Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Zabbix + Grafana – część 2 – Przedstawianie danych
Ten tekst został przygotowany dla Zabbix 7.0 oraz Grafana 12.1.
Wstęp
Świat ciągle idzie naprzód — nie ominęło to również środowiska Zabbix, które w ciągu ostatnich kilku lat mocno się rozwinęło, także pod kątem prezentacji danych. Liczba dostępnych dzisiaj widżetów oraz możliwości ich konfiguracji sprawiają, że można spotkać się z takimi opiniami:
“Na co mi grafana, bez sensu utrzymywać kolejny system, Zabbix jest wystarczający”
“Grafana niby ładnie wygląda, ale w Zabbix też mogę wyświetlić podobny wykres”
“Widzę, że sąsiad wdrożył sobie Grafanę. Ja tam wolę mieć kontrolę nad swoim monitoringiem #Nosacz”
Autor nie zamierza spierać się z tym podejściem — dla wielu użytkowników dashboardy w Zabbix będą w zupełności wystarczające do wizualizacji danych. Autor nie chce też skupiać się na takich zaletach jak wiele źródeł danych lub (według autora) prostsze budowanie dashboardów w Grafanie.
W tym artykule, na przykładzie tworzenia dashboardów, autor chce pokazać, że Grafana pozwala w prosty sposób osiągnąć efekty wizualizacyjne, które w natywnym Zabbixie są trudno dostępne. Choć Zabbix daje możliwość rozbudowy poprzez własne widżety, w praktyce wymaga to kompetencji programistycznych, co nie zawsze jest rozwiązaniem dostępnym dla każdego administratora.
W poprzednim >artykule pokazaliśmy, jak zintegrować oba systemy, tak aby dane z monitoringu były dostępne bezpośrednio w Grafanie. Dzisiaj skupimy się na stworzeniu dashboardu z “nieoczywistymi” panelami. Warto spojrzeć też na starszy >artykuł, gdzie zostały przedstawione bardziej podstawowe panele.
Zaczynamy!
Ten artykuł to część serii przybliżającej integrację Grafany oraz Zabbixa przygotowanej przez Alberta Przybylskiego. Zachęcamy do zapoznania się ze wszystkimi tekstami dotyczącymi tego zagadnienia!
1. Zabbix + Grafana – część 1 – instalacja
2. Zabbix + Grafana – część 2 – Przedstawianie danych
3. Zabbix + Grafana – część 3 – Przedstawianie danych – przykłady zaawansowane
4. Zabbix + Grafana – część 4 – Pobieranie danych z DB
Szybka powtórka
Na tym etapie zakładamy, że mamy świeżą instalację Grafany na osobnym serwerze, oraz podłączony serwer Zabbix za pomocą oficjalnego pluginu. Dla przypomnienia:

Dodatkowe założenia w tym przykładzie:
- Nazwy hostów w Zabbix są zgodne z tymi skonfigurowanymi w systemie operacyjnym,
- Obydwa hosty należą do grupy “Linux servers”,
- Host “zabbix-7-0” jest dodatkowo w grupie “Zabbix servers”,
- Oba hosty korzystają z domyślnego szablonu “Linux by Zabbix agent” – przykłady będziemy opierać właśnie na tych danych.
- Serwer zabbix-7-0 posiada 2 CPU, natomiast serwer grafana-12-1 – 1 CPU.
- każdy serwer posiada pojedynczy interfejs sieciowy.
Dodanie pierwszego dashboardu
Na początek dodajemy nowy dashboard klikając w “+” – “New dashboard” na rozwijanym paneli u góry strony:
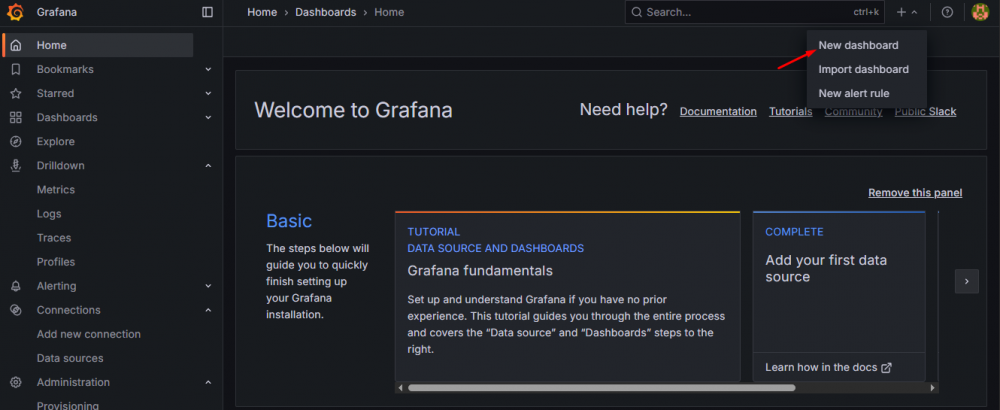
Po utworzeniu nowego dashboardu zobaczymy ekran podobny do tego:
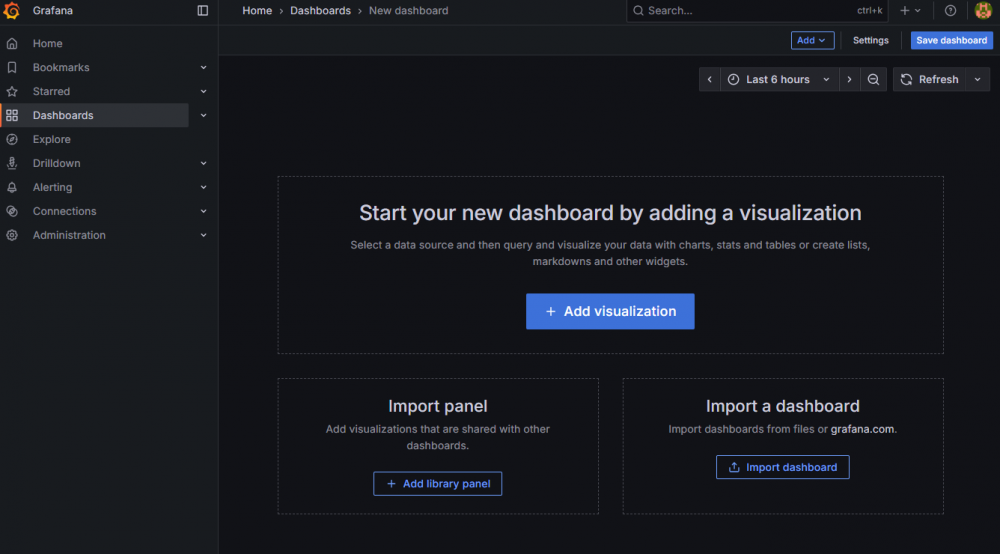
Wprawne oko zauważy też opcję importu gotowych dashboardów. Na >stronie community można znaleźć sporą listę — wystarczy pobrać plik JSON i wcisnąć „Import dashboard”, a następnie wskazać plik lub wkleić jego zawartość. Warto jednak znać podstawy konfiguracji dashboardów, bo takie gotowce często nie działają od razu i wymagają poprawek parametrów.
Na początek dobrze jest kliknąć „Settings” (prawy górny róg). W sekcji „General” możemy zmienić nazwę dashboardu, dodać opis i tagi (co później ułatwi wyszukiwanie na liście).
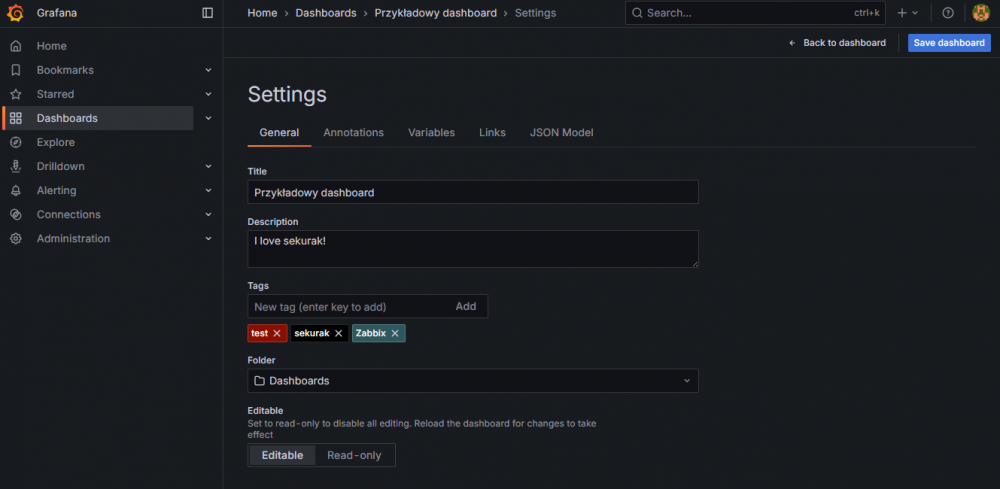
Uwaga! W prawym górnym rogu znajduje się przycisk „Save dashboard”, służący do zapisywania zmian. Warto wyrobić sobie nawyk częstego zapisywania, ponieważ domyślnie nic nie jest zapamiętywane i po odświeżeniu strony zmiany po prostu znikną.
Autor w tym miejscu chce zwrócić uwagę na jeszcze jedną rzecz – podczas odświeżania strony z dashboardem możesz nie widzieć opcji edytowania dashboardów lub zapisu. To efekt nowego podejścia Grafany do tworzenia dashboardów — domyślnie otwierają się one w trybie „zablokowanej edycji”. Wystarczy kliknąć „Edit” w prawym górnym rogu, aby odblokować możliwość modyfikacji:
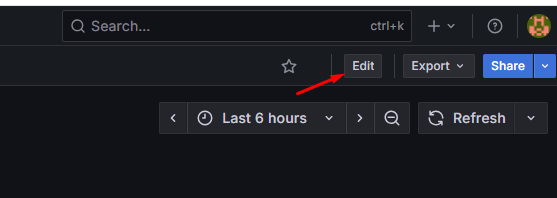
Od tego momentu możemy już swobodnie dodawać i edytować panele, a także zapisywać cały dashboard. Do tego dochodzi jeszcze możliwość zmiany wielkości i rozmieszczenia paneli, więc układ możemy dostosować dokładnie pod siebie.
Histogram
Czas ustawić pierwszy panel. Będzie on pokazywał rozkład średnich czasów obsługi żądań zapisu do dysku „sda” z serwera Grafany (w milisekundach). Mówiąc inaczej — chodzi o parametr „w_await” z polecenia iostat. To jedna z wielu metryk monitoringu dysków dostępnych w oficjalnym szablonie „Linux by Zabbix agent”:

Wracając do Grafany – dodajemy nowy panel klikając “Add” – “Visualization” w prawym górnym rogu:
Po tej operacji zobaczymy ekran edycji:
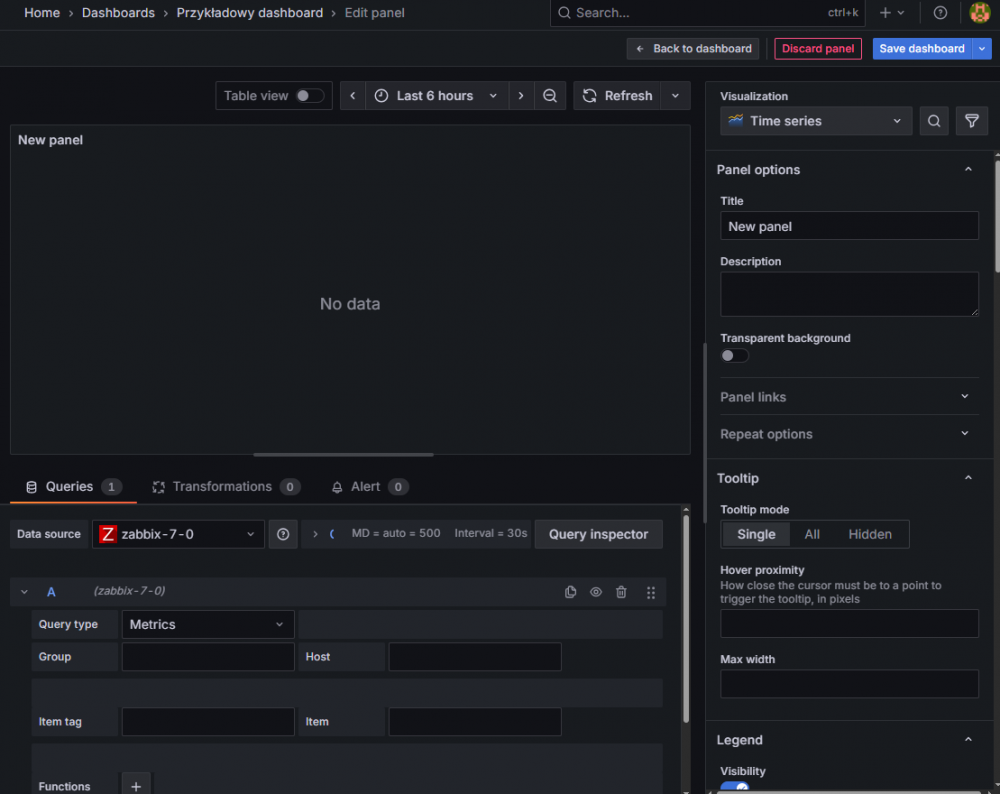
Na razie skupiamy się na lewej dolnej części ekranu, gdzie konfigurujemy zapytanie o dane. Najpierw upewnij się, że ustawione źródło danych “Data source” wskazuje na wcześniej skonfigurowane połączenie do środowiska Zabbix (dla przypomnienia – nazwa “zabbix-7-0”). Pod spodem znajduje się konfiguracja zapytania. Najważniejsze jest ustawienie odpowiedniego typu (“Query type”):
- Metrics – przeszukiwanie danych po grupie hostów, hoście, pozycji i jej znacznikach; działa tylko dla wartości liczbowych,
- Text – analogicznie jak „Metrics”, ale dla ciągów znaków (typ „character” lub „text” w Zabbix),
- Services – pobranie informacji o SLA skonfigurowanym w Zabbix (zakładka „Services”),
- itemID – zamiast szukać informacji po grupach i hostach, można podać listę konkretnych itemID rozdzielonych przecinkami (na razie działa tylko dla wartości liczbowych),
- Triggers – liczba aktywnych problemów dla wskazanych grup hostów i hostów,
- Problems – również można pobrać listę aktywnych problemów z środowiska zabbix, ale również dane historyczne (analogicznie do zakładki „Monitoring” – „Problems” z interfejsu Zabbix),
- User macros – pobiera wszystkie makra przypisane do hosta dla wskazanej grupy hostów i samych hostów (tylko makra przypisane bezpośrednio do hosta, nie pobiera makr dziedziczonych np. z szablonów).
Ponieważ interesują nas dane liczbowe, wybieramy „Metrics”. By pobrać dane o dysku sda na serwerze grafana-12-1, wpisujemy następujące dane:
- Group – grupa hostów, do której należy serwer grafana-12-1, w naszym przykładzie “Linux servers”,
- Host – nazwa hosta – “grafana-12-1”,
- Item tag – znacznik pozycji, która nas interesuje – “component: storage” (uwaga – nie jest to wymagane, ale dla czytelności warto go podać, bo dzięki temu szybciej znajdziemy konkretną pozycję z następnej listy),
- Item – wpisujemy nazwę naszej pozycji (lub wybieramy z listy) – “sda: Disk write request avg waiting time (w_await)”
Jeśli wszystko ustawiliśmy poprawnie, zobaczymy wykres z danymi:
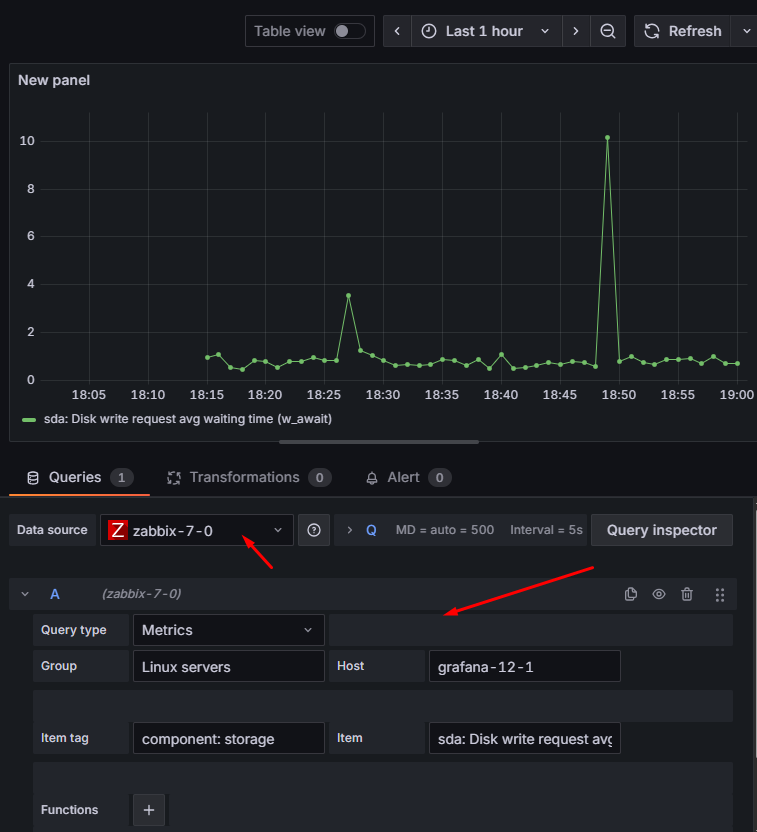
Przydatna wskazówka: jeśli chcesz podejrzeć, jakie dokładnie dane stoją za wykresem, użyj opcji „Table view” (tuż nad konfigurowanym panelem). Wyświetla ona tabelę z aktualnymi wartościami. Będziemy korzystać z tego widoku w kolejnych przykładach, ale to też świetny sposób, żeby szybko sprawdzić, „co siedzi pod spodem”:
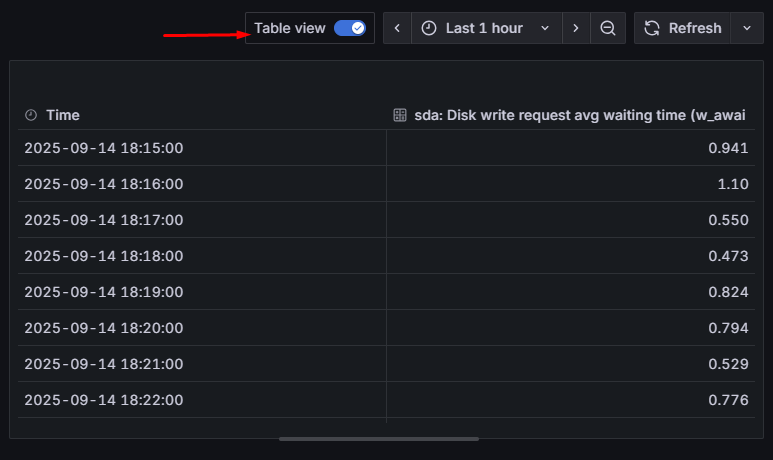
Udało nam się wyświetlić pierwszy wykres w grafanie. No właśnie… a mieliśmy unikać prostych przykładów i pokazać coś ciekawszego! Skupmy się więc teraz na prawej części ekranu, gdzie znajduje się okienko „Visualization”. Domyślnie wybrane jest „Time series” (czyli zwykły wykres liniowy). Zmieńmy to na „Histogram”:
I gotowe! Naszym oczom powinien ukazać się histogram, który automatycznie powinien dostosować się do danych wejściowych – w naszym przykładzie większość wartości parametru w_await mieści się poniżej 2 ms, z drobnymi odstępstwami:
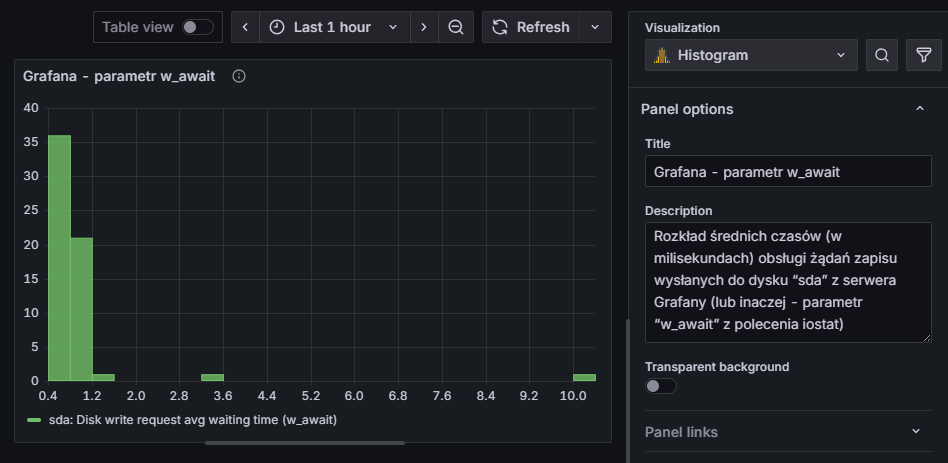
Autor w tym miejscu zachęca do sprawdzenia wszystkich opcji z okienka “Visualization” na swoją rękę – można dostosować wygląd histogramu do własnych potrzeb. Jedyne o czym nie warto zapominać to tytuł oraz krótki opis (w sekcji “Panel options”), co dany panel przedstawia.
Jeśli efekt Ci odpowiada, możesz wyjść z edycji („Back to dashboard”) i nie zapomnij o zapisie („Save dashboard”)!
Wykres punktowy (XY)
Czas na kolejny przykład — wykres punktowy (ang. „XY chart”). To typ wizualizacji, w której wartości są przypisane zarówno do osi X, jak i Y (czyli nie bazują na czasie). Taki wykres pomaga sprawdzić, czy dwie metryki mają ze sobą jakiś związek (np. Możemy sprawdzić, jak wygląda zużycie CPU w zależności od liczby użytkowników w aplikacji).
W naszym przypadku przyjrzymy się serwerowi zabbix-7-0 i odpowiemy na pytanie:
„Czy na serwerze Zabbix większe zużycie CPU przekłada się na większe zużycie pamięci?”
(Pamiętaj — to tylko przykład. Wynik nie oznacza, że zawsze tak będzie na każdym serwerze Zabbix).
Dla zobrazowania, poniżej pokazano listę pozycji CPU utilization i Memory utilization w Zabbix, które będziemy wykorzystywać:

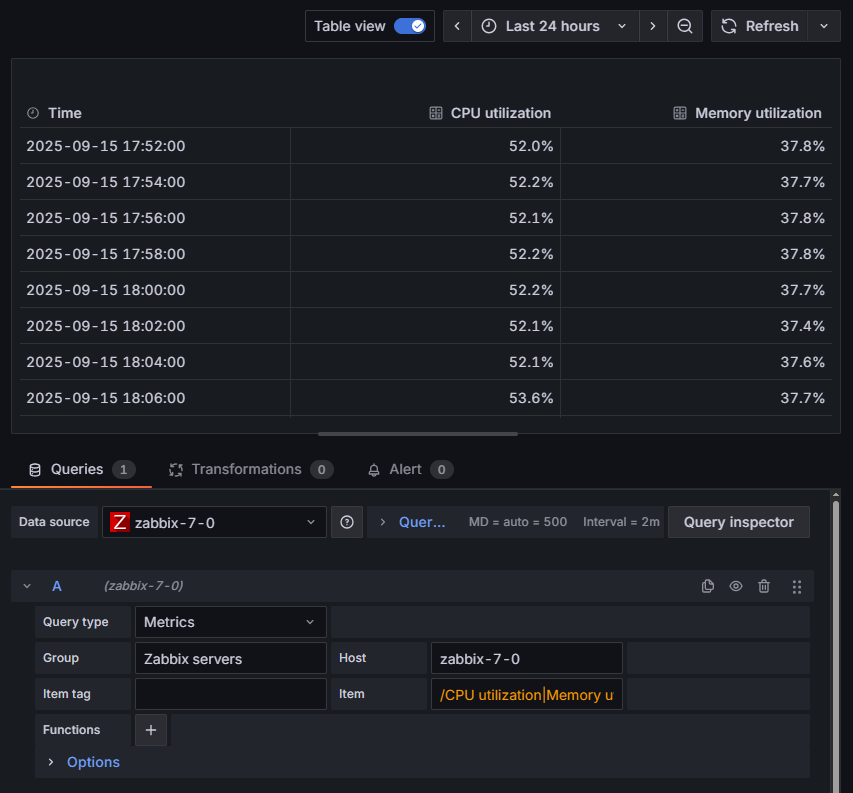
Tworzymy nowy panel na naszym dashboardzie, upewniamy się że nasze źródło danych to skonfigurowany przez nas Zabbix i uzupełniamy następujące pola w zapytaniu:
- Query type – wybieramy “metrics” (bo znowu interesują nas dane liczbowe),
- Group – grupa hostów, do której należy serwer zabbix-7-0, w naszym przykładzie – “Zabbix servers”,
- Host – nazwa hosta – “zabbix-7-0”,
- Item tag – nie jest wymagany, więc tym razem zostawiamy puste,
- Item – tym razem chcemy pobrać dwie metryki na raz, więc wykorzystamy fakt, że zamiast jawnie wskazywać metrykę, możemy użyć wyrażenia regularnego. egex zapisujemy między ukośnikami, a w przeglądarce podświetli się on na pomarańczowo. Wykorzystamy następujące wyrażenie regularne:
/CPU utilization|Memory utilization/
Które oznacza nazwę pozycji “CPU utilization” lub “Memory utilization”. Składnia regex jest tutaj specjalnie uproszczona, żeby była łatwa do zrozumienia, ale nic nie stoi na przeszkodzie, by zastosować bardziej restrykcyjne wyrażenie, na przykład:
/^(CPU|Memory) utilization$/
Całą konfigurację wraz z przykładowymi danymi w widoku „Table view” pokazuje poniższy przykład:
Aby zamienić panel na wykres punktowy, przechodzimy do prawego okienka „Visualization” i wybieramy „XY Chart” (najłatwiej wyszukać przez wyszukiwarkę):
Naszym oczom najprawdopodobniej ukaże się wykres wartości w zależności od czasu. Musimy więc jeszcze dostosować panel do naszych potrzeb:
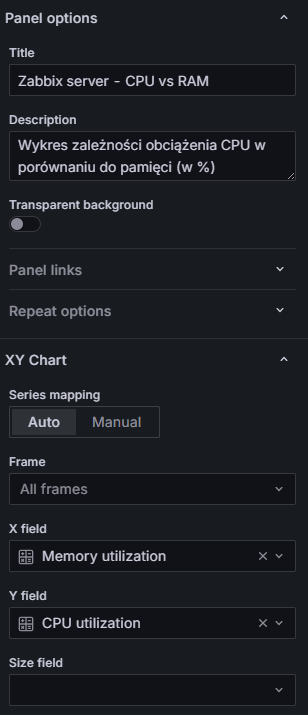
- Panel options → Title – tytuł np. „Zabbix server – CPU vs RAM”,
- Panel options → Description – krótki opis np. „Wykres zależności obciążenia CPU w porównaniu do pamięci (w %)”,
- XY Chart → X field – co ma się pojawić na osi X – wybieramy z listy „Memory utilization”,
- XY Chart → Y field – co ma się pojawić na osi Y – wybieramy „CPU utilization”.
Na razie nie zmieniamy nic więcej, ale — jak zwykle — autor znowu zachęca do sprawdzenia wszystkich opcji we własnym zakresie. Efekt końcowy w naszym przypadku wygląda tak (najlepiej ustawić dłuższy przedział czasu, np. 1–2 dni):
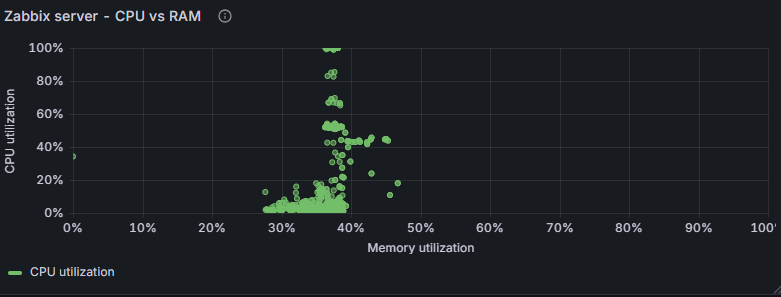
Teraz czas odpowiedzieć na ważne pytanie: Jak czytać wykres XY?
Na wykresie XY każda kropka odpowiada jednej obserwacji: współrzędna X to wartość jednej metryki (u nas „Memory utilization”), a współrzędna Y — drugiej („CPU utilization”).
Kilka wskazówek:
- Jeśli kropki układają się w trend w górę (przekątna od lewej do prawej), oznacza to, że wyższe wartości jednej metryki idą w parze z wyższymi wartościami drugiej.
- Jeżeli punkty są rozrzucone bez wyraźnego wzorca, oznacza to brak zależności między metrykami.
- Można też obserwować koncentrację punktów: gęstość wskazuje, w jakim zakresie najczęściej znajdują się wartości.
- Skrajne punkty (outliery) warto sprawdzić oddzielnie — mogą oznaczać chwilowe obciążenia lub nietypowe zdarzenia.
W naszym przykładzie widać, że nawet przy maksymalnym obciążeniu CPU wartości pamięci pozostają stosunkowo niskie, co pokazuje brak silnej zależności między tymi dwoma metrykami.
Możemy wyjść z trybu edycji panelu. Po ewentualnym przestawieniu nowo utworzonych paneli dashboard powinien wyglądać mniej więcej tak, jak na poniższym przykładzie. Pamiętaj, aby zapisać zmiany przyciskiem „Save dashboard”!
Podsumowanie
Niniejszy artykuł miał pokazać, że tworzenie wykresów na Grafanie nie jest trudna, a sama Grafana jest bardzo elastyczna w konfiguracji. Autor gorąco zachęca do dalszych eksperymentów, a w szczególności do tworzenia własnych dashboardów.
Jednocześnie zapraszamy na nasze nowe duże szkolenie Zabbix Expert z ponad 50% rabatem! Zapisy tutaj: https://zabbix.sekurak.pl
A może powyższe przykłady nie zrobiły na Tobie większego wrażenia i nie wywołały efektu „wow”? W takim razie zapraszam do kolejnego artykułu, w którym zmierzymy się z transformacjami i innymi opcjami zapytań. Jeżeli jednak artykuł pomógł Ci w wyświetleniu interesujących Cię danych to pomyśl o wsparciu autora >dobrą kawką!
~ Albert Przybylski, zawodowo: Architekt ds. Monitoringu w firmie Aplitt, prywatnie: pełnoprawny fanatyk Zabbixa zasilany kawą

Mam takie pytanie — w pierwszej części jest opis instalacji Grafany i naszła mnie taka luźna myśl: czy nie chcielibyście może wrzucić w trzecim artykule (lub jako edycję w pierwszej części) gotowego pliku docker-compose.yml, który umożliwiłby uruchomienie całego stacku Zabbix + Grafana?
Taki plik mógłby również odtwarzać sieć i powiązania kontenerów dokładnie w takiej formie, w jakiej zostały zaprezentowane w artykule. Dla laików to byłoby fajne ułatwienie w temacie instalacji, a co za tym idzie byłoby większe zainteresowanie w temacie Zabbix + Grafana :)
Tak ogółem to świetny cykl artykułów! :)