Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

OAuth 2.0 – jak działa / jak testować / problemy bezpieczeństwa
Potrzeba integracji różnych systemów informatycznych to już od jakiegoś czasu standard. Jeden z problemów, jaki może pojawić się po drodze, to kwestia udzielania dostępu do zasobów oraz skalowalności tego rozwiązania. Podobne kwestie podnoszone są, gdy zachodzi potrzeba udzielenia dostępu do systemu tylko w określonym zakresie. Jednym z zaproponowanych rozwiązań jest implementacja omawianego w tym artykule standardu OAuth 2.0.
Czym jest OAuth 2.0?
OAuth 2.0 jest otwartym protokołem pozwalającym na budowanie bezpiecznych mechanizmów autoryzacyjnych z wykorzystaniem różnych platform, np. aplikacji mobilnych lub WWW, ale również klasycznego oprogramowania. Cytat o niemal identycznej treści można znaleźć na oficjalnej stronie projektu. Lepiej oddający realia jest jednak tytuł dokumentu RFC 6749 zawierającego specyfikację omawianego standardu. Znajduje się tam informacja, że OAuth 2.0 to framework autoryzacyjny („The OAuth 2.0 Authorization Framework”). Słowo „framework” ma tutaj kluczowe znaczenie. W przeciwieństwie do strony projektu nie pojawia się tam stwierdzenie „protokół”. Jaka jest różnica? W przypadku protokołu wymagane jest ścisłe trzymanie się zasad określonych w specyfikacji. Podczas studiowania dokumentacji dotyczącej OAuth można zauważyć jednak, że w wielu miejscach specyfikacja luźno narzuca kwestię implementacji danych elementów standardu. Pozostawia to pole do interpretacji, czasem nadmiernej.
Docelowo OAuth 2.0 ma służyć delegacji autoryzacji do zasobów. Właściciel określonego zasobu może udzielić na określony czas oraz w zdefiniowanym z góry zakresie dostępu innemu podmiotowi. Przechodząc od opisów teoretycznych do praktycznego przykładu, można przytoczyć sytuację, w której udzielamy zewnętrznej aplikacji praw do odczytu danych z profilu Google, Facebooka lub Linkedin. Klasyczny scenariusz składa się z następujących kroków:
- Aplikacja chce uzyskać dane użytkownika, pobierając je z bazy dostawcy tożsamości, w tym celu wykonywane jest przekierowanie do serwera autoryzującego.
- Serwer autoryzujący przedstawia formularz z informacją o tym, że aplikacja chce uzyskać dostęp do określonych elementów profilu (np. pobrać podstawowe dane personalne oraz adres e-mail).
- Użytkownik w zależności od tego, czy akceptuje wymagania aplikacji, wydaje jej autoryzację lub nie.
- W przypadku udzielenia autoryzacji serwer wykonuje przekierowanie z powrotem do aplikacji, a ta otrzymuje specjalny token, za pomocą którego może pobrać wybrane dane z profilu użytkownika.
Głównym celem całego opisanego procesu jest uzyskanie wspomnianego tokenu będącego w większości przypadków wygenerowanym losowo ciągiem znaków o określonej długości. Token przesyłany jest następnie do serwera zasobów. Serwer ten z kolei odbiera go i sprawdza, czy podmiot, który go przedstawia, ma autoryzację do zasobów oraz operacji, które chce wykonać.
Wykorzystywana terminologia
Poznawanie zasady działania OAuth należy rozpocząć od zaznajomienia się z podstawową terminologią używaną w tym środowisku. Jest to szczególnie ważne ze względu na fakt, że niektóre z wykorzystywanych tu pojęć mają inne znaczenie niż przyjęto w powszechnej komunikacji dotyczącej oprogramowania i systemów komputerowych.
- Właściciel zasobu (ang. resource owner) – osoba lub inny podmiot będący właścicielem zasobu chronionego poprzez wymóg autoryzacji.
- Klient (ang. client) – w rozumieniu OAuth aplikacja, która chce uzyskać dostęp do zasobu.
- Serwer autoryzacyjny (ang. authorization server) – serwer udzielający w imieniu właściciela zasobu poświadczenia, na podstawie którego klient może uzyskać dostęp do chronionego zasobu.
- Serwer zasobu (ang. resource server) – serwer przechowujący chronione zasoby. W wielu przypadkach, w sensie logicznym, serwer ten jest tym samym, czym serwer autoryzacyjny.
- Zakres (ang. scope) – abstrakcyjna definicja określająca wybrany fragment uprawnień do chronionych zasobów. Definiowanie nazw zakresów oraz ich znaczenia leży po stronie serwera autoryzacyjnego.
- Access token – token wystawiany przez serwer autoryzacyjny, który klient może wykorzystać, by uzyskać dostęp do określonych zasobów.
W dalszej części artykułu słowo „token” należy rozumieć jako odniesienie do access tokenu. Analogicznie wykorzystanie nazwy OAuth ma w zamyśle wersję 2.0 tego standardu.
Zasada działania OAuth
Specyfikacja wersji 2.0 standardu OAuth przewiduje kilka scenariuszy pozyskania tokena. Najczęściej spotykany z nich zakłada, że w proces pozyskiwania tokenu będą zaangażowane co najmniej trzy strony: klient, właściciel zasobu oraz serwer autoryzacyjny. Taka metoda nazywa się Authorization Code Flow.
Pierwszym krokiem wymaganym do tego, by rozpocząć proces pozyskiwania tokenu jest zarejestrowanie klienta w serwerze autoryzacyjnym. Proces ten polega na podaniu identyfikatora klienta (ang. client id), adresu zwrotnego (ang. redirect URL) oraz wygenerowaniu tzw. sekretu (ang. client secret). Para: identyfikator oraz sekret jest wymagana ze względu na konieczność identyfikacji klienta. Adres zwrotny ma na celu zdefiniowanie, pod jaki adres serwer autoryzacyjny ma wykonać przekierowanie po udanym procesie autoryzacji.
Na potrzeby artykułu wykorzystywane są dwie aplikacje, jedna będąca klientem – client.local oraz authsrv.local pełniąca rolę serwera autoryzującego. Klient – profileeditor-client – wcześniej zarejestrowany w serwerze – ma za zadanie uzyskać od serwera autoryzację do wykonania operacji określonych poprzez przykładowe zakresy get_name i edit_name (pobranie danych personalnych oraz możliwość ich edycji). Takie założenia powodują, że klient musi wygenerować następujące zapytanie HTTP (np. wykonując przekierowanie w przeglądarce właściciela zasobu):
GET /auth?response_type=code&scope=get_name%20edit_name&client_id= profileeditor-client&redirect_uri=https://client.local/callback HTTP/1.1 Host: authsrv.local
Listing 1. Pierwszy etap Authorization Code Flow
Zapytanie składa się z kilku elementów:
- response_type – zmienna definiująca metodę pozyskiwania tokenu, więcej metod omówionych zostanie poniżej.
- scope – zmienna zawierająca listę zakresów (ang. scope) definiujących uprawnienia, jakie mają zostać nadanie klientowi. Zgodnie z specyfikacją kolejne zakresy oddzielane są od siebie spacją, którą w adresie URL reprezentuje wartość %20.
- client_id – zmienna informująca o tym, jaki klient występuje z żądaniem uzyskania autoryzacji.
- redirect_uri – informacja o adresie, na jaki ma przesłać odpowiedź serwer.
Przesłanie takiego zapytania informuje serwer autoryzacyjny authsrv.local, że klient o identyfikatorze profileeditor-client chce uzyskać możliwość pobrania podstawowych danych użytkownika (zakres get_name) oraz ich edycji (edit_name). Dodatkowo kod autoryzacyjny (authorization_code) ma zostać wysłany pod adres https://client.local/callback – parametr redirect_uri. Kolejnym krokiem jest sprawdzenie, czy właściciel zasobu, w imieniu którego wykonywany jest cały ten proces, jest już uwierzytelniony w serwerze autoryzacji. Jeżeli tak nie jest, w przeglądarce wyświetlany jest tzw. consent screen (Rysunek 1).
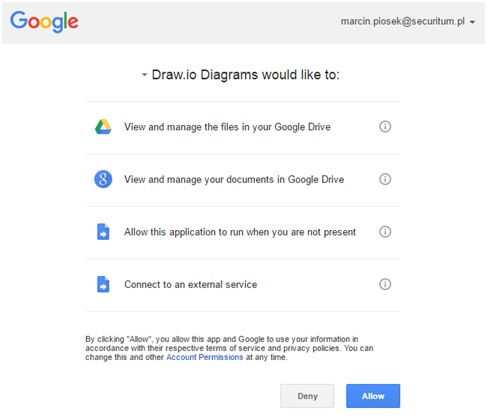
Rysunek 1. Przykładowy consent screen (Źródło).
Formularz ten ma na celu przedstawić właścicielowi zasobu w przejrzysty sposób, jakie uprawnienia chce uzyskać klient. Jeżeli wymagania klienta mogą zostać zaakceptowane, proces autoryzacji zatwierdza się poprzez wybranie odpowiedniej opcji.
Jeśli użytkownik zgodzi się na delegowanie uprawnień, serwer autoryzacyjny wykona przekierowanie z powrotem do klienta, co wygeneruje następujące zapytanie HTTP (Listing 2):
GET /callback?authorization_code=<wygenerowany authorization code> HTTP/1.1 Host: client.local
Listing 2. Odpowiedź serwera z wygenerowanym kodem dostępu
W adresie URL zostanie przesłany tzw. kod autoryzacyjny. Nie jest to jednak to samo co token. W kolejnym kroku klient wykona bezpośrednie zapytanie do serwera autoryzacyjnego o treści przedstawionej w Listingu 3.
POST /get_token Host: authsrv.local client_id=sekurak&client_secret=[removed]&grant_type=authorization_code&redirect_uri=http://client.local/callback&code=<wygenerowany authorization code>
Listing 3. Zapytanie wysyłane do serwera w celu pozyskania tokenu
W zapytaniu przesyłany jest otrzymany kod autoryzujący oraz identyfikator i sekret klienta pozwalający na jego identyfikację. Jeżeli wszystkie przesłane dane są poprawne, serwer autoryzujący powinien odpowiedzieć w sposób podobny do tego zaprezentowanego w Listingu 4.
HTTP 200 OK
Date: Mon, 10 Aug 2016 12:39:13 GMT
Content-type: application/json
{
"access_token": "6fgg1147fA781bc3fE9Rr312",
"token_type": "Bearer"
}
Listing 4. Odpowiedź serwera wraz z wygenerowanym tokenem
Taka odpowiedź świadczy o tym, że serwer pomyślnie zweryfikował tożsamość klienta oraz wartość kodu autoryzującego. Od teraz klient może wykorzystywać pozyskany token do uzyskania dostępu do chronionego API (Listing 5):
GET /protected_resource HTTP/1.1 Host: authsrv.local Authorization: Bearer 6fgg1147fA781bc3fE9Rr312
Listing 5. Przykładowe zapytanie wysyłane do API
Korzyści wynikające z wykorzystania OAuth
Znając podstawowy mechanizm działania OAuth, można wyciągnąć pierwsze wnioski na temat najważniejszych korzyści wynikających z jego zastosowania:
- Klienci, czyli zewnętrzne aplikacje, nie mają styczności z danymi uwierzytelniającymi użytkowników.
- Istnieje możliwość wykorzystania jednego serwera autoryzującego do chronienia wielu różnych zasobów.
- Dzięki wykorzystaniu wielokrotnie jednego serwera autoryzacji ogranicza się ilość kont zakładanych w różnych aplikacjach, a przez to ryzyko wykorzystania tego samego hasła w różnych usługach.
Krok w tył – czym OAuth nie jest
Przejście do dalszego poznawania OAuth ma sens tylko wtedy, jeżeli rozumie się różnicę pomiędzy pojęciem uwierzytelnienia a autoryzacją. Pierwsze z tych pojęć określa proces, w którym weryfikowana jest tożsamość podmiotu. Autoryzacja z kolei występuje, gdy system sprawdza, czy już zidentyfikowany (uwierzytelniony) podmiot ma uprawnienia do zasobu, na którym chce wykonać określoną akcję, np. odczyt, modyfikację lub usunięcie.
Dlaczego jest to takie ważne? OAuth powinien być wykorzystywany tylko do autoryzacji. Istnieje techniczna możliwość wykorzystania OAuth do uwierzytelnienia, a dokładniej mówiąc: przygotowania serwera autoryzującego tak, by mógł zwrócić informacje na temat tożsamości podmiotu, w imieniu którego został wystawiony token. Oficjalna dokumentacja OAuth zawiera jednak informację:
OAuth 2.0 is not an authentication protocol.
Brak zrozumienia tej kwestii prowadzi do powstawania implementacji, które wykorzystują OAuth również do uwierzytelnienia.
Jako przykład można przytoczyć sytuację, w której wystawiane jest upoważnienie (token) dla znajomego (klient), którego zadaniem jest załatwić w urzędzie (serwer zasobów) w naszym imieniu określoną sprawę (zakresy). W takiej sytuacji znajomy jest autoryzowany do wykonania w naszym imieniu pewnych akcji, jednak, nie staje się nami samymi (właściciel zasobu). Znajomy w urzędzie dalej występuje pod swoim własnym nazwiskiem (client id).
Wykorzystanie OAuth do uwierzytelnienia należy traktować jako błąd m.in. dlatego, że generuje to kilka problemów:
- Tokeny zaczynają być traktowane jako poświadczenie uwierzytelnienia w systemie – należy tutaj przypomnieć, że głównym założeniem OAuth jest delegowanie autoryzacji.
- Dostęp do chronionego fragmentu systemu traktowany jest jako dowód na uwierzytelnienie.
- Założenia wykorzystania tokenu na okaziciela (Bearer token) powoduje, że każdy, kto posiada taki token, może podszyć się pod wybraną tożsamość.
Jeżeli szukamy mechanizmu, który pozwala na poprawne zaimplementowanie uwierzytelnienia, nasze zainteresowanie powinno skierować się ku protokołowi OpenID Connect. Rozwiązanie to opiera się o OAuth, jednak zostało rozszerzone o elementy pozwalające na zarządzanie tożsamością posiadacza tokenu.
Zachęcając do dalszej lektury, można tutaj napisać, że podobnych smaczków w OAuth jest znacznie więcej.
Pozostałe metody pozyskiwania tokenu
Metoda Authorization Code pozwala na pozyskanie tokenu poprzez wygenerowanie w pierwszej kolejności kodu autoryzującego, a później wymienienie go po stronie serwera na token. Taki proces sprawdza się, gdy klient jest aplikacją uruchomioną po stronie serwera. Istnieją jednak scenariusze, gdy klient uruchomiony jest np. bezpośrednio w przeglądarce. Jak w takim przypadku bezpiecznie pozyskać token?
Implicit Grant
Metoda Implicit Grant sprawdza się, gdy klient jest aplikacją JavaScript uruchomioną w przeglądarce. Pierwszy krok – zapytanie wysyłane do serwera autoryzującego – wygląda bardzo podobnie do trybu Authorization Code. Główną różnicą jest inna wartość parametru response_type (Listing 6):
GET /auth?response_type=token&scope=get_name%20edit_name&client_id= profileeditor-client&redirect_uri=https://client.local/callback HTTP/1.1 Host: authsrv.local
Listing 6. Zapytanie do serwera autoryzującego wykorzystujące Implicit Grant Flow
Serwer autoryzacyjny po odebraniu takiego zapytania zweryfikuje, czy użytkownik jest już uwierzytelniony. Jeżeli nie, poprosi o podanie danych uwierzytelniających, a następnie w zależności od potrzeby wyświetli consent screen. Wymienione do tej pory elementy są identyczne, jak w przypadku trybu Authorization Code. Pierwsza różnica pojawia się w sposobie, w jaki serwer zwraca token (Listing 7).
HTTP/1.1 302 Moved Temporarily Location: https://client.local/callback#access_token=afgg1147fA781bc3fE9Rr312&token_type=Bearer
Listing 7. Odpowiedź wygenerowana przez serwer, w której wykonywane jest przekierowanie do klienta
To, co charakterystyczne dla tej metody, to fakt, że token zostanie przesłany w adresie URL, ale nie jako parametr, a wartość po znaku hash. Jest to o tyle istotne, ponieważ to, co znajduje się po znaku hash, nie zostanie nigdy wysłane do serwera, na którym uruchomiona jest aplikacja. Klient JavaScript uruchomiony w przeglądarce może bezpośrednio pobrać token z adresu URL i wykorzystać go do kolejnych zapytań (Listing 8):
GET /protected_resource HTTP/1.1 Host: authsrv.local Authorization: Bearer afgg1147fA781bc3fE9Rr312
Listing 8. Przykładowe zapytanie, jakie można wysłać do API z pozyskanym tokenem
Client credentials
W przypadku, gdy integrowane są z sobą dwa systemy, w których nie występuje bezpośrednio właściciel podmiotu będący człowiekiem, pomocny może być tryb Client credentials. Jest on jeszcze bardziej uproszczony w stosunku do poprzednich trybów, ponieważ klient wysyła jedynie do serwera autoryzującego swój identyfikator i sekret (Listing 9).
POST /get_token Host: authsrv.local client_id=sekurak&client_secret=<sekret klienta>&grant_type= client_credentials&scope=get_name%20edit_name
Listing 9. Przykładowe zapytanie do serwera autoryzującego, wykorzystując Client Credentials Flow
Po odebraniu takiego zapytania serwer weryfikuje przesłane dane i jeżeli wszystko się zgadza – generuje token (Listing 10):
HTTP 200 OK
Content-type: application/json
{
"access_token": "6fgg1147fA781bc3fE9Rr312",
"token_type": "Bearer"
}
Listing 10. Odpowiedź serwera wraz w wygenerowanym tokenem
Resource owner credentials
Jedną z ważniejszych idei stojących za wykorzystaniem OAuth jest możliwość odseparowania klienta od danych uwierzytelniających właściciela zasobu. Specyfikacja OAuth przewiduje jednak możliwość wykorzystania metody pozyskiwania tokenu, która zakłada, że klient może poprosić o dane uwierzytelniające użytkownika (np. login i hasło). Przykładowe zapytanie z wykorzystaniem tej metody zostało przedstawione w Listingu 11:
POST /get_token Host: authsrv.local client_id=sekurak&client_secret=<sekret klienta>&grant_type=password&scope=get_name%20edit_name&username=admin&password=<hasło właściciela zasobu>
Listing 11. Zapytanie do serwera autoryzującego z wykorzystaniem Resource Owner Flow
Oczywiście nie jest to zalecany tryb ze względu na fakt, że zaprzecza idei separacji klienta i danych uwierzytelniających właściciela zasobu.
Jaką metodę pozyskiwania tokenu wybrać?
Jeżeli mamy do czynienia z klientem uruchomionym w przeglądarce WWW, powinniśmy zainteresować się trybem Implicit Grant. W przypadku, gdy klient, którego chcemy dopuścić do zasobów, pochodzi z zaufanego źródła, np. jego autorem jest partner biznesowy lub klient jest elementem tworzonego przez nas oprogramowania, a dodatkowo w scenariuszu projektowym nie występuje właściciel zasobu w jawnej postaci, tryb Client credentials flow powinien zdać egzamin. W najbardziej popularnym przypadku, gdy jednym z elementów procesu pozyskiwania tokenu jest właściciel zasobu wykorzystujący przeglądarkę WWW, a klient to niezaufana aplikacja trzecia, zastosowanie powinien znaleźć najbardziej popularny Authorization Code Flow. Jeżeli nasze wymagania projektowe sugerują, że najbardziej będzie do nich pasować tryb Resource Owner Credentials, wtedy powinniśmy jeszcze raz przemyśleć te założenia.
Co może pójść nie tak
Powyższy wstęp teoretyczny pozwolił zaznajomić się z podstawowymi zasadami działania OAuth 2.0 oraz poznać jego najważniejsze składniki. Należy się teraz zastanowić, jakie zagrożenia wiążą się z każdym z tych elementów. Raz jeszcze należy uwzględnić fakt, że specyfikacja OAuth 2.0 nie jest tym samym, czym np. specyfikacja TCP. W drugim przypadku mówimy o protokole, czyli ścisłym zestawie reguł. OAuth jest zbiorem założeń, w których część może działać zgodnie z specyfikacją, a część nie. Warto zadać pytanie, co może pójść nie tak w trakcie implementacji OAuth 2.0?
Brak szyfrowanego kanału komunikacji
Wyliczanie potencjalnych zagrożeń związanych z OAuth należy rozpocząć od kwestii fundamentalnych, a mianowicie od tematu szyfrowanego kanału komunikacji. W porównaniu do wersji 1.0 standardu OAuth w wersji 2.0 całkowicie wycofano wszelkie mechanizmy szyfrowania przesyłanej komunikacji. Dlatego też, wykorzystując protokół OAuth, kluczową kwestią jest zadbanie o to, by całość komunikacji była szyfrowana przy pomocy TLS. Wyciek tokenu jest równoznaczny z możliwością wykorzystania go przez inny podmiot do uzyskania dostępu do zasobów.
Wdrażając szyfrowany kanał komunikacji, warto również pomyśleć o jego hardeningu.
Serwer autoryzujący
Listę zagrożeń dla serwera autoryzującego najlepiej stworzyć na podstawie jego umiejscowienia w systemie oraz przypisanych zadań.
Jednym z działań, jakie przyjdzie wykonać osobie chcącej wykorzystać serwer OAuth, będzie konieczność zarejestrowania w nim klienta. Zadaniem serwera jest pobrać od użytkownika nazwę klienta, dzięki której będzie on identyfikowany w systemie, oraz adres przekierowania, pod który serwer wykonana przekierowanie po pomyślnym procesie delegowania uprawnień. Dodatkowo, jeżeli zezwala na to przyjęta polityka bezpieczeństwa, można właścicielowi klienta pozwolić na modyfikację czasu życia tokenu – ale tylko w zakresie niestanowiącym naruszeń dobrych praktyk. Dobrym założeniem jest również pobieranie informacji o domenie, z której serwer autoryzacyjny powinien spodziewać się żądania o wydanie tokena lub kodu dostępu. Po wprowadzeniu takich danych oraz ich pomyślnej walidacji serwer powinien wygenerować parę danych będących identyfikatorem klienta (client_id) oraz sekretem (client_secret). Część serwerów pozwala na wybranie identyfikatora klienta, a generuje jedynie sekret – o ile serwer sprawdza, czy identyfikator nie jest zbyt trywialny, nie ma tutaj jednoznacznych zaleceń lub wyraźnego podziału na lepsze lub gorsze rozwiązanie.
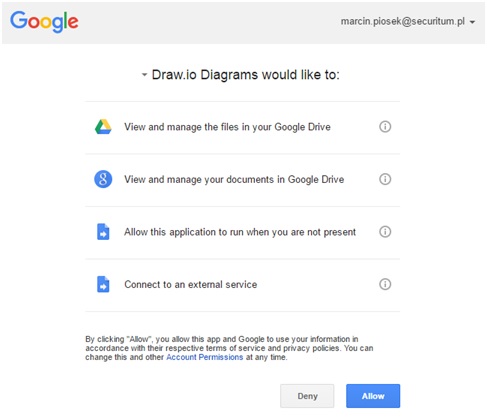
Rysunek 2. Formularz pozwalający na tworzenie nowych klientów (źródło).
Głównym zadaniem serwera jest wydawanie tokenów, a wcześniej – odpowiednie uwierzytelnienie właściciela zasobu. Specyfikacja OAuth nie definiuje, w jaki sposób – lub na podstawie jakiego typu poświadczeń – ma przebiegać ten proces. Zadaniem serwera autoryzującego jest jednak zweryfikowanie, czy właściciel zasobu posiada odpowiednie uprawnienia do tego, by delegować dostęp do określonego zasobu.
Serwer autoryzacyjny odbiera dane od klienta i przygotowuje się do procesu nadawania mu uprawnień. Na tym etapie należy zweryfikować, czy uprawnienia, o które prosi klient, są możliwe do nadania. Na przykład klient może poprosić o uprawnienia do nieistniejących zakresów lub takich, które dają dostęp do zasobów administracyjnych. Należy zadbać o to, by aplikacja w odpowiedni sposób obsługiwała takie przypadki.
Kwestią dyskusyjną jest również wprowadzenie ochrony przed ewentualnymi atakami siłowymi, jakie można przeprowadzić przeciwko serwerowi autoryzującymi. Technicznie możliwe jest przeprowadzenie prób odgadnięcia tokenu lub danych uwierzytelniających klienta, dlatego też serwer powinien być przygotowany na odparcie takich prób.
W przypadku aplikacji WWW po pomyślnym uwierzytelnieniu właściciela zasobu jest on przekierowywany do consent screen. Jest to ekran, na którym prezentowane są właścicielowi informacje na temat tego, do jakich zasobów klient chce uzyskać uprawnienia. Wszystkie kwestie związane z tym mechanizmem zostały opisane w osobnym punkcie.
Gdy właściciel zasobu wyrazi zgodę na delegowanie określonych uprawnień do klienta, należy te ustawienia zapamiętać oraz wygenerować odpowiedni token. Ważne jest, by zapisać w bazie danych informację o tym, na jakiego klienta został wygenerowany określony token. Częstym problemem w przypadku autorskich serwerów autoryzujących jest niepowiązanie tokenu z określonym klientem.
Nadanie odpowiednich uprawnień klientowi oraz wydanie tokena lub kodu dostępu kończy się wykonaniem przekierowania do adresu zdefiniowanego przez klienta jako redirect_uri. Jeżeli adres ten został wcześniej zarejestrowany, należy zweryfikować, czy ten podany w redirect_uri jest identyczny jak adres zapisany w bazie. Walidacja adresu, pod który zostanie wykonane przekierowanie, powinna być możliwie najbardziej ścisła i na tym etapie można narzucić pewne polityki dotyczące dobrych praktyk. Na przykład niezalecane jest wykonywanie przekierowania do stron nie wykorzystujących szyfrowanego kanału komunikacji (HTTPS). Należy również zweryfikować, czy podany adres przekierowania jest jak najbardziej dokładny – nie powinno się zezwalać na przekierowanie do całych głównych domen (np. https://clientapp/), ale wymagać podania konkretnego zasobu (np. https://clientapp/auth_endpoint). Ważne jest również sprawdzanie, czy podany adres jest identyczny jak zarejestrowany i odrzucać żądania z jakimikolwiek odstępstwami. Na przykład jeżeli zarejestrowany adres to https://clientapp/auth_endpoint, a serwer otrzymał zapytanie z adresem ustawionym na https://clientapp/auth_endpoint/other_path, to zapytanie powinno zostać odrzucone.
Dlaczego jest to ważne? W sieci możemy znaleźć sporo opisów podatności w dużych serwisach, gdzie właśnie brak odpowiednio skrojonej polityki walidowania adresu przekierowania przyczynił się do możliwości przeprowadzenia groźnych ataków:
- http://www.nirgoldshlager.com/2013/02/how-i-hacked-facebook-oauth-to-get-full.html
- http://homakov.blogspot.ch/2014/02/how-i-hacked-github-again.html
Wdrażając politykę walidowania adresu przekierowania, można przyjąć zasady podobne do tych, jakie stosowane są w Same Origin Policy.
Po stronie serwera autoryzującego zaleca się również wymuszanie wygenerowania oraz przesłania przez klienta parametru state. Można go sklasyfikować jako zabezpieczenie chroniące przed atakami Cross-Site Request Forgery. Zadaniem klienta jest wygenerować parametr state i wysłać go przy przekierowaniu właściciela zasobu do serwera autoryzującego. Zadaniem serwera natomiast jest odebranie ten parametr, a następnie w niezmienionej formie odesłanie do klienta. Jako że całość odbywa się na warstwie zapytań http, warto w przypadku parametru state, ale również pozostałych wykorzystywanych w procesie pozyskiwania tokenu, zweryfikować, czy przy odbieraniu i wysyłaniu tokenu nie występuje podatność na HTTP Response Splitting.
Zadaniem serwera autoryzującego jest również obsługa odpowiedniej ilości wymaganych zakresów. W zależności od zastosowań projektowych oraz ilości zasobów, jakie podlegają ochronie, zaleca się przygotowanie ich odpowiedniej ilości. Nie powinno się opierać dostępu na tylko jednym zakresie, z drugiej jednak strony nie można z ilością tych zakresów przesadzić. Na przykład, jeżeli mamy system, w którym użytkownik może zmodyfikować swój profil oraz dodawać i czytać artykuły, można rozważyć wprowadzenie następujących zakresów:
- profile – dostęp do danych profilowych,
- articles – dostęp do artykułów.
Oprócz podziału wertykalnego można również wprowadzić podział horyzontalny poprzez rozdzielenie typów operacji (odczyt, modyfikacja, usuwanie), jakie klient może wykonać na danym zasobie:
- profile_get – odczyt danych profilowych,
- profile_edit – modyfikacja danych profilowych,
- articles_get – odczyt artykułów,
- articles_edit – modyfikacja treści artykułów.
Oczywiście zaprezentowany tutaj przykład należy dostosować do konkretnych wymagań projektowych. Należy również pamiętać o tym, że wydanie tokena pozwalającego na dostęp do wybranego zakresu to jedno, a walidowanie tego po stronie serwera to drugie. W aplikacjach implementujących OAuth można również spotkać się z sytuacją, w której serwer sprawdza, czy określony token został wystawiony, ale nie jest uwzględniona weryfikacja, czy token zezwala na dostęp tylko do wybranych zasobów zdefiniowanych przez określone zakresy.
Serwer autoryzacyjny powinien również uwzględniać możliwość unieważnienia wystawionego tokenu. Przeważnie jest to realizowane poprzez udostępnienie odpowiedniej metody, a odwołanie się do niej powoduje wygaśnięcie ważności tokena (Listing 12):
POST /revoke HTTP/1.1 Host: authsrv.local token=6fgg1147fA781bc3fE9Rr312
Listing 12. Przykładowe zapytanie wysyłane do metody unieważniającej token
Poruszając temat unieważniania tokenów, należy również wspomnieć o funkcji jego odświeżania. Jeżeli zdecydujemy się udostępnić klientom taką funkcję, oprócz zwykłego tokenu generowany będzie również dodatkowy token pozwalający na wygenerowanie nowego tokena, gdy oryginalny wygaśnie. Jest to często spotykana praktyka, gdy chcemy udostępnić klientowi dostęp do zasobów, na przykład gdy właściciel zasobu będący osobą nie będzie obecny fizycznie przy komputerze. Częsty błąd, jaki tutaj występuje, polega na niesprawdzaniu powiązania pomiędzy refresh tokenem a klientem, dla jakiego został on wystawiony. Inną złą praktyką jest jedynie odświeżanie czasu życia starego tokenu zamiast generowania nowego.
Uwzględniając fakt, że zarówno tokeny, jak i kody dostępu mogą teoretycznie wyciec z serwera, zaleca się, aby przechowywał on jedynie wynik funkcji skrótu na wartości tokenu, a nie token w postaci jawnej.
Dobrą praktyką jest również udostępnianie właścicielowi zasobu odpowiedniego panelu WWW, dzięki któremu będzie mógł zweryfikować już delegowane uprawnienia, jak i w razie potrzeby je usunąć (Rysunek 3).
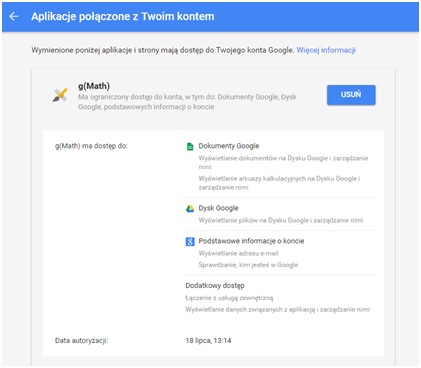
Rysunek 3. Przykładowy formularz pozwalający na zarządzanie udzieloną autoryzacją (źródło).
W przypadku, gdy w zastosowanej implementacji OAuth jasno rozdziela się rolę serwera autoryzującego oraz serwera zasobów, a tych drugich jest więcej niż jeden, należy pamiętać o tym, by wystawiony przez serwer token jasno powiązać z określonym serwerem zasobu i uwzględniać to przy walidacji tokenu.
Na koniec warto wspomnieć o tym, że serwer autoryzacyjny jest niczym innym niż zwykłą aplikacją WWW narażoną na standardowe dla tej klasy oprogramowania ataki – od wstrzyknięć oraz kwestii bezpiecznego przechowywania poświadczeń, aż po brak lub błędną konfigurację nagłówków bezpieczeństwa HTTP. Serwer autoryzacyjny jest również elementem systemu, który można określić jako single point of failure – niedostępność tego elementu może oznaczać odcięcie dostępu do wielu usług, dlatego też należy zadbać o jego odpowiednią redundancję i odporność na ataki odmowy dostępu (ang. Denial of Service).
Klient
W przypadku OAuth klient jest elementem systemu, któremu powierzane są pewne uprawnienia. Są one reprezentowane przez generowany dla niego token i to na podstawie tego tokena klient może wykonywać określone operacje w imieniu właściciela zasobu. Zadaniem klienta jest więc zadbać o to, by token był przechowywany w odpowiedni sposób tak, by nie dopuścić do jego wycieku zarówno w przypadku klasycznych ataków, tj. SQL Injection, ale również np. w przypadku wystąpienia błędu w aplikacji i komunikatu błędu z tym związanego. Kwestia ta dotyczy zarówno tokenu, jak i tokenu pozwalającego na odświeżanie (refresh_token).
Osobna kwestia to przechowywanie tokenu w ciasteczkach przeglądarki lub z wykorzystaniem mechanizmu localStorage. Zarówno jedno, jak i drugie rozwiązanie ma swoje negatywne strony, a wszystkie związane są z atakami Cross-Site Scripting (XSS) oraz Cross-Site Request Forgery (CSRF). W przypadku przechowywania tokenów w ciasteczkach nie możemy ustawić dla nich flagi HttpOnly ponieważ ciasteczka stają się niedostępne z poziomu kodu JavaScript. Wykorzystanie drugiego podejścia polegającego na zapisywaniu tokenu w localStorage również nie jest idealnie, ponieważ nie mamy możliwości narzucenia jakiejkolwiek polityki dotyczącej dostępu do danych i pojawienie się podatności na XSS jest równoznaczne z możliwością pozyskania tokenu przez atakującego.
Zanim klient uzyska token, musi jeszcze zadbać o odpowiednie zabezpieczenie swoich poświadczeń. Bardzo drażliwą kwestią jest osadzanie client_id oraz client_secret w kodzie aplikacji, które są następnie dystrybuowane na rynku. Na przykład poświadczenia klienta, które zostały zapisane na stałe w kodzie aplikacji mobilnej, powinny zostać automatycznie sklasyfikowane jako skompromitowane. Nawet jeżeli dołożono starań, by odkrycie ich wartości było utrudnione, taka sytuacja nie różni się niczym od zapisania na stałe w kodzie aplikacji danych uwierzytelniających do serwera (S)FTP. Kwestii dobrych praktyk związanych z wykorzystaniem OAuth w aplikacjach mobilnych został poświęcony osobny akapit.
Klient jest również elementem systemu, który inicjalizuje proces pozyskiwania tokenu najczęściej poprzez przekierowanie właściciela zasobu do serwera autoryzującego. Zaleca się, aby przekierowanie do serwera oprócz standardowych parametrów takich jak redirect_uri czy response_type zawierało również parametr state. Zadaniem klienta jest wygenerować losowy ciąg znaków, umieścić go w żądaniu do serwera, a następnie sprawdzić, czy w odpowiedzi od serwera został on zwrócony w niezmienionej formie. Jak zostało to już wcześniej zaznaczone, takie zabezpieczenie ma chronić przez formami ataku Cross-Site Request Forgery (CSRF).
Jedną z głównych zalet wykorzystania OAuth jest oddzielenie podmiotu, któremu udzielany jest dostęp do zasobów – naszego klienta – od poświadczeń właściciela zasobu (najczęściej loginu i hasła). Dlatego też zaleca się, aby klient nie wymagał od właściciela zasobu podania danych uwierzytelniających. Można to sprowadzić do zalecenia unikania wykorzystania sposobu pozyskiwania tokenu nazywanego Resource Owner Credentials Flow.
Tokeny oraz kody dostępu
Jedną z dobrych praktyk dotyczących tworzenia aplikacji WWW jest zalecenie unikania przesyłania w adresie URL różnego typu poświadczeń – mowa tutaj zarówno o danych uwierzytelniających użytkownika (np. login i hasło wysyłane metodą GET), ale również identyfikatorów sesji. Stoi to w pewnej sprzeczności z faktem, że zarówno w przypadku metody pozyskiwania tokenu Authorization Code Flow, ale również w Implicit Flow kod dostępu, jak i token wysyłane są właśnie w adresie URL. Jest to założenie, z którym ciężko walczyć, dlatego trzeba zadbać o odpowiednią higienę związaną z wykorzystaniem tokenów oraz kodów dostępu:
- Kod dostępu powinien być możliwy do wykorzystania tylko raz – niedopuszczalna jest sytuacja, w której na podstawie jednego kodu dostępu możliwe jest wygenerowanie kilku tokenów.
- Token powinien mieć rozsądny, dopasowany do wymogów biznesowych oraz stosowanej polityki bezpieczeństwa czas życia.
- Kodowi dostępu, ze względu na charakter jego wykorzystania, nie powinno się ustawiać wysokiego czasu życia, chyba że jest to jasno i merytorycznie uzasadnione.
- Token lub kod dostępu nie powinien w żadnym wypadku składać się z elementów mogących w prosty sposób zidentyfikować właściciela zasobu lub klienta, na jaki został wystawiony (np. poprzez dodanie nazwy właściciela zasobu na końcu tokenu).
- Zarówno token, jak i kod dostępu powinien mieć odpowiednią długość oraz entropię danych.
- Zaleca się rozważenie możliwości wprowadzenia nie tylko ograniczeń czasowych co do wykorzystania tokenu, ale również limitów ilościowych – ograniczyć ilość zapytań, jakie można wykonać z wykorzystaniem jednego tokenu.
Dopilnowanie, aby token oraz kod dostępu miały odpowiednie ograniczenia czasowe, jest szczególnie ważne ze względu na fakt, że istnieje kilka przypadków, w których mogą one wycieknąć, np. poprzez ujawnienie ich w logach serwera, poprzez podatność Open Redirect lub jako wartość nagłówka Referer.
Consent screen
Implementując własny ekran, na którym prezentowane są właścicielowi zasobu informacje o uprawnieniach, jakie chce uzyskać klient, należy pamiętać o kilku kwestiach:
- Ekran powinien w jasny sposób prezentować, jakie uprawnienia próbuje uzyskać określony klient. Nie należy również na podstawie wymaganych zakresów generować zbyt długich opisów tak, aby nie zniechęcać użytkowników do dokładnego przeczytania przekazanych informacji.
- Należy pamiętać o tym, że jest to zwykła aplikacja WWW lub mały fragment większej całości i operując na danych użytkownika, może być podatna na te same klasy zagrożeń co zwykłe aplikacje (np. XSS lub NoSQL Injection).
- Powinny zostać zaprezentowane podstawowe informacje o kliencie, który chce uzyskać określone uprawnienia (np. jego nazwa).
- Ekran powinien prezentować informacje o tożsamości uwierzytelnionego właściciela zasobów (np. adres e-mail lub login).
Aplikacje mobilne
Osoby fragment artykułu należy poświęcić kwestii aplikacji mobilnych. OAuth jest wykorzystywany w tym środowisku bardzo często, jednak wiążą się z tym liczne problemy. Gdy pojawiło się zapotrzebowanie na implementację procesu związanego z przekierowywaniem właściciela zasobu do odpowiedniego zasobu, jednym z zaproponowanych rozwiązań było wykorzystanie WebView. Należy pamiętać o tym, że – o ile to możliwe – najlepszym rozwiązaniem jest wykorzystanie wbudowanych w daną platformę mechanizmów wspomagających proces generowania tokenu. Jeżeli jednak mimo to wykorzystywany jest mechanizm WebView, warto uwzględnić długą listę problemów, jakie się z nim wiążą.
Cookies
Każda instancja WebView posiada osobny zasobnik na ciasteczka – oznacza to, że jeżeli dwie aplikacje chcą wykorzystać jeden serwer autoryzacyjny, w każdej z nich użytkownik będzie musiał uwierzytelnić się osobno.
Brak izolacji
Wykorzystując WebView, ponownie wracamy do sytuacji, w której nie izolujemy klienta od danych uwierzytelniających użytkownika – w przypadku gdy aplikacji mobilna renderuje dla nas okienko z stroną WWW zawierającą formularz logowania, tak naprawdę nigdy nie możemy być pewni co właściwie ta aplikacja wyświetla. Istnieje ryzyko, że złośliwa aplikacja mobilna wyświetli podstawioną aplikację WWW, której głównym celem będzie kradzież naszych poświadczeń.
Krok w tył
Brak paska adresu – osoby zajmujące się szeroko pojętym bezpieczeństwem IT od kilku lat prowadzą regularną kampanię mającą na celu wpajanie internautom, by przy nawiązywaniu połączenia z serwisami WWW weryfikowali obecność w pasku adresu „kłódki”. Ma to oczywiście na celu wyrobienie nawyku sprawdzania, czy połączenie jest odpowiednio zabezpieczone, a certyfikat serwisu poprawny. WebView takiego paska nie wyświetla i co ważne – nie ma nawet takiej możliwości.
Złe nawyki
Dodatkowo wykorzystanie WebView powoduje, że użytkownicy zmuszani są po podawania swoich danych w różnych miejscach i z czasem przyzwyczajają się do tego, że nie do końca zaufana aplikacja może wyświetlić prośbę o podanie loginu i hasła.
Widać zatem, że wykorzystanie WebView, mimo że wygodne, nastręcza kilka problemów wprost związanych z bezpieczeństwem. Trzeba w takim razie zastanowić się nad innym rozwiązaniem.
Własne URI
Jednym z zalecanych dla aplikacji mobilnych sposobów pozyskiwania tokenu OAuth jest wykorzystanie sposobu opierającego się na rejestracji w systemie własnego URI (ang. Uniform Resource Identifier, Ujednolicony Identyfikator Zasobów), np. myapp://. Jak działa takie rozwiązanie w praktyce? Pierwszym krokiem, tak jak zostało to wspomniane wcześniej, jest zarejestrowanie w systemie własnego URI tak, by był on skojarzony z naszą aplikacją. Następnie z poziomu aplikacji mobilnej inicjuje się standardowy proces pozyskiwania tokenu poprzez wywołanie domyślnej przeglądarki systemowej. Na tym etapie użytkownik przekierowany jest do wybranego serwera autoryzującego w domyślnej przeglądarce systemowej. Po udanym procesie uwierzytelnienia oraz delegowania uprawnień serwer autoryzujący wykonuje przekierowanie pod adres URL zawierający m.in. kod autoryzujący, a który wykorzystuje wcześniej zdefiniowany URI – np. myapp://, dzięki temu, system ponownie wywołuje aplikację mobilną skojarzoną z tym URI, a ta może pobrać wszystkie dane, wykorzystując specyficzne dla danej platformy mechanizmy.
Takie rozwiązanie ma kilka istotnych zalet:
- Nie jest wykorzystywany WebView.
- Cały proces pozyskiwania tokenu odbywa się z wykorzystaniem wbudowanej przeglądarki, domyślnie zaufanej.
- Dzięki wykorzystaniu zwykłej przeglądarki w prosty sposób można zweryfikować, czy połączenie nawiązywane jest do właściwego serwera autoryzującego.
- Jeżeli użytkownik jest już uwierzytelniony w serwerze (np. Google), przeglądarka automatycznie wykona przekierowanie powrotne, bez konieczności ponownego podawania danych uwierzytelniających.
- Istnieje możliwość wykorzystania tych samych metod serwera autoryzującego zarówno do wydawania tokenu dla aplikacji WWW, jak i platform mobilnych.
Co ważne, implementacja takiego rozwiązania nie jest również specjalnie kłopotliwa.
PKCE
Opisany sposób pozyskiwania tokenu na platformach mobilnych z wykorzystaniem rejestracji własnego URI jest ciekawy, jednak by uznać go za bezpieczny, należy wzbogacić cały proces o jeden element – PKCE (Proof Key for Code Exchange). Cały mechanizm opiera się na założeniu, że klient w momencie wysłania pierwszego żądania do serwera autoryzującego (gdy uruchamia wbudowaną przeglądarkę WWW) dodatkowo w zapytaniu prześle parametr code_verifier. Jego zastosowanie jest niemal bliźniacze do omawianego wcześniej parametru state, częściej wykorzystywanego w przypadku aplikacji WWW. Zadaniem serwera autoryzacyjnego jest przechować wartość tego parametru, a gdy klient wróci do niego z wystawionym kodem dostępu, dodatkowo wymusić przesłanie code_verifier. Jeżeli przesłany kod będzie zgodny z tym wysłanym w pierwszym żądaniu, oznacza to, że kod dostępu został odebrany przez właściwego klienta.
Przykładowy przepływ danych został przedstawiony na Rysunku 4:
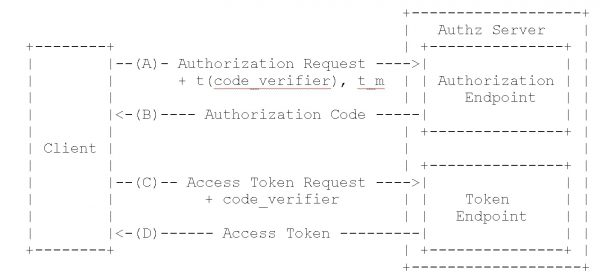
Rysunek 4. Przepływ danych z wykorzystaniem mechanizmu PKCE (źródło).
Wykorzystanie takiego mechanizmu zabezpiecza aplikację np. przed sytuacją, w której w jakiś sposób kod dostępu zostanie przekazany niewłaściwemu klientowi.
Alternatywa dla WebViews oraz Custom URI
Ciekawą alternatywą dla WebViews wydaje się mechanizm Custom Tabs. Rozwiązanie to jest warte uwagi, ponieważ ma niedostępne w WebViews funkcje:
- Współdzielony schowek plików Cookie.
- Możliwość wyświetlania paska adresu.
Aplikacje natywne
Opisane zalecenia dla aplikacji mobilnych można z powodzeniem zaimplementować również w przypadku aplikacji natywnych uruchamianych w systemach Windows, Linux czy macOS.
Różnice w stosunku do OAuth 1.0 oraz kontrowersje
Wersja 2.0 standardu OAuth posiada lepsze wsparcie dla innych sposobów pozyskiwania tokenu niż klasyczne aplikacje WWW, niemniej została pozbawiona wszystkich mechanizmów związanych z kryptografią oraz sygnaturami przesyłanych danych, w pełni przenosząc ten ciężar na wykorzystanie szyfrowanego kanału komunikacji.
W sieci można znaleźć również sporo informacji o tym, że wykorzystanie OAuth nastręcza niemałych problemów. Co ważne, z dalszego rozwoju standardu wycofał się jego pierwotny opiekun Eran Hammer, a żeby podkreślić swoje rozżalenie, poprosił nawet o usunięcie swojego nazwiska z wszystkich oficjalnych dokumentów dotyczących OAuth 2.0.
Modelowanie zagrożeń
Poniżej zawarta została lista pytań, które powinny paść przy okazji przeprowadzania modelowania zagrożeń systemu wykorzystującego OAuth 2.0:
- Czy OAuth wykorzystywany jest jedynie do autoryzacji czy również do uwierzytelniania?
- Która wersja standardu OAuth jest wykorzystywana?
- Czy w przypadku migracji z OAuth 1.0 do OAuth 2.0 uwzględniono różnice związane m.in. z brakiem szyfrowania oraz sygnatur w wersji 2.0?
- Czy do wymiany danych wykorzystywany jest szyfrowany kanał komunikacji?
- Czy wykorzystywane są mechanizmy, tj. HSTS, mające na celu hardening szyfrowanego kanału komunikacji?
- Czy serwer autoryzujący ma zabezpieczenia przed atakami słownikowymi?
- Czy serwer autoryzujący ma odpowiednio przygotowany consent screen prezentujący użytkownikowi wszystkie najważniejsze informacji?
- Czy serwer autoryzujący wymusza ograniczenie czasu życia tokenu?
- Czy serwer autoryzujący waliduje poprawność parametrów przekazywanych podczas pozyskiwaniu tokenu (np. redirect_uri, state)
- Czy serwer autoryzujący ma odpowiednią politykę dotyczącą walidowania wartości parametru redirect_uri tak, by nie było możliwe podanie całej domeny?
- Czy serwer autoryzujący wymusza przekazanie parametru state zabezpieczającego przed atakami CSRF?
- Czy parametry przekazywane przez klienta do serwera autoryzującego przechodzą proces sanityzacji przed odesłaniem do klienta?
- Czy serwer autoryzujący ma wsparcie dla odpowiedniej ilości zakresów (ang. scope) odpowiadającej złożoności zasobów, jakie są chronione?
- Czy serwer autoryzujący udostępnia metodę pozwalającą na unieważnienie tokenu?
- Czy serwer autoryzujący generuje nowy token w przypadku wykorzystania mechanizmu pozwalającego na generowanie nowych tokenów (ang. refresh token)
- Czy serwer autoryzujący przechowuje tokeny w postaci jawnej?
- Czy serwer autoryzujący udostępnia właścicielom zasobów formularz pozwalający na zarządzanie wydanymi zgodami na autoryzację do zasobów?
- Czy serwer autoryzujący ma odpowiednią redundancję oraz zabezpieczenia przed atakami DoS/DDoS
- Czy serwer autoryzujący przeszedł testy bezpieczeństwa (pen-test)?
- Czy dostawca rozwiązania OAuth ma wpływ na to, w jaki sposób klienci przechowują poświadczenia? Czy dokumentacja wykorzystywanego rozwiązania ma odpowiednie rekomendacje?
- Jaki mechanizm wykorzystywany jest przez klientów do przechowywania tokenu?
- Czy token oraz kod dostępu mają odpowiednio krótki czas życia dostosowany do wymogów biznesowych?
- Jaki sposób pozyskiwania tokenu wykorzystuje aplikacja mobilna? Czy wykorzystywany jest mechanizm WebViews?
- Czy i w jaki sposób aplikacja mobilna przechowuje poświadczenia klienta OAuth?
Podsumowanie
Dla osób mających wcześniej doświadczenie z wersją 1.0 standardu OAuth przejście do wersji 2.0 może być szokiem. O ile rozbudowane zostały kwestie umożliwiające wygodne zastosowanie tego standardu w różnych scenariuszach biznesowych, o tyle w oczy rzuca się pozbycie się wbudowanych w standard mechanizmów kryptograficznych. Jednym z kluczowych elementów przy implementacji standardu wydaje się wybór odpowiedniego sposobu pozyskiwania tokenu, a liczne niedomówienia w oficjalnej dokumentacji powodują, że trzeba niezwykle ostrożnie podchodzić do kwestii związanych z bezpieczeństwem OAuth 2.0.
— Marcin Piosek, analityk bezpieczeństwa IT, realizuje audyty bezpieczeństwa oraz testy penetracyjne w firmie Securitum.

Wielkie dzięki za tak obszerny artykuł!
<3 Sekurak
Świetny artykuł
No to jeszcze WS-* i SAML2.0 – będzie kompletne kompendium :)
Ja bym jeszcze bardzo chętnie przeczytał o JWT (json web token) ;)
Pozdrawiam
Ogólnie to mamy duuużo tekstów już gotowych i w kolejce do publikacji. I może w przyszłości i na te tematy przyjdzie czas :]
Z chęcią bym poczytał taki artykuł o SAML 2.0
A ja tak może brzydko że tak powiem się podepnę pod temat, bo akurat niedawno miałem problemy z OAuth na Google i sam nie wiem o co chodzi ani admini strony która tego używa nie wiedzą. Czy ktoś obeznany mógłby się zaznajomić z dyskusja i wypowiedzieć? https://github.com/OpenUserJs/OpenUserJS.org/issues/1052
WhooHoo … bardzo dobry art w tematyce, którą staram się objaśniać od dłuższego czasu :). Kudos.
Dodatkowy Kudos za
(1) “uwierzytelnienie” a nie “autentykacje”
(2) Podkreślenie “OAuth is not authentication protocol”
A ja dorzucę swoje dwa grosze do dyskusji o Oauth i uwierzytelnianiu:
Ok Oauth zapewnia tylko Autoryzacje, ale przecież by uzyskać ta autoryzacje użytkownik musi się uwierzytelnić do serwera autoryzującego. Wiec używanie Oauth do pośredniego uwierzytelniania, na zasadzie dowodu uwierzytelnienia poprzez uzyskanie dostępu do zasobu, ma wciąż sens a i odciąża aplikacje bo nie trzeba implementować funkcji uwierzytelniających i zarządzających hasłem/nickiem/zmiany hasla/przypomnienie hasla itp. no bo skoro użytkownik jest uwierzytelniony do np facebooka to możemy powiązać jego konto facebookowe z naszym poprzez sprawdzenie dostępu do zasobu dostępnego dla uwierzytelnionego użytkownika facebook. Wiec co jest złego w używaniu Oauth do pośredniego uwierzytelniania użytkownika ? (chyba że czegoś nie zrozumiałem w tekście:) )
Złe w tym podejściu jest właśnie wykorzystanie tokena OAuth jako poświadczenia tożsamości właściciela zasobu. OAuth służy do delegacji uprawnień – inaczej mówiąc, Ty, właściciel zasobu, delegujesz uprawnienia do wybranego klienta, który w twoim imieniu wykonuje określone operacje.
czegoś mi brakuje w tym artykule. wykonywany jest pierwszy GET
w którym podany jest identyfikator klienta, ok, ale skąd serwer autoryzacyjny wie o jakiego użytkownika pytamy? czasami jak użytkownik jest już zalogowany to taki serwer nie wyświetla formularza do wprowadzenia nazwy użytkownika i hasła. w zapytaniu get nie wysyłana jest informacja o użytkownika.
Zawsze chodzi o tego użytkownika, który jest zalogowany. W ten sposób właśnie łączy się konto w tym serwisie klienta z serwisem-serwerem. Ew. klient może sprawdzić czy dane użytkownika pobrane przez oauth zgadzają się z już zapisanymi, ale trzeba z tym uważać, bo większość danych może się zmienić i np. Google nie zaleca używania maila jako id.
Może pytanie trochę niezwiązane z tematem ale jak zabezpieczyć np. publiczne API? Mam na myśli sytuację, w której użytkownik np. wysyła coś POSTem przez front do servera, jak uniemożliwić dostęp do tego API z poziomu innych stron (zakładam że CORS)? ale jak uniemożliwić dostęp z poziomu curl?
Bardzo ciekawy artykuł. Od niedawna /koniec maja 2022r./ Goggle w kliencie pocztowym pośrednio zaczął wymuszać używanie OAuth. Zatem fachowo przedstawiona teoria na ten temat bardzo się przyda. Dziękuję.
Super artykuł! Bardzo rozjaśnił temat Analitykowi Biznesowo- Systemowemu :)
Super artykuł, dzięki!
Jedna mała uwaga:
“Klienci, czyli zewnętrzne aplikacje, nie mają styczności z danymi uwierzytelniającymi użytkowników”
Polecam zamienić “Klienci” na “Klienty”, bo to nie ludzie tylko aplikacje.
https://rjp.pan.pl/porady-jezykowe-main/676-klienci-agenci-czy-klienty-agenty
Mały błąd: Kolejnym krokiem jest sprawdzenie, czy właściciel zasobu, w imieniu którego wykonywany jest cały ten proces, jest już uwierzytelniony w serwerze autoryzacji. Jeżeli tak nie jest, w przeglądarce wyświetlany jest tzw. consent screen (Rysunek 1).
—
Jeśli tak nie jest, to jest wyświetlane logowanie. Jeśli właściciel jest zalogowany to wtedy pojawia consent screen.
Aplikacja backendowa udostępniająca usługi autoryzowane tokenem oAuth. Wymóg: klient (strona www) dostępna publicznie bez autoryzacji wywołująca jedną z autoryzowanych metod. Jak zautoryzować tego klienta – jakieś przechowywanie tokenu po stronie serwera www ?
świetny artykuł, bardzo wyczerpujący
W sekcji PKCE opis jest nieco lakoniczny i nie przystaje do rysunku.
W żądaniu A klient wysyła hash parametru code_verifier + algorytm hashujący. W żądaniu C tylko parametr code_verifier. Serwer autoryzujący po otrzymaniu żądania C samodzielnie liczy hash code_verifier zgodnie z algorytmem przekazanym w żądaniu A i porównuje wyliczony hash z tym przekazanym w żądaniu A.
Jeśli obie wartości się zgadzają, to żądania przychodzą od właściwego klienta.