Wstęp
W naszej serii o różnych, popularnych rozwiązaniach wśród środowisk DevOps mamy już ElasticSearch oraz Mesos/Marathon. Natomiast jeśli skupimy się stricte na ilości ujawnianych danych okazuje się, że prawdziwie miażdżącą siłą w tej kategorii jest Hadoop/HDFS. Nawet taki gigant, jak MongoDB nie jest mu w stanie dotrzymać kroku. Pod koniec maja tego roku na około (i tylko) 4500 instancjach rozproszonego systemu plików HDFS udostępnionych zostało blisko 5 PB danych. Najwięcej z nich znajduje się na terenie USA oraz Chin, gdzie za ich hosting odpowiedzialne są takie firmy, jak Amazon oraz Alibaba.

źródło: shodan.io
Patrząc na trendy integracji różnych dostawców z tym rozwiązaniem i coraz większą prostotą wejścia w BigData – możliwe, że stajemy właśnie u progu wycieków z jezior danych. Czy ekstrakcja danych z takiego ekosystemu jest trudna? Nie, a nawet banalnie prosta. Wynika to z faktu, że tego typu otwarte systemy nie inwestują w wprowadzanie natywnych zabezpieczeń, a jeśli nawet je posiadają istnieje prosty trick na ich obejście w określonych warunkach. Dla osób związanych z data science najważniejszym aspektem są dane oraz wnioski płynące z ich obróbki. Wprowadzenie zabezpieczeń dla środowisk typu PoC konkretnych przepływów lub obliczeń tylko komplikuje ten proces i wydłuża czas pracy nad rozwiązywaniem zadań.
Eksploracja
Demonstrację możemy zacząć od wyszukania publicznych serwerów typu NameNode (serwery w tej roli odpowiedzialne są m.in. za centralne zarządzanie klastrem przechowując tylko metadane HDFS, śledzą też drzewo katalogów i plików), które dostępne są na porcie 50070:

Wyszukiwanie klastrów Hadoop.
Jeśli wybierzemy dowolny obiekt z listy zostaniemy przekierowani na stronę informacyjną klastra:
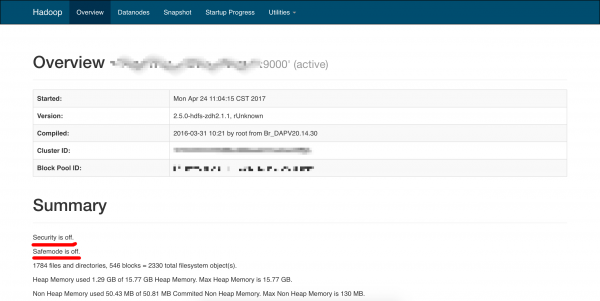
Podgląd klastra Hadoop.
Jak możemy się przekonać mechanizmy bezpieczeństwa są wyłączone (“Security is off”). Jest to standardowe ustawienie konfiguracyjne Hadoopa, które powinno być zmienione i zweryfikowane zaraz po jego instalacji. Dlatego jeśli porty dla nasłuchujących daemonów są otwarte, żadne hasło nie jest wymagane, aby móc dostać się do dużych lub dużej ilości składowanych i przeprocesowanych plików na klastrze. Jak dobrać się do danych? Przechowywane są one na dedykowanych serwerach o roli “Datanode”. Jeśli przejdziemy do zakładki Datanodes, powinniśmy otrzymać listę wszystkich aktywnych serwerów zarejestrowanych w klastrze:
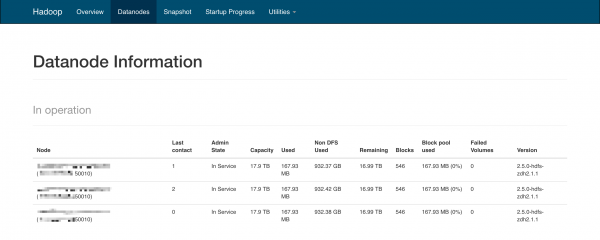
Rozkład danych.
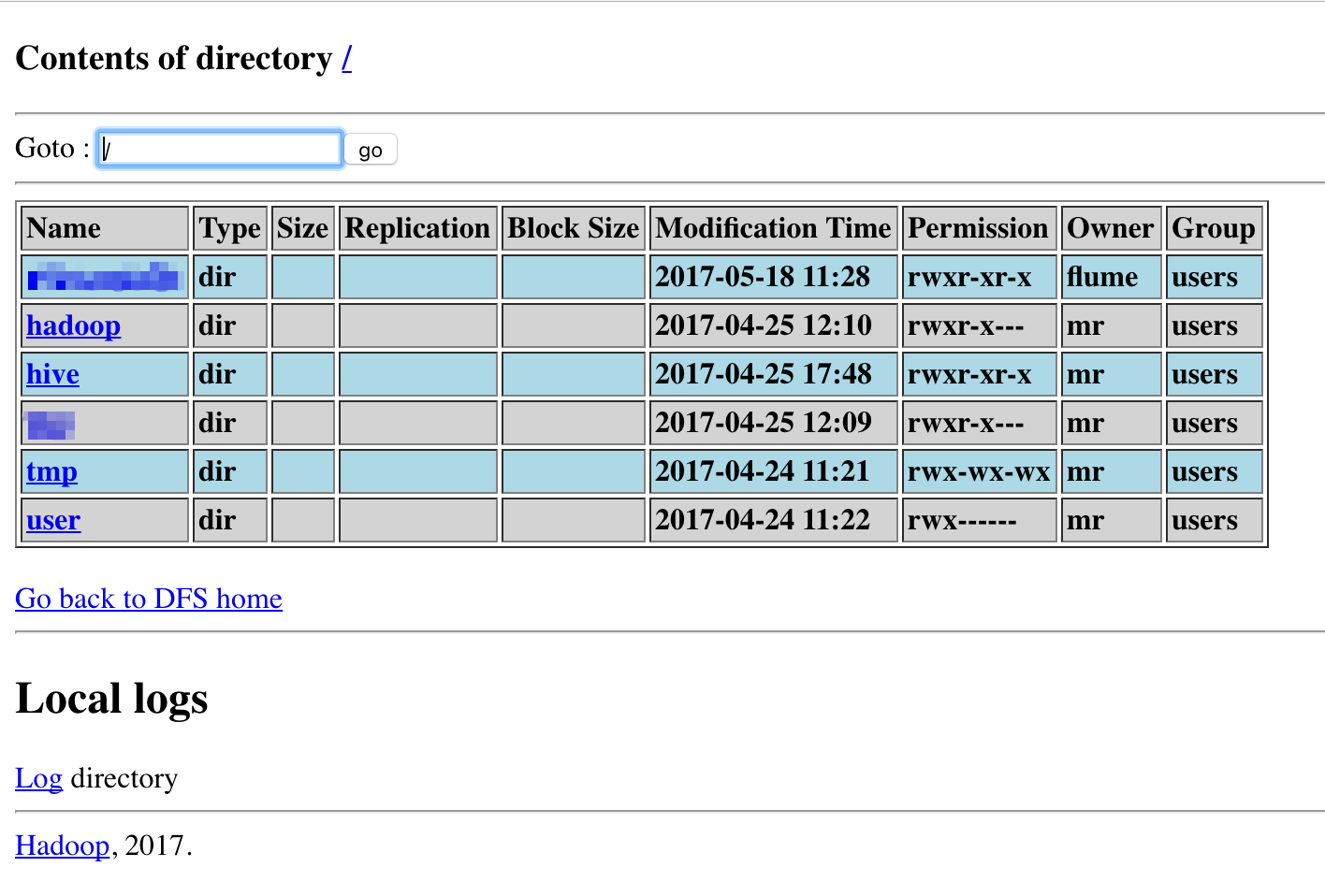
Mimo posiadania ~18TB przestrzeni dyskowej przez każdy serwer – na naszym przykładzie jest zajętych tylko 167.93MB przez dane umieszczone na rozproszonym systemie plików oraz 932.37GB poza nim. Z powyższego obrazu można odnieść wrażenie, że każdy z trzech serwerów przechowuje te same dane. Jest ono jak najbardziej niemylne, ponieważ standardowy współczynnik replikacji danych dla klastrów Hadoopa wynosi 3. Jeśli przejdziemy do zakładki Utilities -> Browse filesystem będziemy w stanie dobrać się do konkretnych plików:
Przeglądanie systemu plików.
Zanim dojdziemy do pojedynczych plików musimy “przeklikać” się przez strukturę podkatalogów na końcu których znajdować się będą interesujące nas obiekty:
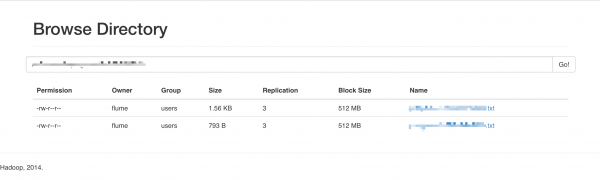
Hadoop FS.
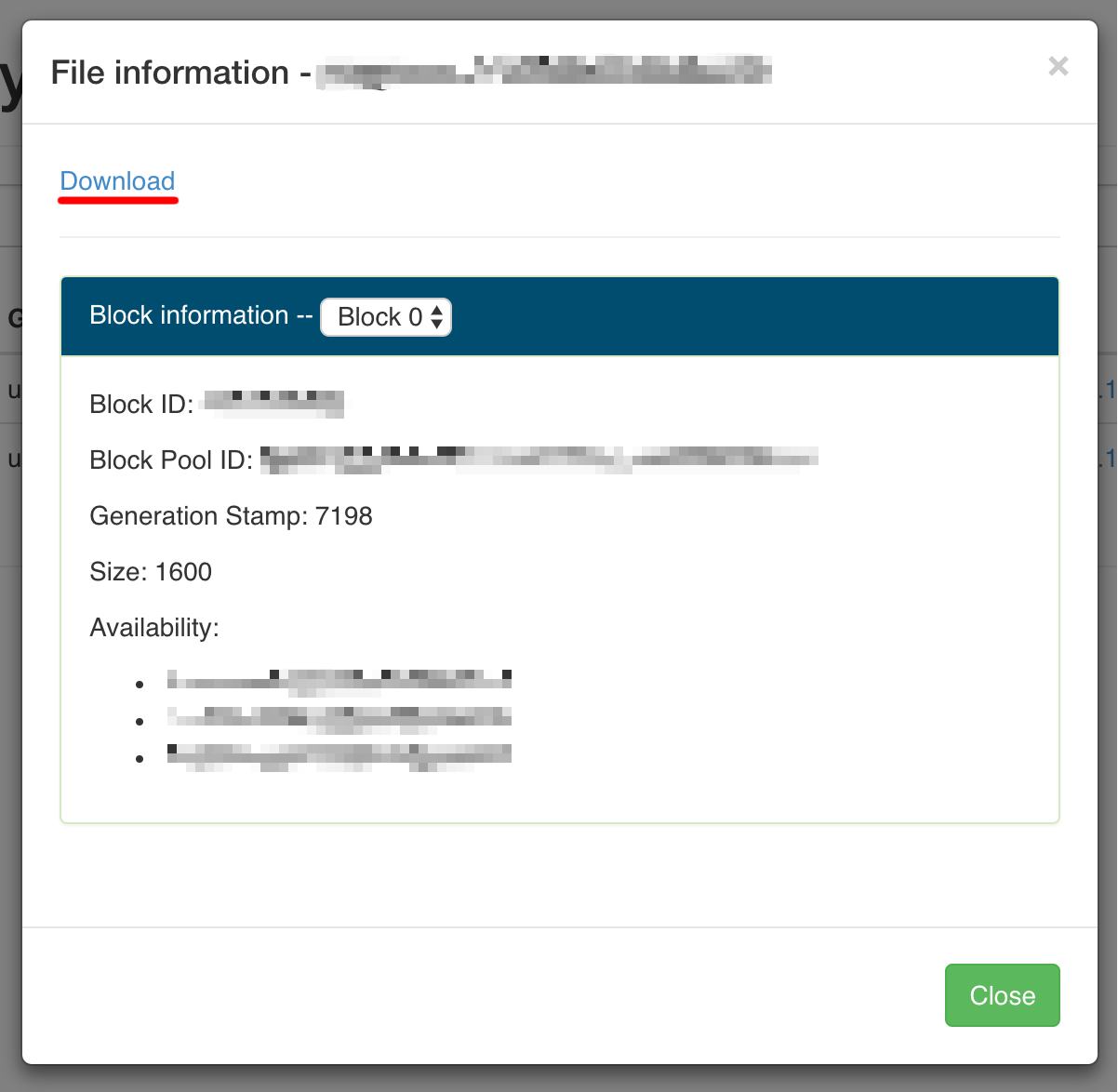
Spróbujmy pobrać jeden z dwóch dostępnych plików. Jeśli wybierzemy dany plik otrzymamy informacje o jego lokalizacji oraz rozmiarze:
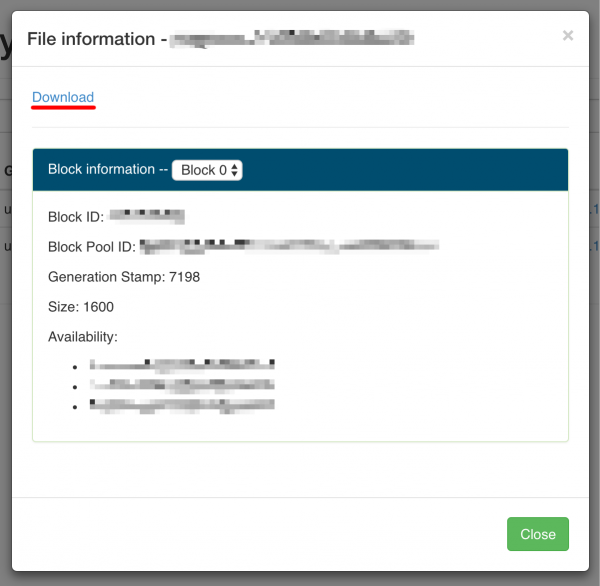
Informacje o konkretnym pliku.
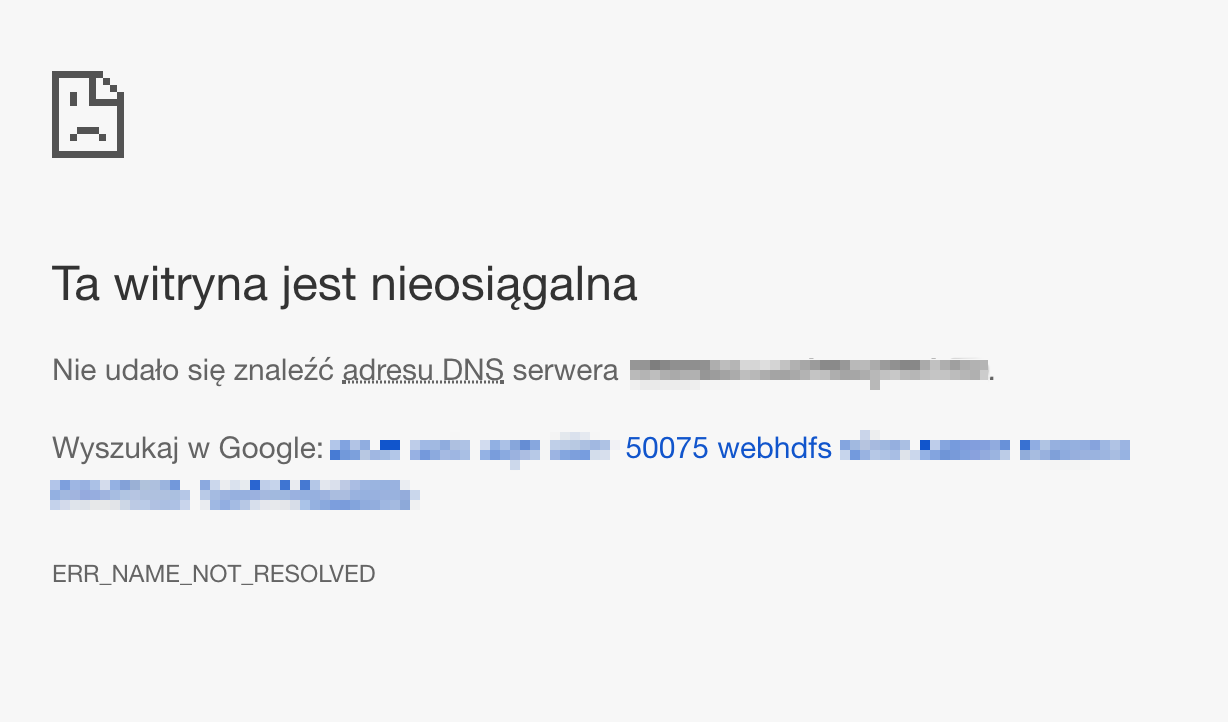
Niestety próba wykorzystania linku “Download” zakończy się niepowodzeniem:
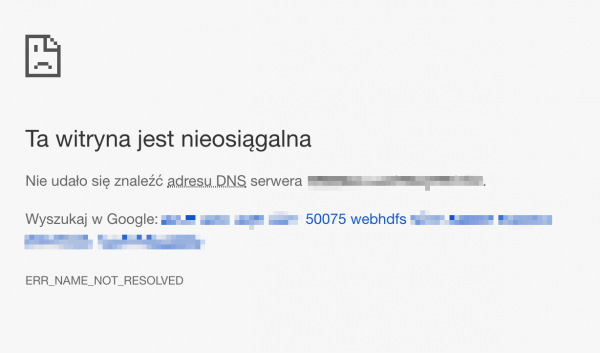
Niepowodzenie pobrania pliku.
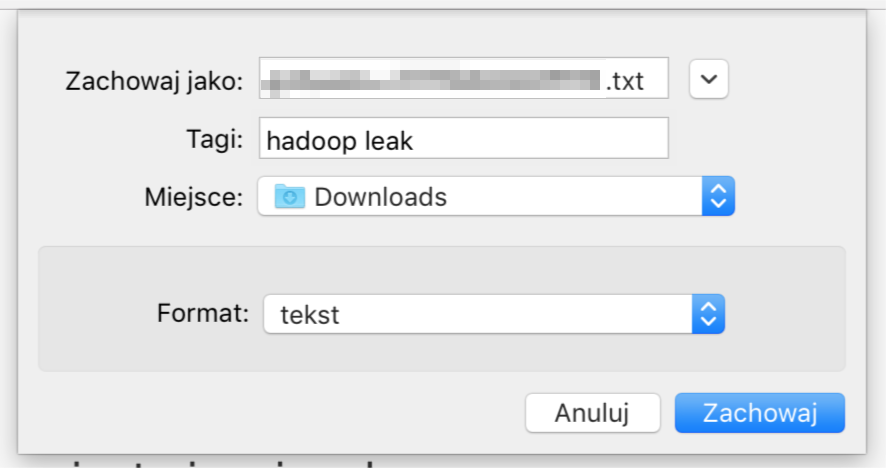
Jest to normalne, ponieważ serwery typu “Datanode” są zazwyczaj dostępne za pomocą wewnętrznych nazw domenowych, których nasza przeglądarka nie jest w stanie rozwiązać na konkretny adres IP. W tym wypadku wystarczy, że na pasku adresu URL prowadzącego do pobrania pliku podmienimy nazwę domeny na adres IP dowolnego serwera w roli datanode (pamiętając, że każdy przechowuje te same dane). Możemy również wpisać te nazwy domenowe oraz ich adresy IP do pliku /etc/hosts, co pozwoli naszej przeglądarce na rozwiązanie tych nazw. Adresy IP możemy zaczerpnąć z wcześniej pokazanej zakładki “Datanodes”. Jeśli porty serwerów przechowujących dane są dostępne z poziomu internetu będziemy w stanie zapisać plik na naszym lokalnym dysku:
Pobieranie pliku z datanode.
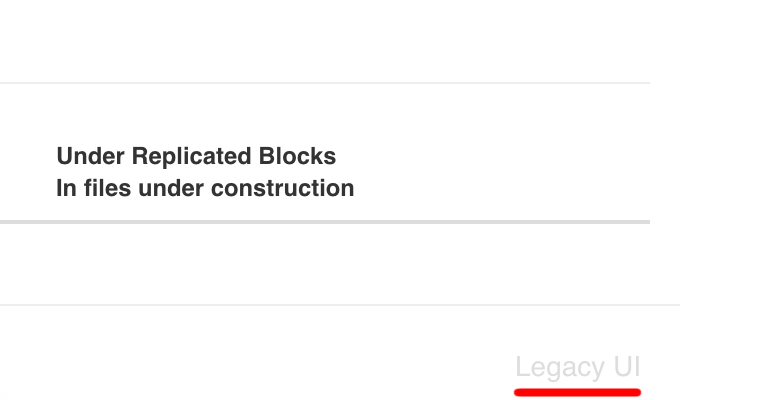
I na tym etapie ten prosty tutorial “klikania” mógłby się zakończyć. Pozostaje tylko odpowiedź na pytanie, co w przypadku trafienia na zabezpieczony klaster Hadoopa, który poprosi nas o konkretne dane uwierzytelniające, w przypadku podobnej chęci przeglądania jego zawartości? I tutaj pojawia się scena rodem z filmu “System”, w którym dostęp do wszystkich danych kryje magiczna ikona. W przypadku klastra Hadoop jest to wyszarzony link w prawym dolnym rogu o nazwie Legacy UI:
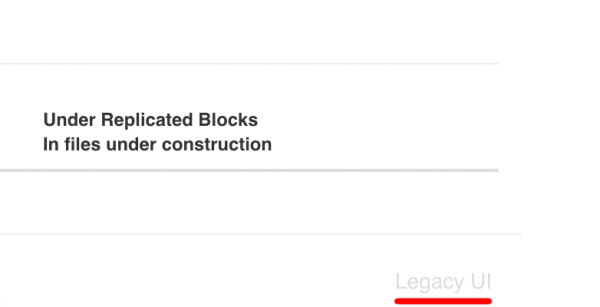
Jeśli link ten nie został “wycięty” ręcznie to powinien on być dostępny do wersji 2.7.0 Hadoopa. Korzystając z tego skrótu omijamy mechanizmy uwierzytelniania i jesteśmy przenoszeni do “starego” widoku, w którym analogicznie możemy wybrać “Browse the filesystem” w celu dostania się do konkretnych plików:
System plików przez Legacy UI
Podsumowanie
Apache Hadoop został stworzony w duchu społeczności open source z niewielkim lub wręcz zerowym naciskiem na bezpieczeństwo. Dopiero, gdy zaczął wchodzić do głównego nurtu obliczeń rozproszonych, a ludzie zaczęli zdawać sobie sprawę z jego ułomności pod tym względem – dystrybutorzy i społeczność Apache w przyśpieszonym tempie zaczęli tworzyć dodatki i funkcjonalności uzupełniające różne aspekty bezpieczeństwa. Pojawiła się możliwość kontroli dostępu i uwierzytelniania, autoryzacja, szyfrowanie oraz zarządzenie polityką bezpieczeństwa, czy możliwość monitorowania użytkowników. Niestety nadal implementacja większości z nich jest bardzo skomplikowana lub na tyle niedojrzała dla głównych odbiorców tego rozwiązania, że proces ten często jest pomijany. Bardzo wiele firm, co do zasady nie dzieli się zastosowanym podejściem do bezpieczeństwa informacji i nie dyskutuje o swoich implementacjach klastrów Hadoop. Ale na podstawie tego, co już o nim wiemy i jego całkowitym braku domyślnego bezpieczeństwa – perspektywa włamania się do klastra jest czymś, co powinno się traktować bardzo poważnie. Nie tylko jako zagrożenie z wewnątrz, ale również z zewnątrz.
– Patryk Krawaczyński




jak to jest, że nmap nie wskazuje na otwarte porty 50070 na tych danych hostach, a jednak można się tam dostać? 80 wystarczy?
“By default, Nmap scans the most common 1,000 ports for each protocol.”
Dzięki.