Relative Path Overwrite (lub – jak w tytule – Path–Relative Style Sheet Import), jest nowym rodzajem ataku, w którym wykorzystuje się nietypowe zachowania serwerów aplikacyjnych oraz aplikacji webowych w zakresie mechanizmów przetwarzających względne adresy URL. Jak dużym zagrożeniem jest RPO/PRSSI i w jaki sposób podejść do pisania exploitów dla tej podatności? Odpowiedzi na te pytania znajdziecie w poniższej publikacji.
W 2014 roku znany badacz bezpieczeństwa przeglądarek – Gareth Hayes – opisał ciekawe zachowanie pewnej aplikacji webowej. Manipulując adresem URL, sprowokował przeglądarkę do załadowania arkusza stylów o innej treści, niż spodziewałby się tego programista serwisu. Ostatecznie doprowadziło to do wstrzyknięcia złośliwego kodu CSS, a podatność zyskała nazwę „Path–Relative Style Sheet Import”. Uogólniając: Relative Path Overwrite jest zagrożeniem, w którym korzystając z manipulacji adresu względnego strony, staramy się zmienić jej zachowanie.
Słowem wstępu
Praktyczne wykorzystanie RPO/PRSSI wymaga połączenia kilku technik atakowania aplikacji webowych, przeglądarek oraz serwerów. W celach demonstracyjnych przeprowadzę analizę bezpieczeństwa fikcyjnej platformy sprzedaży znajdującej się pod adresem:
http://vulnerable.com/vuln.php.
Serwis testowy działa w bardzo prostym modelu – zarejestrowany sprzedawca może dodać nowy przedmiot (grę) o wskazanej nazwie do serwisu. Na stronie głównej klienci widzą listę wszystkich dostępnych gier oraz mogą zdecydować się na ich kupno – tak jak na popularnych portalach aukcyjnych.
Wygląd serwisu demonstruje rysunek 1, zaś jego kod został przedstawiony na listingach 1 oraz 2.
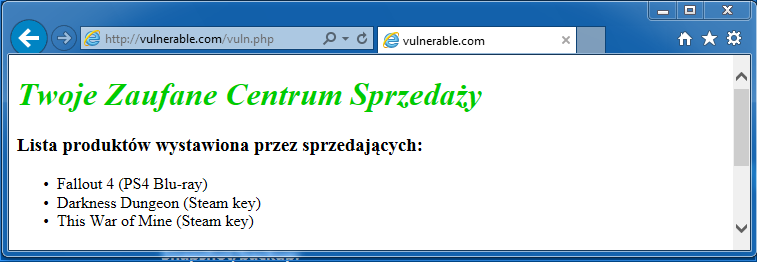
Rysunek 1. Centrum sprzedaży gier, w którym sprzedawcy mogą wystawiać produkty na sprzedaż.
<!doctype html>
<html>
<head>
<link rel=”stylesheet” href=”style.css” />
</head>
<body>
<h1>Twoje Zaufane Centrum Sprzedaży</h1>
<h3>Lista produktów wystawiona przez sprzedających:</h3>
<ul>
<li>Fallout 4 (PS4 Blu-ray)</li>
<li>Darkness Dungeon (Steam key)</li>
<li>This War of Mine (Steam key)</li>
</ul>
</body>
</html>
Zawartość pliku style.css
h1 {
color: #00CC00;
font-style: italic;
}
Gdzie szukać podatności
Podatności RPO szuka się na stronach, na których przeglądarka wysyła żądania po dodatkowe zasoby – w szczególności arkusze stylów CSS – które zostały zadeklarowane w postaci adresów względnych.
W omawianym przykładzie, niebezpieczne odwołanie znajduje się w linii 4.
<link rel=”stylesheet” href=”style.css” />
Gdy treść strony ładowana jest spod adresu http://vulnerable.com/vuln.php, arkusz stylów zostanie załadowany z adresu http://vulnerable.com/style.css.
Powyższe odwołanie do pliku CSS rozpoczyna zabawę w wykorzystanie podatności RPO. Aby jednak zrozumieć ideę ataku, najpierw musimy wiedzieć, w jaki sposób serwery WWW obsługują dynamiczne treści – takie jak skrypty PHP, JSP czy ASP – w kontekście adresów URL.
Poniższe opracowanie wykorzysta w przykładach sposób testowania wskazany wyżej, tj. dopisywanie na końcu adresu URL ciągów przypominających strukturę katalogów (/testing/example). W zależności od konfiguracji serwera, frameworka czy nawet samej aplikacji webowej istnieją także inne metody manipulacji adresem URL wywołującym opisywane zachowanie – odsyłam do lektury zasobów wskazanych w materiałach dodatkowych na końcu artykułu.
Jak serwer obsługuje adres URL
Jednym z etapów przetwarzania żądania przez serwer WWW (serwer aplikacyjny) jest podjęcie decyzji, który moduł (uchwyt, biblioteka, rozszerzenie) powinien finalnie obsłużyć żądanie. Każdy serwer robi to w odmienny sposób, ale w większości przypadków decyzja podejmowana jest na podstawie rozszerzenia zasobu, o który prosi klient. I tak: żądanie o zasób /index.php zostanie przekazane do interpretera PHP, natomiast /index.aspx trafi na pipeline ASP. Pliki typu style.css, script.js lub image.png są z reguły obsługiwane przez uchwyt plików statycznych, którego zadaniem jest odczytanie pliku z dysku i odesłanie jego treści do użytkownika.
Zgodnie z powyższym, odwiedzenie strony http://vulnerable.com/vuln.php zostanie odebrane przez uchwyt PHP, który przeczyta plik vuln.php na serwerze, prześle go do interpretera języka PHP, a odpowiedź odeśle do przeglądarki internauty.
Co ciekawe, okazuje się, że odwiedzenie strony http://vulnerable.com/vuln.php/vizzdoom oraz http://vulnerable.com/vuln.php zostanie obsłużone w dokładnie taki sam sposób – w obu przypadkach do interpretera PHP trafi zawartość pliku vuln.php. Jest to nieintuicyjne – można by się spodziewać, że pierwsze żądanie zostanie obsłużone przez uchwyt plików statycznych, który odszuka plik vizzdoom w katalogu vuln.php serwera. Tak się jednak nie stanie. I właśnie takie zachowanie w adresach URL jest wykorzystywane w podatnościach RPO/PRSSI.
Uchwyty do obsługi dynamicznej treści WWW mogą ignorować niektóre elementy adresu URL. Jest to łatwe do przetestowania na własnych serwerach – wystarczy odwiedzić adres kończący się rozszerzeniem .php, .asp, .aspx, .jsp, a następnie dopisać po nim ciąg /testing/example i przeanalizować odpowiedź.
Jak wygląda podatność RPO/PRSSI
Jeśli znamy sposób przetwarzania żądań HTTP przez serwery, nie powinno być dla nas niespodzianką, że odwołanie do adresów:
http://vulnerable.com/vuln.php,
http://vulnerable.com/vuln.php/put/evil/here
zwróci dokładnie ten sam kod HTML (listing 1) zawierający odwołanie do zewnętrznego arkusza styli:
<link rel=”stylesheet” href=”style.css” />
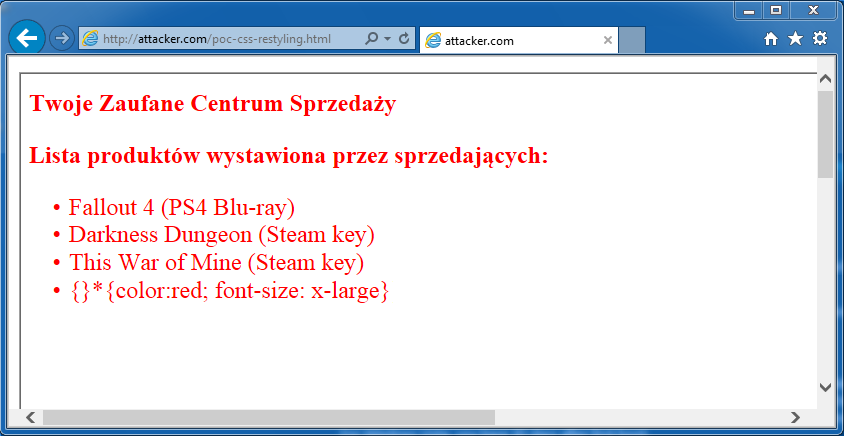
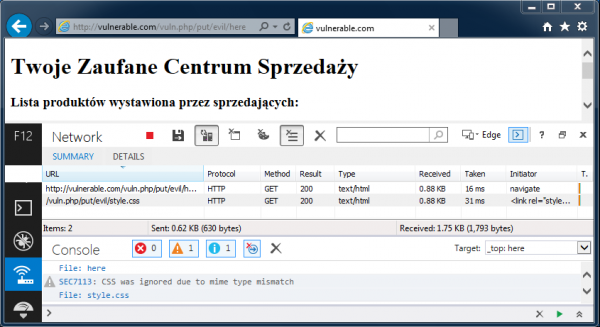
W pierwszym przypadku przeglądarka wyśle do serwera vulnerable.com żądanie HTTP GET /style.css, otrzymując w odpowiedzi selektory CSS z listingu 2, co można zobaczyć podczas analizy ruchu sieciowego (rysunek 2). W testowanej aplikacji efektem będzie wyświetlenie strony sklepu z zielonym nagłówkiem (rysunek 1).
Ciekawsze jest jednak zachowanie przeglądarki dla drugiego adresu (http://vulnerable.com/vuln.php/put/evil/here), gdyż tutaj żądanie HTTP będzie skierowane do zasobu /vuln.php/put/evil/style.css. Zamiast arkusza CSS serwer w odpowiedzi zwróci kod HTML z listingu 1, co spowoduje błędne wyświetlenie nagłówka (prawidłowy powinien być zielony, natomiast błędny jest wyświetlany inaczej) – porównaj rysunek 1 oraz 3).
Jak widać, manipulując adresem URL wpłynęliśmy na załadowanie innego zasobu, niż przewidział to programista strony (rysunek 4). W obecnej sytuacji przeglądarka wczytuje stronę vuln.php z arkuszem styli, którego zawartością jest… kod strony vuln.php.
Wstrzyknięcie źródła HTML do arkusza styli to sztandarowy przykład ataku Path–Relative Style Sheet Injection, który jest spowodowany manipulacją odwołań relatywnych (Relative Path Overwrite).
http://vulnerable.com/vuln.php/put/evil/here
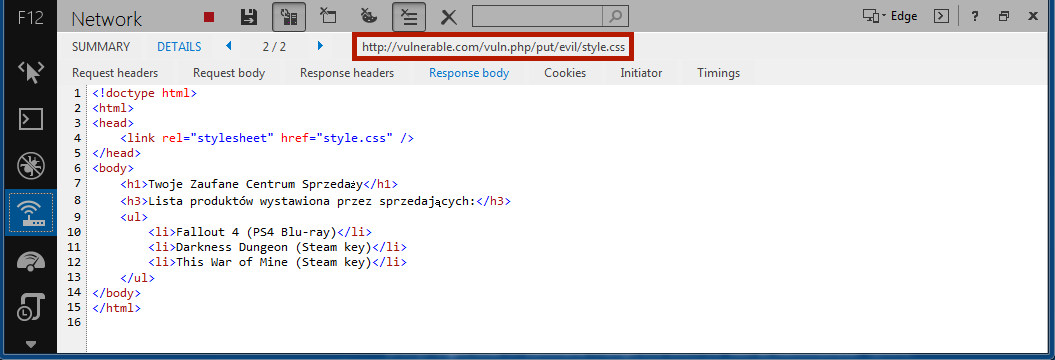
Rysunek 4. Zamiast definicji stylów (lub odpowiedzi 404 Not Found), serwer odpowiada jak na żądanie HTTP GET /vuln.php.
Warto również dodać, że błędy RPO/PRSSI od pewnego czasu są raportowane przez narzędzie Burp Suite Pro (w trybie active scan, ale czasem również w passive), co można zobaczyć na rysunku 5.
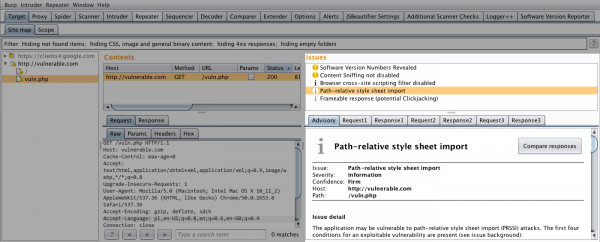
Rysunek 5. Moduł skanera Burp Suite PRO wykrywa zagrożenie manipulacji ścieżki w celu załadowania złośliwych reguł CSS i raportuje je jako “Path–relative style sheet import”.
Dostarczenie ładunku ze złośliwym kodem
Załadowanie arkusza CSS o zawartości będącej kodem HTML nie powoduje jeszcze żadnych strat. Praktyczna eksploatacja tej „podatności” to zazwyczaj bardzo skomplikowany, wieloetapowy proces.
Najpierw zastanówmy się, w jaki sposób możemy dostarczyć sam ładunek ze złośliwym kodem. Ponieważ na wejściu interpretera CSS pojawi się źródło atakowanej strony, dostarczenie payloadu jest dość proste – wystarczy w jakikolwiek sposób wpłynąć na zawartość atakowanej strony.
Można to zrobić następująco:
- manipulując parametrami URL, które wypisywane są na stronie – do czego świetnie nadają się wszelkiego rodzaju wyszukiwarki działające z parametrem ?search;
- przez dodanie nowego elementu do bazy serwisu, który później będzie wyświetlony (tzw. „Second order injection”) – jeśli nie widzimy bezpośredniej refleksji parametru URL.
Na potrzeby dalszej analizy użyję drugiej metody.
W tym celu, jako sprzedawca serwisu dodam nowy produkt, który zostanie wyświetlony na stronie głównej. Strona dość restrykcyjnie koduje kluczowe znaki HTML, zabezpieczając się przed klasycznymi atakami XSS, jednak bez problemów udaje mi się dodać przedmiot o nazwie: * {color: red; font-size: x-large}.
Warto zastanowić się, dlaczego RPO omawia się głównie w kontekście wstrzyknięć CSS – przecież relatywna ścieżka może dotyczyć skryptów JS (<script src=”script.js”>). Otóż po wstrzyknięciu na wejście interpretera Javascript trafi kod rozpoczynający się od <!doctype html> lub <html>. Spowoduje to zgłoszenie błędu składni oraz przerwanie dalszego przetwarzania „skryptu”.
Interpreter CSS jest za to bardziej tolerancyjny — w momencie napotkania błędu, może podjąć próbę dalszej interpretacji pliku (w szczególności gdy strona wyświetlana jest w tzw. „Quirks Mode”).
Ominięcie walidacji typu MIME
Na liście przedmiotów sklepu wyświetlany jest teraz szkodliwy ładunek. Odwiedzając adres z listingu 3, sprowokujemy sytuację, w której przeglądarka wczyta arkusz styli ze znacznikami HTML oraz selektorem * {color: red; font-size: x-large}. Powinniśmy spodziewać się strony, której tekst zostanie wyświetlony na czerwono.
Niestety, tak się nie stanie – współczesne przeglądarki zauważą, że arkusz CSS posiada podejrzany typ MIME (Content-Type odpowiedzi text/html). Dlatego też w konsoli Javascript przeglądarki pojawi się komunikat błędu informujący o zaprzestaniu przetwarzania podejrzanego pliku (rysunek 6).
Powyższy mechanizm zatrzyma próbę ataku we wszystkich współczesnych przeglądarkach internetowych – Firefox, Chrome, Safari, Internet Explorer – w wersjach 9–11 oraz MsEdge. Czyżby ofiarą ataku mogli być tylko użytkownicy Internet Explorer 8 (który używany jest wyłącznie w przestarzałym systemie Windows XP)? Niekoniecznie.
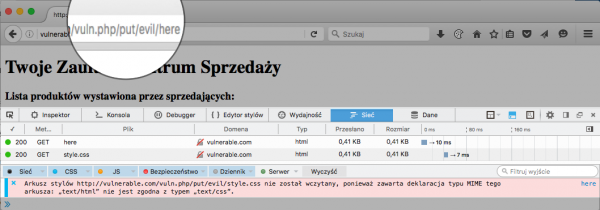
Rysunek 6. Przeglądarki mogą blokować ładowanie zasobów z podejrzanym typem MIME (powyżej: Firefox).
Przeglądarki z rodziny Internet Explorer potrafią korzystać z trybu wstecznej kompatybilności (Document Mode). W takiej sytuacji, np. IE 11, wyświetli stronę, korzystając z mechanizmów IE 8. Zachowanie takie można włączyć przez dodanie znacznika HTML <meta http-equiv=”X-UA-Compatible”> do sekcji <head>. Starsze wersje Internet Explorera nie walidują typu MIME plików CSS, więc strona wyświetlona w Document Mode IE 8 spowoduje ominięcie restrykcji dla złośliwego ładunku CSS.
W jaki sposób spowodować, aby strona http://vulnerable.com/vuln.php była wyświetlana w trybie wstecznej kompatybilności Internet Explorera? Przecież nie możemy tak po prostu zmodyfikować jej kodu i dodać tag <meta>…
Aby kontynuować atak, trzeba znać ciekawą właściwość trybu wstecznej kompatybilności IE – otóż ten tryb może być dziedziczony z dokumentu rodzica, bez restrykcji nakładanych przez reguły Same Origin Policy. Jeśli testowana strona (vuln.php) nie posiada definicji X-UA-Compatible, wartość taka może zostać pobrana z nadrzędnego kontekstu przeglądarki – czyli przykładowo – ze strony (atakującego), która zaramkuje (znacznikiem iframe) testowaną stronę.
Dalsza demonstracja ataku, omijająca restrykcje typu MIME, kierowana będzie na użytkowników Internet Explorer 11 – podczas pisania artykułu jest to przeglądarka oficjalnie wspierana i aktualizowana w systemach Windows 7/8/8.1.
Jako agresor tworzę dokument HTML na fikcyjnej domenie attacker.com, którego kod widnieje na listingu 3. Strona atakującego:
Po odwiedzeniu strony agresora w przeglądarce IE ramka będzie renderowana przy pomocy mechanizmów IE 8, gdyż ramka odziedziczy Document Mode z ramkującej strony.
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01 Transitional//EN”>
<html>
<head>
<meta http-equiv=”X-UA-Compatible” content=”IE=EmulateIE8”>
</head>
<body>
<iframe height=”500” width=”500” src=”http://vulnerable.com/vuln.php/put/evil/here”></iframe>
</body>
</html>
W ten sposób omijamy restrykcje przeglądarek, które odrzucają próbę załadowania arkusza CSS z nagłówkiem Content-Type: text/html.
Chociaż w ten sposób uda nam się ominąć restrykcje IE 11 dla typu MIME, atak dalej się nie powiedzie. Zawartość ramki nadal nie zawiera strony z czerwonymi napisami, co oznacza, że ładunek * {color: red; font-size: x-large} mimo poprawnego załadowania – nie zadziałał.
Oszukanie parsera CSS
W sekcji „Dostarczenie ładunku ze złośliwym kodem” wspomniałem, że parser CSS nie jest tak restrykcyjny, jak interpreter Javascript. Niestety, nie jest on na tyle liberalny, aby poprawnie zinterpretować linię:
<li>* {color: red; font-size: x-large}</li>
Znaczniki <li></li> pojawiają się w kodzie strony, gdyż każdy dodawany w serwisie przedmiot jest elementem nieuporządkowanej listy HTML. Refleksja tego przedmiotu jest ujęta w znaczniki <li>, które nie są poprawnym selektorem CSS. Parser zauważy ten błąd i przejdzie do analizy reszty (wstrzykniętego) pliku.
Aby wstrzyknięcie złośliwych właściwości CSS doszło do skutku, należy lekko zmodyfikować nasz ładunek. W tym celu dodajemy do serwisu przedmiot, który zaczyna się od znaków {}, po których dodajemy złośliwy selektor (*, body, p lub dowolny inny) wraz z definicjami. Wówczas otrzymamy:
<li>{}* {color: red; font-size: x-large}</li>
Pierwsza (czerwona) część zostanie zinterpretowana jako niepoprawny selektor o pustej liście właściwości. Parser odrzuci tę część i spróbuje znaleźć kolejny, poprawny fragment. Znak gwiazdki jest poprawnym selektorem CSS, dlatego zielona część zostanie wzięta pod uwagę przez przeglądarkę. Pozostała część pliku jest nieistotna, ponieważ udało się nam już wstrzyknąć to, co chcieliśmy.
W tym momencie, ofiara odwiedzająca domenę attacker.com, zobaczy ramkę z zawartością vuln.php z czerwonym, powiększonym tekstem – co potwierdza udane wstrzyknięcie CSS (rysunek 7).
W końcu sukces!
Rysunek 7. Udane wstrzyknięcie kodu CSS na testowanej stronie.
Aby urealnić atak, możemy pokusić się o załadowanie złośliwego obrazka oraz dopisanie własnego tekstu w określone miejsca strony. Ładunek wykonujący te operacje przedstawia listing 5, zaś jego efekt można zobaczyć na rysunku 8.
<li>{}*{color:red; font-size: x-large}ul li:after{content:” (TEN SPRZEDAWCA TO OSZUST!)”}body{background-image:url(‘http://static.fjcdn.com/pictures/I+am+offensive+and+i+find+this+black+come_3d9dcc_3223497.jpg’);}</li>
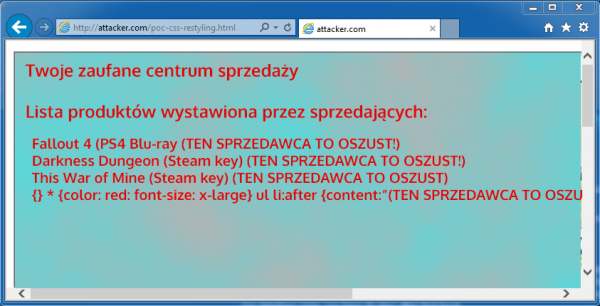
Rysunek 8. Demonstracja udanego wektora ataku. CSS Injection pokazany w IE11 dzięki ramkowaniu, Relative Path Override oraz trybie kompatybilności wstecznej przeglądarki.
XSS przez CSS, czyli długa droga do groźnej podatności
Atak na wizerunek korporacji może być smacznym kąskiem dla agresora, jednak w większości wypadków, tak skomplikowane działania powodujące zmianę wyglądu strony, nie będą się opłacały. Co innego, gdyby przez manipulację stylu można było wykonać dowolny kod Javascript. Czy XSS przez CSS Injection jest dzisiaj jeszcze możliwy?
W Internet Explorer 7 pojawiły się dynamiczne właściwości CSS, zwane również CSS Expressions (dynamic properties). W Internet Explorer 8–10 już z nich zrezygnowano, ale Expressions dalej działały w nich w trybie wstecznej kompatybilności. Od razu na myśl przychodzi zaramkowanie strony w starym Document Mode i wywołanie XSS przez wstrzyknięcie CSS Expression. Microsoft jednak całkowicie usunął dynamiczne właściwości CSS w IE 11 i taki atak nie jest już możliwy.
Internet Explorer (w odróżnieniu od MsEdge) nadal wspiera inne, „egzotyczne” mechanizmy, które mogą pomóc nam w ataku. Jednym z takich mechanizmów jest DHTML Behaviors – wprowadzony w IE 5.5, działający aż do IE 10 (oraz w Document Mode w najnowszej wersji Internet Explorer). W tym mechanizmie właściwość CSS może odwoływać się do pliku skryptletu (.sct scriptlet), który może wykonać kod Javascript.
Aby skryptlet zadziałał, musi znajdować się na tej samej domenie, co ładujący go arkusz styli. W dodatku plik skryptletu musi zwracać w odpowiedzi HTTP typ MIME text/x-scriptlet. Są to spore utrudnienia dla atakującego, ale postaramy się je obejść.
Zacznijmy od tego, co już potrafimy – ramkujemy stronę http://vulnerable.com/put/evil/here i wstrzykujemy styl CSS przez dodanie produktu o następującej nazwie:
{}*{color:red;}body{behavior: url(„/ODWOLANIE-DO-SCRIPTLETU“)}
Działanie właściwości behavior będzie zaimplementowane w skryptlecie. Ramka w domenie atakującego jest tu potrzebna, aby strona obsłużyła wstrzyknięcie CSS oraz włączyła archaiczny mechanizm skryptletów.
Następnie tworzymy sam skryptlet. Dla demonstracji jego implementacja będzie pokazywać informację w kontekście jakiej domeny wykonano atak XSS (listing 6).
<scriptlet>
<implements type=”behavior”/>
<script>alert(“scriptlet XSS on “ + document.domain)</script>
</scriptlet>
Teraz musimy zadbać o załadowanie tego pliku na serwer. Mogą w tym pomóc funkcje serwisu związane z dodawaniem nowych obrazków lub awatarów. Dla uproszczenia załóżmy, że możemy wgrać dowolny plik o rozszerzeniu .png na domenę vulnerable.com. Zapisujemy więc scriptlet jako plik xss.png i ładujemy go na stronę.
Ostatnim krokiem będzie ominięcie wymagania odnośnie typu MIME skryptletu. Serwer, zwracając plik http://vulnerable.com/xss.png, nie odpowie nagłówkiem Content-Type: text/x-scriptlet, co uniemożliwi uruchomienie właściwości behavior w CSS. Aby obejść to zabezpieczenie, atakujący musi skorzystać z kolejnej słabości przeglądarki – tym razem będzie to Content Sniffing.
Content Sniffing to mechanizm, który pozwala przeglądarce określić, w jaki sposób ma przetworzyć plik, niezależnie od jego wartości Content-Type. Coś, co jest obrazkiem (image/png), może więc okazać się stroną HTML, skryptem lub innym zasobem.
Internet Explorer aktywuje Content Sniffing m.in. podczas przetwarzania odpowiedzi HTTP z nagłówkiem Content-Type o wartości:
- text/html,
- text/plain,
- image/*,
- video/mpeg,
- video/avi.
Zgodnie z powyższym, gdy załadujemy obrazek http://vulnerable.com/xss.png, przeglądarka otrzyma odpowiedzi z nagłówkiem Content-Type: image/png, więc włączy mechanizm Content Sniffing. Analizując odebrane dane, Internet Explorer wykryje, że faktyczną zawartością ładowanego zasobu jest plik o typie MIME text/x-scriptlet.
Mamy już więc wszystkie elementy układanki. Skutecznie wykonany atak XSS w kontekście vulnerable.com będziemy mogli zobaczyć po wykonaniu następujących kroków:
- dodanie produktu o nazwie z listingu 7,
- załadowanie skryptletu xss.png,
- odwiedzenie strony w domenie attacker.com.
Końcowy efekt demonstruje rysunek 9.
{}*{color:red;}body{behavior: url(„/xss.png“)}
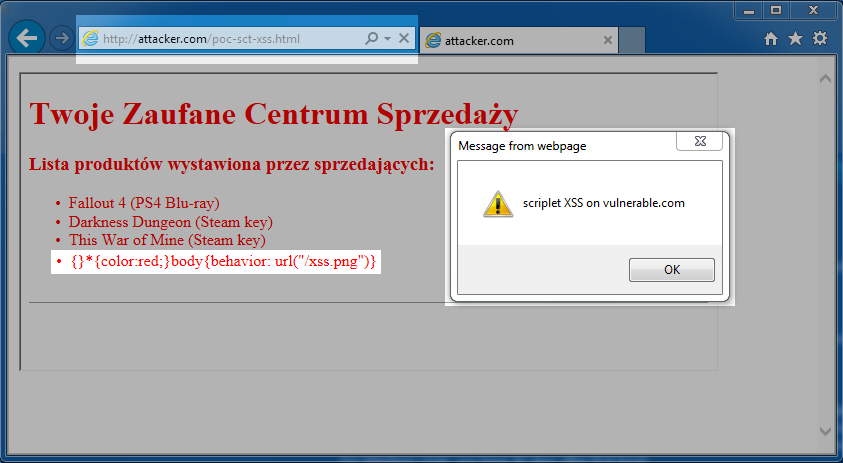
Rysunek 9. XSS przez CSS Injection w Internet Explorer 11 – upragnione wykonanie złośliwego kodu Javascript.
Podsumowanie i wnioski z ataku
Cały wektor ataku, skutkujący wykonaniem złośliwego kodu Javascript w domenie vulnerable.com, wygląda następująco:
- Zauważamy, że vulnerable.com jest podatne na atak RPO.
- Wykorzystujemy RPO (http://vulnerable.com/put/evil/here) w celu załadowania pliku style.css o zawartości strony vuln.php.
- Wpływamy na treść strony, dodając produkt o nazwie z listingu 7. Ładunek posiada właściwość CSS behavior, której implementacja znajduje się w pliku xss.png.
- Dodajemy obrazek na atakowanej stronie, którego zawartością jest skryptlet z listingu 6.
- Na domenie attacker.com tworzymy stronę poc-sct-xss.html.
- Dodajemy do niej ramkę ze stroną z punktu 2.
- Do ramkującej strony dodajemy tag X-UA-Compatible, który spowoduje wyświetlenie strony poc-sct-xss.html w trybie IE 8 – pozwoli to m.in. na przetwarzanie skryptletów oraz ominięcie walidacji typów MIME.
Nakłaniamy ofiarę, aby odwiedziła domenę attacker.com przy użyciu dowolnej wersji Internet Explorer. Atak XSS wykona się w kontekście vulnerable.com.
Warto nadmienić, że w trakcie pisania artykułu (początek 2016 roku), udział wersji Internet Explorera na rynku przeglądarek, na których zadziała powyższy wektor ataku, waha się w przedziale 5–40% (w zależności od źródeł).
Jak się chronić
Sugerowaną przeze mnie metodą ochrony przeciwko atakom RPO jest dodanie znacznika HTML <base href=”http://example.com/” />. Jego celem jest definiowanie ścieżki bazowej dla wszystkich elementów „relatywnych” na stronie, co zatrzymuje pierwszy etap ataku. Aby nie pozwolić na nadpisanie wartości elementu base podczas wstrzyknięć, strona powinna dodatkowo nakładać obostrzenia Content Security Policy dyrektywą base-uri (więcej o CSP w artykule na str. 8-19).
Uwaga: Znacznik <base> musi być jednym z pierwszych elementów sekcji head, jeszcze przed odwołaniami do styli oraz skryptów.
Remedium na skomplikowane wektory ataków jest dobra jakość kodu oraz wdrażanie metod dogłębnej ochrony (ang. defense in depth). Dlatego, aby uchronić się przed tego rodzaju zagrożeniami, należy w aplikacji webowej:
- deklarować <!DOCTYPE html> w pierwszej linii odpowiedzi strony HTML,
- nie pozwalać na „ramkowanie” strony (używaj nagłówków X-Frame-Options oraz Content-Security-Policy z dyrektywą frame-ancestors),
- wyłączyć mechanizm Content Sniffing (nagłówek X-Content-Type-Options: nosniff),
- uniemożliwić dziedziczenie trybu wstecznej kompatybilności w IE – dodaj znacznik <meta http-equiv=”X-UA-Compatible”content=”IE=Edge”> (Edge oznacza tu najnowszą wersję Internet Explorer, a nie tryb „Microsoft Edge”),
- zwracać poprawny typ MIME oraz informacje o kodowaniu (np. UTF8) w nagłówkach Content-Type.
W poprawieniu jakości kodu mogą pomóc automaty do statycznej analizy.
Podsumowanie
Relative Path Override to łatwe w wykryciu zagrożenie, jednak wyrządzenie realnych szkód przy pomocy tej podatności wymaga sporo wysiłku. Obecne przeglądarki internetowe są coraz bezpieczniejsze i stopniowo utrudniają wykorzystanie takiej luki. Nie zapominajmy, że doświadczony atakujący przy pomocy RPO/PRSSI może próbować:
- wpływać na wygląd strony przez CSS (co może skutkować utratą wizerunku, czasem też niedostępnością serwisu),
- wykradać tokeny anty-CSRF (przez co atakujący będzie mógł nakłonić zalogowanego użytkownika do wykonania określonych akcji na stronie),
- wykradać zawartość URL, np. identyfikatory sesji (co grozi przejęciem konta zalogowanego użytkownika),
- czy nawet wykonać XSS (kradzież identyfikatora sesji, kradzież haseł przez keyloggery webowe i wiele innych…).
Jak widać, błędy RPO mogą stymulować poważne podatności – taka sytuacja dotyczyła chociażby forum phpBB 3 lub frameworku Cake PHP. Dlatego też nie powinniśmy lekceważyć tego zagrożenia i uwzględniać RPO/PRSSI jako element testów bezpieczeństwa aplikacji webowej.
Źródła i materiały dodatkowe
—Adrian ‘Vizzdoom’ Michalczyk


{kind=link}
Uwaga: Wpis zawiera lokowanie produktów.
Na sekuraku to juz standard :-)
Jakiś @złośliwy komentarz zawsze się trafi, ale przyjemniej czyta się teksty techniczne, które chociaż próbują pokazać przykłady na uproszczonych wersjach środowisk, które mogą zostać wdrożone.
Gdyby wszędzie były przykłady z itemami w stylu [Placeholder1], [Placeholder2] na localhoście, to byłoby @nudno i @nieciekawie ;-)
Może zamiast o przykładowych produktach lepiej pomyśleć i porozmawiać o opisywanej podatności? ;-)
internet explorer? meh
Ot ciekawostka. Kolejny przykład na to, że nie warto czasem szczędzić kilku sekund z lenistwa i jednak warto mieć “nadmiar” meta tagów dla bezpieczeństwa marki.
Serio? Zachęcić ofiarę, żeby odwiedziła inną domenę niż atakowana i stawać na głowie, że wykorzystać jakieś archaiczne funkcje IE poprzez umieszczenie atakowanej domeny w iframe o.O? Przecież po skłonieniu ofiaru na odwiedzenie naszej domeny wystarczy zapodać jej exploit-kita za 20$ i czerpać profity.
A tak serio bardzo naciągany artykuł, żeby udowodnić, że coś na kształt “słabości” może być podatnością w skrajnych warunkach. Mnie nie przekonało.
Adrianie, wróć do rzeczywistości.
Można zaatakować “bejzbolem” i przy pomocy “kolegów” i czerpać profity, można bardziej w stylu “Panama Papers”. Podsumowanie komentarza mnie nie przekonało (powiało typową dla internetowych komentarzy płycizną, nawet jeśli xionc zna Adriana i widzi go dzień w dzień) :P
“wystarczy zapodać jej exploit-kita za 20$ i czerpać profity.” Booże… co za sebix hackerstwa.
Masz troche racji.
Dodam jeszcze, ze (calkowicie szczerze i bez ironii) bardzo sie ciesze z dojrzalej postawy i tego, ze dopuszczacie przez moderacje nawet nie przychylne Wam komentarze, czego nie mozna powiedziec o innej polskiej stronie nt “bezpieczestwa i nie tylko” , gdzie banuja nawet IP byle by nie dopuscic takiego komentarza :-)
styl -lu; -le, -lów