Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej
Wystartowała Akademia NIS2/KSC2! Można jeszcze dołączyć do końca lipca!
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
Bezpłatne szkolenie: AI dla admina. Top 5 zadań, które zrobisz szybciej

Rozpatrzmy rozwiązanie alternatywne do opensource: dedykowana, napisana od podstaw aplikacja internetowa. Podejście to ma tak samo wielu zwolenników, jak i przeciwników. Jako argumenty przeciw często przytacza się powiedzenie, że nie wymyśla się koła na nowo (jeśli coś jest już dostępne, i w dodatku jest to darmowe, jak Joomla!, WordPress czy Magento – czemu z tego nie skorzystać), że to drastycznie podnosi koszty wdrożenia takiej aplikacji oraz jej późniejszego utrzymania. Trudno się nie zgodzić ze słusznością tych stwierdzeń.
Spróbujmy znaleźć argumenty przemawiające jednak za zrealizowaniem takiego projektu:
Jest także druga strona medalu. Powierzając budowę systemu od podstaw, eliminujemy niektóre zalety rozwiązań opensource:
Pierwszy punkt możemy spróbować wyeliminować odpowiednio definiując politykę zabezpieczeń, jakie musi posiadać nasz serwis. Będziemy się tutaj kierować wytycznymi, jakie zostaną ustalone na etapie analizy tych wymagań (omówię go w następnej części niniejszego opracowania). W zależności od przyjętego poziomu wg. ASVS dedykowana aplikacja powinna zostać poddana testom weryfikującym, czy ten poziom osiągnęła. Najlepiej by odbywało się to już na poziomie jej tworzenia, by ograniczyć późniejsze modyfikacje (czyli obniżyć przyszłe koszty wsparcia). Przykładowo – raz zaimplementowany, restrykcyjny mechanizm autoryzacji i zarządzania uprawnieniami użytkowników będzie działał zgodnie z oczekiwaniami niezależnie od tego, czy aplikacja rozrośnie się o dodatkowe moduły, czy też zwiększy się liczba użytkowników systemu.
W celu osiągnięcia maksymalnego możliwego stopnia bezpieczeństwa możemy posłużyć się dodatkowymi narzędziami i bibliotekami. W przypadku dedykowanej aplikacji mamy nieco “łatwiej”, bo nie wymaga integrowania wybranej biblioteki w już działającym systemie (co pociąga za sobą bardzo żmudny i kosztowny proces, dodatkowo obarczony ryzykiem przeoczenia czegoś istotnego). Możemy od samego początku budować aplikację z wykorzystaniem takiego rozwiązania.
Jednym z nich jest kolejny projekt prowadzony przez OWASP – ESAPI (OWASP Enterprise Security API). ESAPI jest gotową biblioteką, której zadaniem jest zapewnienie kompleksowego bezpieczeństwa niezależnie od wybranej infrastruktury i technologii. Jak można się przekonać, zaglądając na stronę projektu, ESAPI jest wieloplatformową biblioteką, dystrybuowaną na licencji BSD i wykorzystywaną przez m.in. American Express, Apache Foundation, Lockheed Martin, MITRE, U.S. Navy czy SANS Institute.
Spójrzmy pokrótce na to, co biblioteka nam zapewnia (przykład pochodzi z tej strony):
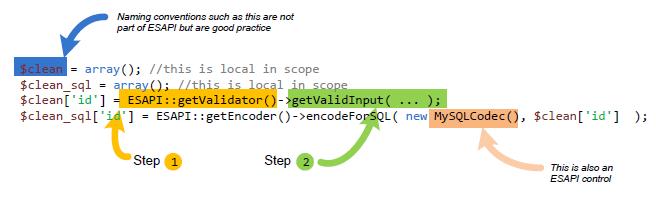
W punktach oznaczonych jako 1 i 2 widzimy, w jaki sposób jest zapewniona prawidłowa walidacja danych wejściowych (w tym wypadku chodzi o identyfikator ‘id’, pochodzący np. z żądania HTTP GET lub POST). Wymusza to prawidłowy typ zmiennej, przekazywanej dalej do zapytania SQL (kolejna linijka, w której ESAPI zadba, by dane zostały zapisane w bazie dokładnie w takim formacie, w jakim tego oczekujemy). Nie ma możliwości wykonania ataku SQL Injection polegającego na doklejeniu instrukcji SQL do zmiennej ‘id’ i wymuszenia wykonania ich przez serwer bazodanowy.
Oczywiście istnieją inne metody zabezpieczenia aplikacji przed różnego rodzaju atakami. Jednak takie gotowe rozwiązanie jak ESAPI, pozwala nam zdjąć z barków programistów ciężar polegający na implementacji takich mechanizmów od podstaw, dodatkowo zapewniając, że zastosowane zabezpieczenia są sprawdzone i działają zgodnie z oczekiwaniem. Dużym atutem jest też dostępność ESAPI dla aplikacji budowanych w oparciu o technologie Java Enterprise Edition czy ASP.NET
CRACKER –> ESAPI –> aplikacja/biblioteki własne frameworka (np. ZF, Symfony) –> DANE (serwer SQL)
Spróbujmy jeszcze bardziej utrudnić zadanie potencjalnemu włamywaczowi i zastosujmy dodatkowe zapory na drodze do danych. PHPIDS (PHP-Intrusion Detection System – PHPIds ) to kolejna biblioteka PHP, realizująca tym razem zadania firewalla i systemu IDS – Intrusion Detection System (system wykrywania włamań). W przeciwieństwie do ESAPI, której zadaniem jest walidacja danych już otrzymanych, PHPIDS dba o to, by dane, co do których zachodzi podejrzenie, że zawierają niebezpieczne payloady, w ogóle do aplikacji nie dotarły.
Każdy incydent jest przez PHPIDS identyfikowany przez zestaw ok. 50 gotowych wzorców najpopularniejszych ataków i po wykryciu takiego wzorca podejmowana jest decyzja o reakcji – np. zapisaniu próby ataku do logu. Dzięki temu możemy później przeanalizować, w jaki sposób cyberprzestępcy próbują spenetrować nasz serwis i odpowiednio zmodyfikować np. reguły filtrowania danych, reguły firewalla czy wręcz przeprojektować fragment aplikacji szczególnie narażony na ataki.
Użycie PHPIds jest nieskomplikowane: po pobraniu biblioteki włączamy ją do kodu w standardowy sposób:
<code>
require_once 'IDS/Init.php';
$request = array( 'REQUEST' => $_REQUEST, 'GET'
=> $_GET, 'POST' => $_POST, 'COOKIE' => $_COOKIE );
$init = IDS_Init::init('IDS/Config/Config.ini');
$ids = new IDS_Monitor($request, $init);
$result = $ids->run();
</code>
CRACKER –> PHPIds –> ESAPI –> aplikacja/biblioteki własne frameworka (np. ZF, Symfony) –> DANE (serwer SQL)
W tym momencie wykonanie jakiegokolwiek ataku z poziomu błędów w kodzie aplikacji staje się skrajnie trudne. Zajmijmy się zatem najsłabszym ogniwem każdego systemu – użytkownikami.
Pamiętajmy, aby stworzyć możliwie silny mechanizm autentykacji. Hasła nie mogą być zapisane w bazie danych w postaci jawnej, nie zapisujmy ich też w miarę możliwowści w postaci popularnych skrótów MD5 lub SHA1 – istnieją miliony takich skrótów, które bez trudu można znaleźć w internecie i “dopasować” je do wykradzionych z naszej bazy. Jeśli taki skrót nie został do tej pory dodany, cracker może posłużyć się choćby tęczowymi tablicami (How Rainbow Tables work) lub przykładowej alternatywy (Alternatywa dla tęczowych tablic).
Przykładowym rozwiązaniem może być dodanie do skrótu SHA1 hasła przykładowo skrótu MD5 daty rejestracji użytkownika (jako tzw. sól), co w rezultacie da nam 72-znakowy ciąg. Z niego z kolei możemy wyciąć 64 znaki począwszy od piątego. Jest to tylko przykład, a szczegółowa implementacja rozwiązania należy już do programistów tworzących system, bądź może być zrzucona na barki dodatkowych bibliotek (jak np. omawiana wcześniej ESAPI).
Funkcja skrótu, inaczej: funkcja mieszająca lub funkcja haszująca – jest to funkcja, która przyporządkowuje dowolnie dużej liczbie krótką, zwykle posiadającą stały rozmiar, nie specyficzną, quasi-losową wartość, tzw. skrót nieodwracalny.
W informatyce funkcje skrótu pozwalają na ustalenie krótkich i łatwych do weryfikacji sygnatur dla dowolnie dużych zbiorów danych. Sygnatury mogą chronić przed przypadkowymi lub celowo wprowadzonymi modyfikacjami danych (sumy kontrolne), a także mają zastosowania przy optymalizacji dostępu do struktur danych w programach komputerowych (tablice haszujące).
za: Wikipedia
Pamiętajmy, by formularze logowania czy przypominania hasła nie dawały jasnej wskazówki, czy podane zostało błędne hasło, czy login.
Umożliwia to bowiem tzw. enumerację nazw użytkowników systemu, a to już połowa sukcesu na drodze do udanego ataku “password quessing” – zgadywania hasła, lub “brute force” – ataku siłowego, polegającego na kolejnych próbach logowania na poznaną nazwę użytkownika z użyciem gotowej listy haseł – tzw. atak słownikowy, bądź losowego generowania haseł – klasyczny atak siłowy na hasło.
Dzięki takiemu zabezpieczeniu opóźniajmy o klika sekund kolejne nieudane próby autoryzacji, blokujmy możliwość zalogowania się po np. pięciu nieudanych próbach – wszystko to sprawi, że atak na mechanizm autoryzacyjny stanie się bardzo czasochłonny i w praktyce niemożliwy do przeprowadzenia. Oto typowy przykład mechanizmu autoryzacji, który w pozornie wydawałoby się prawidłowych komunikatach sygnalizuje występowanie bądź brak użytkownika o podanym loginie:
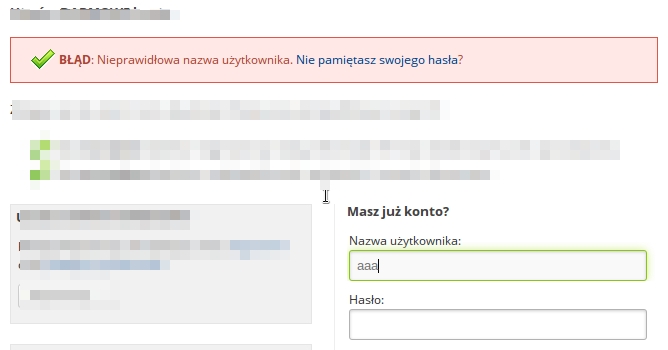
Postarajmy się, by wszystkie adresy url, które są nieprawidłowe i nie kierują do określonego zasobu, ostatecznie przekierowywały na stronę z informacją o tym, że dany adres nie został znaleziony (ale zróbmy to w taki sposób, by informacja ta dotyczyła zarówno typowych “literówek”, jak i celowych prób mających na celu zbadanie reakcji aplikacji na manipulowanie parametrami żądania).
Na poniższym zrzucie ekranu widać, jak zachowuje się serwer WWW Apache z włączonym wyświetlaniem (raportowaniem) błędów:
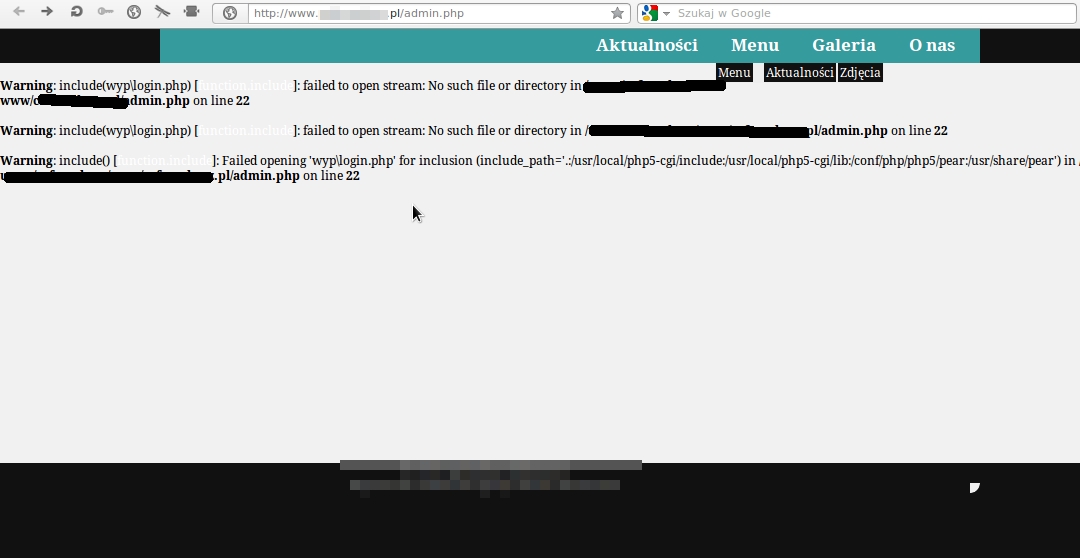
Z pozoru nieistotne informacje mogą dać potencjalnemu włamywaczowi orientację w strukturze katalogów aplikacji, zastosowanej konwencji nazw plików czy odkryć zasoby, do których nie ma bezpośredniego dojścia z poziomu serwisu. Wprawnemu włamywaczowi te informacje pozwalają szybko zorientować się również w rodzaju frameworka, który wykorzystano w kodzie atakowanego systemu, co często nie jest możliwe bez wyraźnej wskazówki.
W przypadku aplikacji napisanej w języku PHP wyłączenie wyświetlania błędów sprowadza się do modyfikacji pliku konfiguracyjnego php.ini (w przypadku serwerów opartych na dystrybucjach Debian będzie to plik w katalogu /etc/php5/apache2/, w innych systemach należy posłużyć się dokumentacją). Przykładowy fragment tego pliku przedstawia poniższy listing (wydruk z programu vim):
<code> ; 505 ; Common Values: 506 ; E_ALL & ~E_NOTICE (Show all errors, except for notices and coding standards warnings.) 507 ; E_ALL & ~E_NOTICE | E_STRICT (Show all errors, except for notices) 508 ; E_COMPILE_ERROR|E_RECOVERABLE_ERROR|E_ERROR|E_CORE_ERROR (Show only errors) 509 ; E_ALL | E_STRICT (Show all errors, warnings and notices including coding standards.) 510 ; Default Value: E_ALL & ~E_NOTICE 511 ; Development Value: E_ALL | E_STRICT 512 ; Production Value: E_ALL & ~E_DEPRECATED 513 ; http://php.net/error-reporting 514 <strong> error_reporting = E_ALL & ~E_DEPRECATED </strong> 515 (...) 523 ; Possible Values: 524 ; Off = Do not display any errors 525 ; stderr = Display errors to STDERR (affects only CGI/CLI binaries!) 526 ; On or stdout = Display errors to STDOUT 527 ; Default Value: On 528 ; Development Value: On 529 ; Production Value: Off 530 ; http://php.net/display-errors 531 <strong> display_errors = Off </strong> </code>
Dla serwera www Apache także można ustawić odpowiednie dyrektywy w pliku .htaccess:
# supress php errors
php_flag display_startup_errors off
php_flag display_errors off
php_flag html_errors off
Należy zwrócić uwagę także na to, że być może w przyszłości aplikacja będzie działała na innym serwerze WWW, np. nginx. Serwer ten nie obsługuje plików .htaccess Apache’a i może doprowadzić do udostępnienia informacji przykładowo o dostępie administracyjnym z określonych adresów IP. Poniższy zrzut ekranu ukazuje możliwość pobrania i odczytania pliku .htaccess serwisu uruchomionego na serwerze nginx (prawdopodobnie właśnie po przeniesieniu aplikacji z serwera Apache bez żadnych modyfikacji):
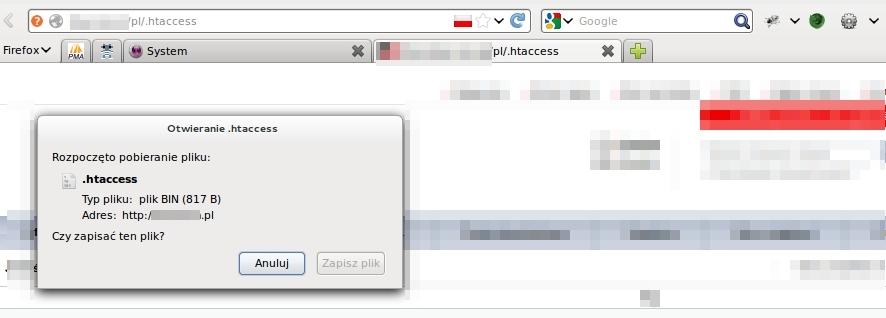
W pliku tym znajduje się między innymi wspomniany powyżej wpis w postaci dyrektywy dla serwera Apache o dostępie bez autoryzacji HTTP z dwóch konkretnych adresów IP. Przykład jest autentyczny i dotyczy jednej z bardzo dużych firm, posiadającej swoje oddziały w całym kraju oraz prowadzącej sklep internetowy.
Przedstawione tu przykłady to tylko czubek góry lodowej. Poziom zabezpieczeń musi być także dostosowany do oczekiwań (pomóc nam w tym może poprzedzająca proces wytwarzania aplikacji analiza według wskazówek ASVS, o czym w kolejnej części opracowania).
Z jednej strony, nie warto implementować wyszukanych zabezpieczeń w statycznej wizytówce utworzonej w HTML-u. Z drugiej strony, należy też pamiętać, że żadne, ale to absolutnie żadne zabezpieczenie nie gwarantuje nam stuprocentowego bezpieczeństwa.
C.D.N.
– Rafal “bl4de” Janicki [bloorq<at>gmail.com]

Znowu trochę posłodzę – artykuł ciekawy i w ogóle merytoryczny.
Uważam jednak, że o wiele bezpieczniej jest używać mechanizmów sprawdzonych przez setki a czasem tysiące osób, takich, które są codziennie testowany przez crackerów z całego świata niż własnoręcznie stworzonego nawet przez osoby kumate i rzetelne. Pomijam już kwestię dostępu do takich osób np. na rynku PHP, gdzie próg wejścia do branży jest bardzo niski i dzieciaki z podstawówek uważają się za programistów po przeczytaniu książki “PHP i MySQL – przedruk, edycja 20”.
No ale w zasadzie w artykule zostało to opisane.
Arty – Kozak seria. Z niecierpliwością czekam na jeszcze !
Sekurak zaliczył awans do TOP10 u mnie !
Cała seria bardzo ciekawa, chcę więcej. Dobra robota “bl4de”.
@MateuszM
Całkowicie się z Tobą zgadzam. Stąd moje wskazówki, by w razie tworzenia aplikacji dedykowanej korzystać ze sprawdzonych frameworków (ZF, Symfony – tworzą je ludzie naprawdę mający pojęcie o temacie, dodatkowo zgodnie ze sztuką: testy, code reviews, osobne branche developerskie i produkcyjne, możliwość zgłaszania własnych poprawek poprzez system pull requestów w GitHub’ie, bugtrackery itd.).
To samo dotyczy OWASP ESAPI czy PHPIds. Każde z tych rozwiązań ma na celu wspomóc developerów w procesie tworzenia bezpiecznego oprogramowania.
Wbrew obiegowym opiniom w PHP też da się tworzyć soft na wysokim poziomie. Separacja warstw, wzorce architektoniczne czy projektowe, właściwa komunikacja client-server, Web Services, RESTful, kontrola uprawnień, właściwa architektura infrastruktury serwerowej – można wymieniać bez końca.
Faktycznie trudno oczekiwać wiedzy na tym poziomie od wspomnianych przez Ciebie “podstawówkowiczów”, bo to przychodzi wraz z latami doświadczenia z produkcyjnym kodem, setkami tysięcy wyklepanych linijek kodu i zmagania się z mnóstwem realnych sytuacji, o których w takich pozycjach, jak “PHP w 10 minut” nikt się nawet nie zająknie :)
@Ko7a, @OiSiS
Dziękuję :)
W chwili obecnej każde użycie SHA-1 i MD5 wiąże się z niebezpieczeństwem, gdyż wszystko co najpopularniejsze – jest łakomym kąskiem. Warto zainteresować się rozwiązaniami, które są jeszcze nie popularne, jak sCrypt.
@józek – apropos innych algorytmów tego typu: http://sekurak.pl/kompendium-bezpieczenstwa-hasel-atak-i-obrona/
Dodalibyście edycję postów ;)
Ciekawymi rozwiązaniami są też metody podwójnego kodowania. Np. najpierw kodowanie do przykładowo sCrypta, a następnie prosta funkcja XORująca z 12 znakowym kluczem przetrzymywanym w pamięci. Oczywiście zwiększa to zużycie pamięci, ale dodatkowa kostka dzisiaj to niewielki wydatek.
@józek
Racja, MD5 i SHA1 dzisiaj już nie wystarczą. Dlatego też w wymaganiach ASVS na wyższych poziomach wymagane są dodatkowe mechanizmy (np. wykorzystanie salt’a).
Dokładnie, wraz z przykładami w realnym kodzie (zarówno dobrymi przykładami, jak i złymi) opisałem to w nieopublikowanej jeszcze 4. części artykułu :)