Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

XSS w Google Colaboratory + obejście Content-Security-Policy
W poniższym tekście, pokazuję ciekawego XSS-a, którego znalazłem w lutym 2018 w jednej z aplikacji Google’a. Pokazuję nie tylko bezpośrednio, gdzie był ten XSS, ale również jakie czyniłem próby, by tego XSS-a znaleźć i w jakie ślepe zaułki wszedłem. Ponadto, pokazany jest przykład obejścia Content-Security-Policy z użyciem tzw. script gadgets.
Czym jest Google Colaboratory
Celem, który wybrałem do testów, była webaplikacja Google Colaboratory. Oparta jest ona o inną znaną aplikację, zwaną Jupyter Notebook. Colaboratory umożliwia tworzenie dokumentów, zawierających zarówno tekst (formatowany w języku markdown), jak i kod (Python 2 lub 3). Kod wykonywany jest w chmurze Google’a, a jego wynik umieszczany jest bezpośrednio w dokumencie. Może to być przydatne w pracach naukowych, gdzie można przygotować sobie zestaw danych oraz kod, który w jakiś sposób te dane przetwarza, np. wykonuje na nich obliczenia lub rysuje wykresy czy diagramy Venna. Takie przykłady są zresztą pokazane na stronie wejściowej Colaboratory.
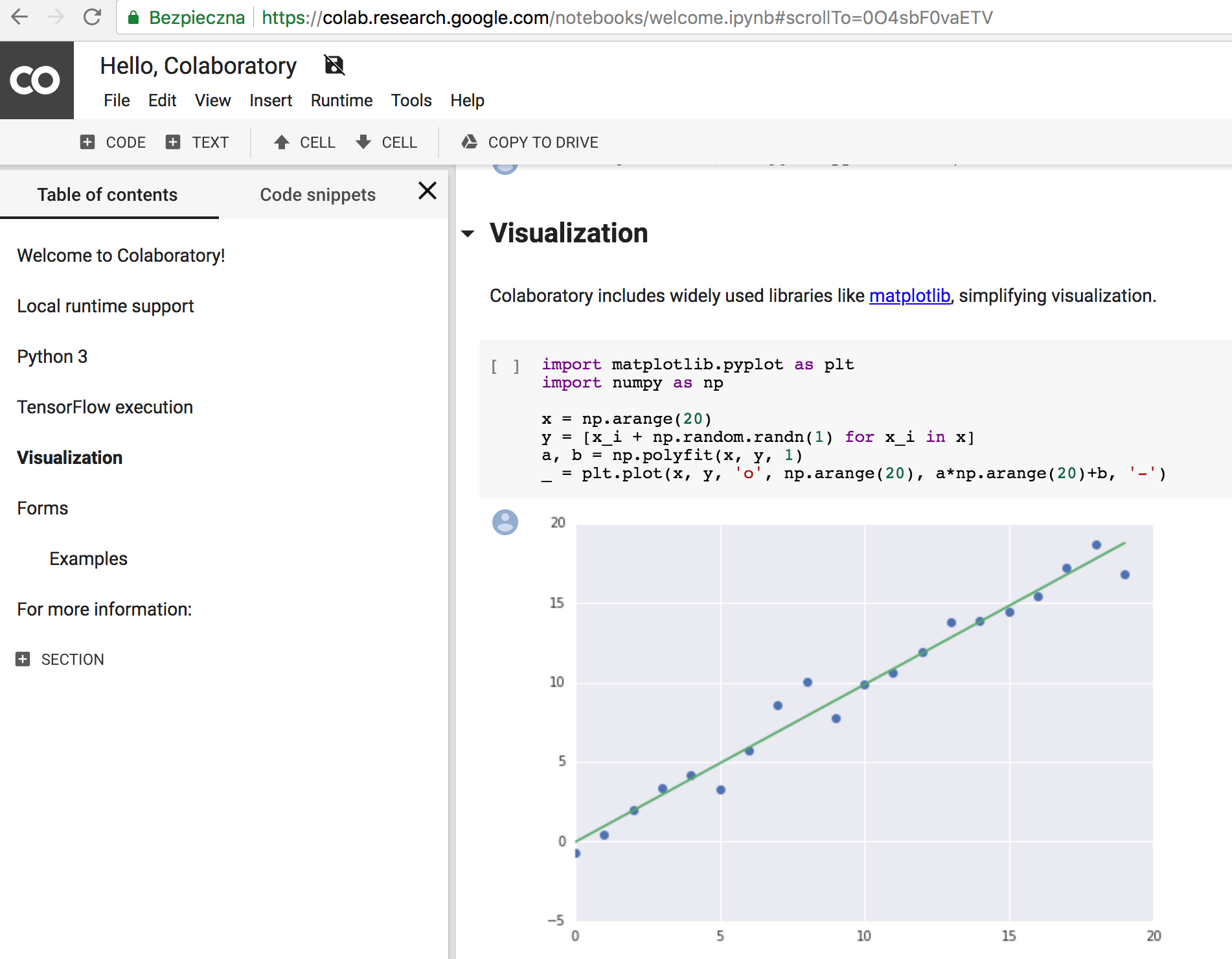
Rys 1. Główny widok Colaboratory
Zazwyczaj szukając błędów w ramach programu bug bounty firmy Google skupiam się na błędach frontendu (głównie XSS-ach) i nie inaczej było tym razem. Jak wspomniałem wcześniej, Colaboratory używało składni Markdown. Markdown jest dzisiaj bardzo powszechnie używany, używa się np. **dwóch gwiazdek** w celu napisania pogrubionego tekstu czy *jednej gwiazdki* dla kursywy (Rys 2.).
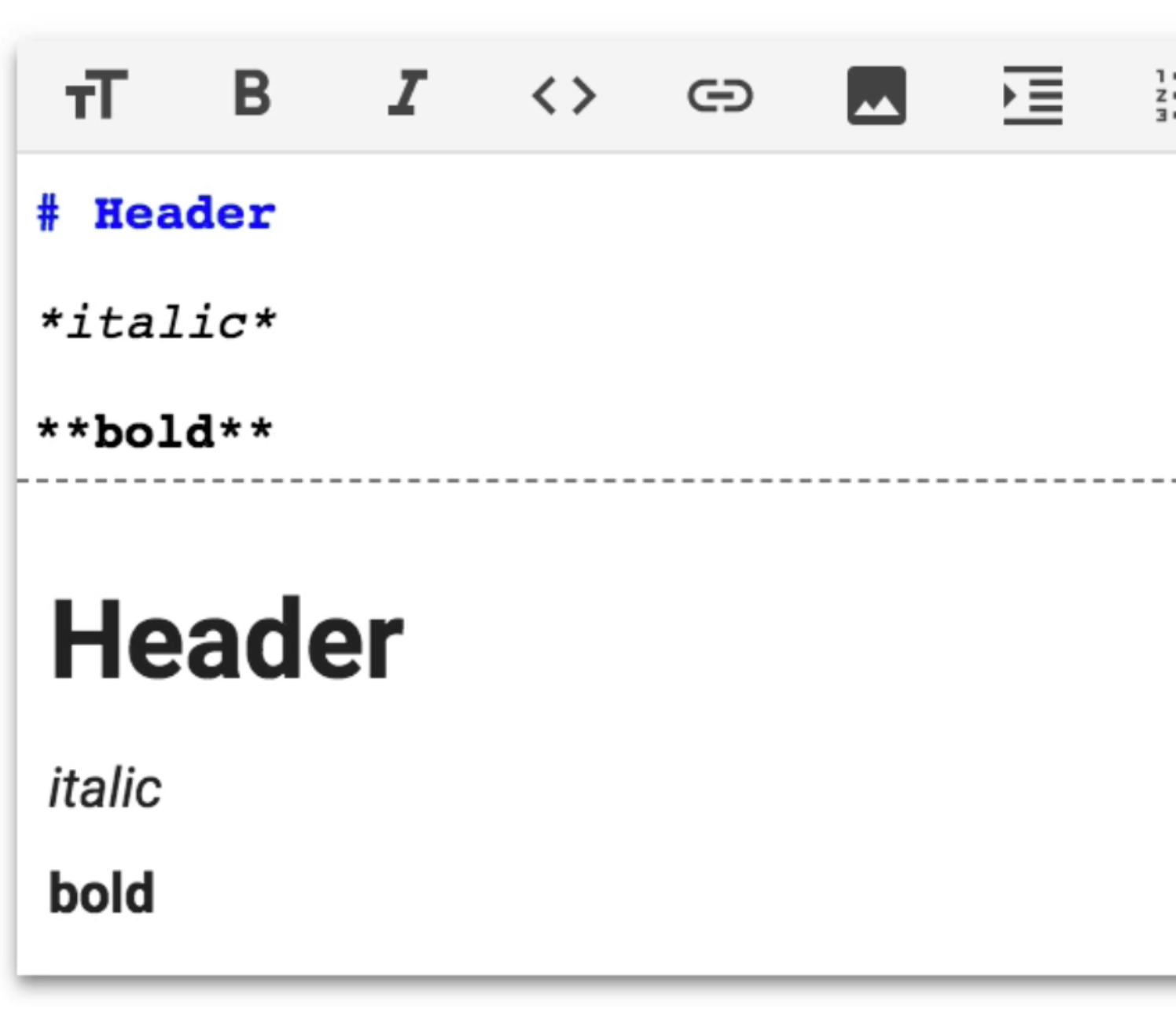
Rys 2. Podstawy składni Markdown
Co ciekawe, większość parserów Markdown pozwala na używanie w środku składni HTML-a. W Colaboratory było podobnie; przykładowo, gdy napisałem poniższy kod:
To jest <strong>pogrubiony tekst</strong>
W drzewie DOM strony faktycznie pojawiało się:
To jest <strong>pogrubiony tekst</strong>
Zacząłem więc po linii najmniejszego oporu i spróbowałem klasycznego wstrzyknięcia XSS-owego:
Test<img src=1 onerror=alert(1)>
Jednak wówczas w drzewie DOM pojawił się tylko kod:
Test<img src="1">
Oznaczało to, że Colaboratory było sprzężone z jakąś biblioteką, która “czyści” kod HTML z niebezpiecznych elementów (czyli np. ze zdarzenia onerror). Jaka to biblioteka – udało mi się ustalić dopiero nieco później.
Próbowałem w tym momencie uderzyć z innej strony; bardzo częstym sposobem na wykonanie XSS-a przez parsery Markdowna jest użycie linków do protokołu javascript:. Przykładowo, kod:
[CLICK](javascript:alert(1))
Zostałby zamieniony na:
<a href="javascript:alert(1)">CLICK</a>
Colaboratory był jednak przed tym atakiem zabezpieczony. Gdy użyłem innego protokołu niż http lub https, w HTML-u nie został wygenerowany link. Zauważyłem jednak, że linki były tworzone, nawet jeśli adres URL nie zawierał poprawnej domeny, np.:
[CLICK](https://aaa$$$**bbbb)
Powyższy kod został zamieniony na:
<a href="https://aaa$$$**bbbb">CLICK</a>
Pozwoliło mi to wysnuć przypuszczenie, że sprawdzenie poprawności URL-a odbywa się jakimś prostym wyrażeniem regularnym. Ponieważ przetwarzanie Markdowna odbywało się w Colaboratory po stronie JavaScriptu, zacząłem przeglądać pliki .js aplikacji w poszukiwaniu owego regeksa. Dość szybko udało się znaleźć poniższy kod:
[...]
return qd(b ? a : "about:invalid#zClosurez")
}
, sd = /^(?:(?:https?|mailto|ftp):|[^:/?#]*(?:[/?#]|$))/i
, td = function(a) {
[...]
Zaznaczona linia jest właśnie wyrażeniem regularnym sprawdzającym poprawność adresów URL w linkach. Przyjrzałem się temu wyrażeniu dokładniej i niestety nie udało mi się znaleźć na nie żadnego obejścia. Mimo wszystko czas spędzony na jego szukaniu nie poszedł na marne. Pomyślałem, że skoro znalazłem miejsce, które weryfikuje poprawność linków, to może gdzieś w okolicy znajdę kod, który czyści HTML, to znaczy znajdę odpowiedzialnego za wcześniejsze usunięcie zdarzenia onerror? Okazało się to słusznym tropem i niewiele linii dalej znalazłem poniższy string:
var Fm = xk("goog.html.sanitizer.SafeDomTreeProcessor")
Szybkie wyszukanie czym jest goog.html.sanitizer.SafeDomTreeProcessor pozwoliło ustalić, że jest to część sanitizera (czyli narzędzia do czyszczenia kodu HTML z niebezpiecznych elementów) z biblioteki Closure. Znajdziemy w nim zarówno blacklistę, jak i whitelistę tagów. Innymi słowy: mamy zdefiniowaną listę tagów, które absolutnie nie mogą się znaleźć w wynikowym HTML-u, a dodatkowo mamy jeszcze listę tagów, które mogą zostać dopuszczone. Po raz kolejny: spędziłem nieco czasu na próbach obejścia sanitizera z Closure, ale spaliły one na panewce. Closure jest wszakże bardzo popularną biblioteką do czyszczenia HTML-a, stąd było małe prawdopodobne, że w krótkim czasie znajdę w niej jakieś błędy bezpieczeństwa.
W tym momencie musiałem więc pomyśleć o uderzeniu Colaboratory z innej strony. Wróciłem do dokumentacji i zauważyłem jedną rzecz, która wcześniej mi umykała: Colaboratory wspiera jeszcze składnię LaTeX. To może być klucz!
Wróciłem zatem do edytora Markdown i wpisałem proste wyrażenie LaTeXowe:
\frac 1 2
Następnie, przyjrzałem się drzewu DOM wyrenderowanego elementu:
<span class="MathJax" id="MathJax-Element-5-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mfrac><mn>1</mn><mn>2</mn></mfrac></math>" role="presentation" style="position: relative;"> <nobr aria-hidden="true"> [...] </nobr> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mfrac> <mn>1</mn> <mn>2</mn> </mfrac> </math> </span> </span>
W drzewie DOM był jeszcze dość duży fragment kodu wewnątrz tagu <nobr>, ale nie jest on istotny, więc go wyciąłem. Ten fragment kodu, który został wygląda jednak bardzo ciekawie. Wspomniałem wcześniej, że Colaboratory korzystało z biblioteki Closure do czyszczenia HTML-a z niebezpiecznych elementów. Miało też zdefiniowaną whitelistę tagów. I na tej whiteliście nie było tagów takich jak <math>, <mfrac> czy <mn>. Jednak w wyniku wyrenderowania LaTeXa te tagi pojawiły się w HTML-u. Ponadto w pierwszej linii, w atrybucie data-mathml widać dokładnie ten sam HTML, który w dalszej części zostaje wyrenderowany. To był ten moment badania tej aplikacji, gdy poczułem, że jestem na dobrym tropie. Dlaczego? Ponieważ, jak wynika z powyższego zachowania aplikacji, biblioteka Closure nie jest używana do czyszczenia HTML-a wygenerowanego przez MathJax (bibliotekę do obsługi LaTeXa). W tym momencie problem znalezienia XSS-a w Colaboratory – sprowadził się do znalezienia XSS-a w bibliotece MathJax. Wydawało mi się dość mocno prawdopodobne, że MathJax nie był przez nikogo dobrze przebadany pod względem bezpieczeństwa.
Spojrzałem więc do dokumentacji MathJaxa, by dowiedzieć się, jakie makra LaTeXa są przez niego wspierane. W pierwszej kolejności zwróciłem uwagę na następujące makro: \href{url}{math}. Według dokumentacji umożliwia ono tworzenie linków wewnątrz LaTeXa. Czyżby tym razem sztuczka typu: \href{javascript:alert(1)}{1} miała zadziałać? ;) Niestety, okazało się, że w MathJaxie można włączyć tzw. safe-mode, który zabezpiecza właśnie przed tym atakiem. Szkoda!
Idąc dalej, w dokumentacji znajduje się wzmianka o makrze \unicode, które umożliwia umieszczenie w kodzie LaTeX dowolnych znaków unicode’u po ich punkcie kodowym. Można używać zarówno numerów w postaci dziesiętnej, jak i szesnastkowej. Spróbowałem więc go użyć w Colaboratory, wpisując kod dużej litery “A” na dwa sposoby:
\unicode{x41}\unicode{65}
W drzewie DOM pojawiło się:
<span class="MathJax" id="MathJax-Element-6-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mtext>A</mtext><mtext>A</mtext></math>" role="presentation" style="position: relative;"> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mtext>A</mtext> <mtext>A</mtext> </math> </span> </span>
Zgodnie z oczekiwaniami, mamy dwie litery “A”, jednak przyjrzyjmy się pierwszej linii. W atrybucie data-mathml widzimy, że wewnątrz tagów <mtext> znajdują się encje liczbowe HTML-a w dokładnie takiej postaci jak je wpisałem, tj. A i A. Może więc MathJax w żaden sposób nie przetwarza wnętrza makra \unicode i po prostu wrzuca w HTML-a wszystko to, co jest w środku? Spróbowałem więc poniższego kodu:
\unicode{<img src=1 onerror=alert(1)>}
I w drzewie DOM…
<span class="MathJax" id="MathJax-Element-7-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mtext>&#<img src=1 onerror=alert(1)>;</mtext></math>" role="presentation" style="position: relative;"> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mtext>&# <img src="1" onerror="alert(1)"> ;</mtext> </math> </span> </span>
Jest sukces! Tag <img> pojawił się w drzewie DOM strony, więc mamy XSS-a! No prawie… ponieważ tak naprawdę w tym momencie nie wyświetlił się żaden alert.
Przez pewien czas miałem poważną zagwozdkę, dlaczego tak się dzieje, jednak sprawa wyjaśniła się po zajrzeniu w konsolę przeglądarki, gdzie pojawił się błąd z Rys. 3.

Rys 3. Błąd Content-Security-Policy
W Colaboratory był włączony mechanizm Content-Security-Policy (CSP), którego głównym celem jest właśnie ochrona przed atakami XSS. Jak widać – w tym przypadku zadziałał. Postanowiłem jednak błąd mimo wszystko do Google’a w tym momencie zgłosić. Fakt, że CSP blokuje możliwość wykorzystania XSS-a nie zmienia jednak faktu, że główna przyczyna XSS-a (czyli w tym przypadku de facto błąd w bibliotece MathJax) nadal w aplikacji jest.
Zatem wysłałem zgłoszenie z Rys 4. (które, jak widać na zrzucie ekranu, zostało wysłane chwilę po północy) i pomyślałem, że pójdę spać, a rano zastanowię się jeszcze nad obejściem CSP.
Rys 4. Zgłoszenie błędu do Google’a
Obejście Content-Security-Policy
W rzeczywistości jednak nie dawało mi to spokoju, że zgłosiłem XSS-a do Google’a, który tak naprawdę się nie wykonuje. Nad którym widnieje gwiazdka, że potrzebne jest obejście CSP, by móc go realnie wykorzystać. Dlatego musiałem się zebrać i spróbować jednak z nim nieco powalczyć :)
Nagłówek Content-Security-Policy, o którym na Sekuraku pisaliśmy już dwukrotnie (część 1, część 2), w przypadku Colaboratory zawierał dwie istotne dyrektywy: ‘nonce-losowa-wartosc’ oraz ‘strict-dynamic’ .
Załóżmy więc, że mamy CSP o następującej wartości:
Content-Security-Policy: script-src 'nonce-losowa-wartosc' 'strict-dynamic'
A poniżej HTML-a:
<script nonce="losowa-wartosc">
var sc = document.createElement('script');
sc.src = 'https://inna-domena.sekurak/abc.js';
document.body.appendChild(sc);
</script>
To założenia działania CSP w tym przypadku można streścić do dwóch punktów:
- Pierwsza dyrektywa, ‘nonce-losowa-wartosc’, powinna mieć inną losową wartość za każdym odświeżeniem strony. Kod wewnątrz tagu <script> a wykona się tylko wtedy, jeżeli ma przypisany atrybut o nazwie nonce i wartości takiej samej, jaka znajdowała się w nagłówku CSP. Założenie jest tutaj takie, że jeśli napastnik chce wykonać wstrzyknięcie tagu <script> , to nie będzie w stanie tego zrobić, bo nie będzie potrafił odgadnąć poprawnej wartości nonce. W takim przypadku blokowane są również wszystkie skrypty zdefiniowane bezpośrednio w HTML-u w zdarzeniach. Dlatego nie zadziałało <img src=1 onerror=alert(1)>, bo zostało zablokowane przez CSP.
- Druga dyrektywa, ‘strict-dynamic’, została wprowadzona m.in. po to, by rozwiązać problem, który często pojawia się w skryptach trackingowych, mianowicie dołączanie dodatkowych skryptów z zewnętrznych domen w sposób dynamiczny. Dyrektywa ta wprowadza tutaj przechodniość zaufania. Oznacza to, że jeżeli na stronie jest skrypt, któremu ufamy (np. dlatego, że ma ustawioną poprawną wartość nonce) i ten skrypt dodaje kolejny skrypt do drzewa DOM, to wówczas – na zasadzie przechodniości zaufania – ufamy też temu świeżo dodanemu skryptowi.
Na kilku konferencjach o bezpieczeństwie w zeszłym roku, w tym na BlackHacie, pojawiła się fantastyczna prezentacja o nazwie Breaking XSS mitigations via Script Gadgets autorstwa Sebastiana Lekiesa, Eduardo Vela Navy i Krzysztofa Kotowicza. Przedstawiono w niej, w jaki sposób można wykorzystać kod w popularnych frameworkach JS do tego, by obchodzić różnego rodzaju zabezpieczenia przed XSS-ami – w tym: CSP. Aplikacja Colaboratory jest napisana z użyciem frameworka Polymer, a jak możemy się dowiedzieć z jednego ze slajdów ww. prezentacji, Polymer może posłużyć do obejścia wszystkich typów CSP (Rys 5.).
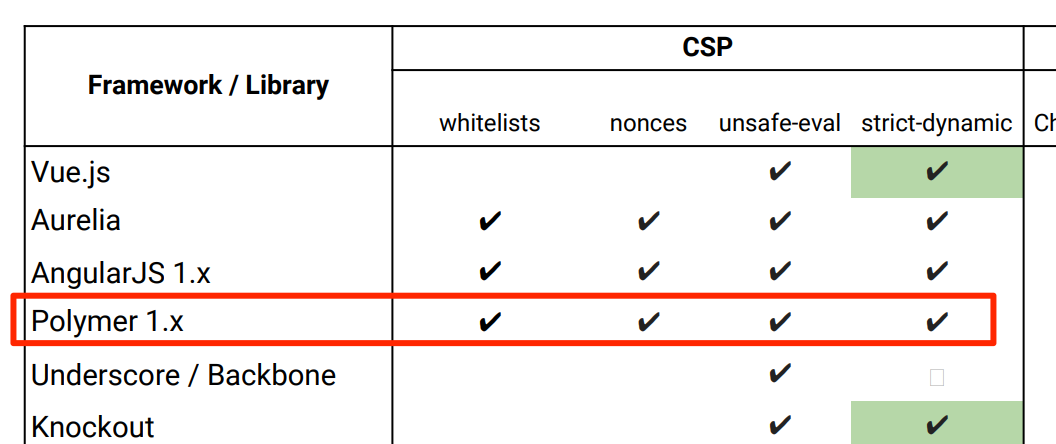
Rys 5. Polymer pozwala obejść wszystkie typy CSP
Czym jest zatem Polymer? To biblioteka, z użyciem której można pisać tzw. Web Componenty. W największym skrócie chodzi o możliwość definiowania swoich własnych elementów HTML, a później używać ich bezpośrednio w kodzie. Czyli przykładowo, w Polymerze można zdefiniować element <logo-sekuraka> i wówczas, po użyciu gdzieś w kodzie HTML: <logo-sekuraka /> – w tym miejscu pojawi się właśnie logo Sekuraka ;)
Moja myśl była taka, by w Colaboratory podmienić szablon jednego z domyślnie wbudowanych elementów. W prawym górnym rogu okna Colaboratory znajdował się przycisk “SHARE”, po kliknięciu którego, w drzewie DOM tworzony był element <colab-dialog-impl>. W swoim XSS-ie napisałem więc następujący kod:
$ \unicode{</math><dom-module id=colab-dialog-impl>
<template>
SOME RANDOM TEXT
</template>
</dom-module>} $
W pierwszej próbie wpisałem w środku szablonu zwykły tekst, by upewnić się, że rzeczywiście jestem w stanie go podmienić dla domyślnych elementów. Efekt był taki, jak na poniższym filmie.
Brawa dla uważnych czytelników, którzy zauważyli, że na filmie jest literówka… Niewiele ona jednak zmienia ;)
Efekt jest zgodny z oczekiwaniami – jestem w stanie zmienić działanie domyślnych elementów. Pozostaje więc tylko zmodyfikować XSS-a do poniższej postaci:
$ \unicode{</math><dom-module id=colab-dialog-impl>
<template>
<script>alert(1)</script>
</template>
</dom-module>
<colab-dialog-impl>} $
W stosunku do poprzedniej wersji, wprowadzone zostały dwie zmiany:
- Kod został podmieniony na typowego XSS-a (trzecia linia). Na pierwszy rzut oka może się wydawać, że tag <script> powinien zostać zablokowany. Zauważmy jednak, że zostanie on dodany do drzewa DOM przez Polymer, który jest zaufanym skryptem. Zatem dzięki dyrektywie ‘strict-dynamic’, skrypt dodany przez zaufany skrypt jest również zaufany na mocy przechodniości zaufania.
- Na końcu zostało dodane odwołanie do elementu <colab-dialog-impl>. Dzięki temu, nie będzie już potrzeby klikania na przycisk “SHARE”, by XSS się wykonał, tylko wykona się automatycznie.
Efekt poniżej:
Po bardzo długiej walce, mamy wreszcie upragnionego XSS-a!
Zgłosiłem zatem to obejście do Google’a (Rys 6.). Wymyślenie tego obejścia zajęło mi około trzech godzin (jak widać na obrazku). Summa summarum, Google wypłaciło bounty w wysokości 3133,7$.
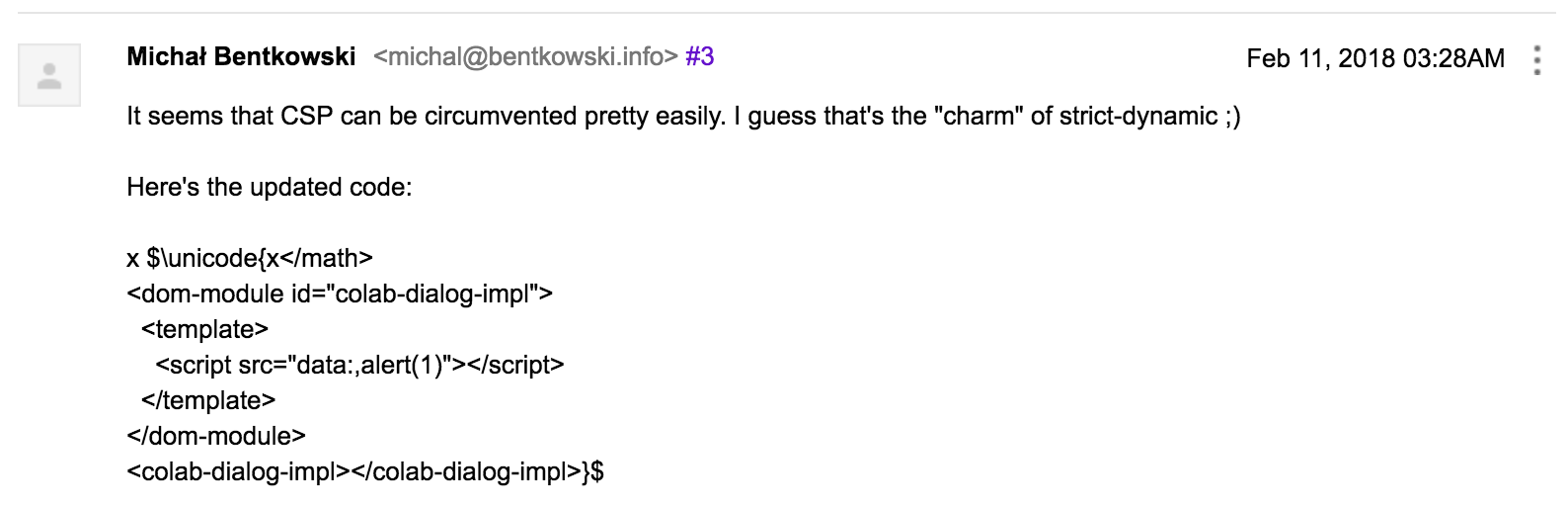
Rys 6. Ostateczne zgłoszenie błędu do Google
Kod jest odrobinę inny niż pokazywałem wyżej, trochę bardziej skomplikowany. Myślę, że sensowne wytłumaczenie tego faktu może być takie, że już nie myślałem do końca trzeźwo ze względu na godzinę ;)
Podsumowanie
Pokazałem w tekście, w jaki sposób udało mi się zidentyfikować w aplikacji Colaboratory XSS-a. Było to możliwe dzięki znalezieniu błędu bezpieczeństwa w bibliotece MathJax, używanej w tej aplikacji. W kolejnym kroku, musiałem się posłużyć sztuczką znaną jako script gadgets, by obejść zabezpieczenie przed XSS-ami w postaci Content-Security-Policy.
Notabene, błąd został naprawiony przez twórców MathJaxa, choć odpowiedni commit nie zawiera żadnej wyraźnej informacji, że naprawiany jest błąd bezpieczeństwa.
— Michał Bentkowski, hackuje w Securitum

Dziękuję za opis dochodzenia do błędu.
Wow, gościu sprawiasz, że już nigdy nie tkne informatyki i programowania. Po co nawet się starać, skoro w tym gąszczu informacji zawsze znajdzie się ktoś sprytniejszy ?:<
Masz rację, zajmij się hodowlo jedwabników :)
Fajnie się czytało.
Tylko jest jeden błąd. ;)
Brak kosztów piwa. :D
Wow, artykuł wciąga od pierwszego zdania aż do ostatniej kropki! Cały proces opisałeś tak przejrzyście, że nawet laik taki jak ja może wiele wyciągnąć z tekstu :). Chapeau bas!
Więcej takich artykułów :D !