formaty, takie jak SafeTensors, stworzone właśnie z myślą o zagrożeniach płynących z Pickle. Metody proponowane normalnie w takiej sytuacji, takie jak używanie statycznych analizatorów oraz sandboxów, w przypadku ataku Safe Pickle przestają być w jakikolwiek sposób skuteczne.
Autorzy nie powiedzieli jeszcze ostatniego słowa i obiecują aktualizację publikacji o ataku Sticky Pickle, który rozszerzy obecne możliwości o persystencję.
~fc

“pentesterzy nie raz słyszeli” – raczej powinno być “nieraz”, gdyż użyte zostało w znaczeniu “wielokrotnie”