NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!
NIS2/KSC2 starter pack. Czy Twoja firma podlega pod regulację i co z tego wynika? Bezpłatne szkolenie od sekuraka
Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

To trzecia – i ostatnia – część serii artykułów dotyczących podatności deserializacji niezaufanych danych w języku Java. W części pierwszej sprawdzaliśmy, czy problem ten w ogóle występuje w Javie; opisywaliśmy sposób tworzenia łańcucha gadżetów koniecznego do exploitacji, aby ostatecznie zademonstrować atak na przykładową aplikację. W części drugiej, rozważyliśmy kilka mniej typowych łańcuchów gadżetów, a także zastanawialiśmy się, czy użycie formatów XML lub JSON – zamiast natywnego, binarnego do serializacji – jest rozwiązaniem naszych problemów. W niniejszej części odpowiemy na najważniejsze pytanie – w jaki sposób zabezpieczyć tworzoną aplikację przed tego typu atakami.
Przypominam, że kod źródłowy użyty w niniejszym artykule (za wyjątkiem kodu klas z JRE i bibliotek) jest publicznie dostępny
Dotychczasowa lektura artykułów z niniejszej serii, prawdopodobnie ucieszy pentestera (tyle nowych możliwości exploitacji!), ale programistę raczej przygnębi (tyle nowych możliwości exploitacji…). Rzeczywiście, może się wydawać, że używając serializacji w jakiejkolwiek postaci, jesteśmy skazani na porażkę. Wektorów ataku nie brakuje, a podatność jest bardzo różnorodna – nie zależy ani od formatu, ani od mechanizmu. Dodatkowo, programista który zechciałby poszukać rozwiązania problemu, może w szybkim czasie się załamać (albo przynajmniej lekko zirytować). W tym miejscu przypomnijmy (przytaczany w części pierwszej) artykuł Steve’a Breene (@breenmachine), pracownika FoxGlove Security. Jak wspomniałem, dzięki publikacji jego artykułu, podatności deserializacji w Javie nabrały rozgłosu, a badania ich dotyczące, mocno przyspieszyły (stąd ich częste określenie: “Seriapalooza”). Artykuł tego typu nie byłby kompletny, gdyby nie przedstawiał metod obrony przed prezentowanym atakiem – oddajmy więc głos panu Breene:
(…) The Fix – Kind of…
(…) The first thing you can try is the following:
root@us-l-breens:/opt/apache-tomcat-8.0.28# grep -Rl InvokerTransformer .
./webapps/ROOT/WEB-INF/lib/commons-collections-3.2.1.jar
This identifies any jar or class files that contain the vulnerable library. If you’re particularly brave, you can simply delete all of the associated files and hope for the best. I’d suggest very thorough testing after this procedure.
For those faint of heart, you can be a little more surgical about it. If we examine the two exploits provided by the “ysoserial” tool, we can see that they both rely on the “InvokerTransformer” class. If we remove this class file everywhere it exists, any attempted exploits should fail. Feel free to open up your jar files with your expired copy of Winzip and delete the file at “org/apache/commons/collections/functors/InvokerTransformer.class”. (…)
Czyli:
Znajdź wszystkie pliki JAR zawierające klasę InvokerTransformer – przykładowo za pomocą narzędzia grep,
Usuń wszystkie znalezione w punkcie 1 pliki…
… lub (wersja bezpieczniejsza) – zmodyfikuj pliki JAR, usuwając z nich podatną klasę InvokerTransformer (jest to stosunkowo proste, gdyż pliki JAR to zasadniczo odpowiednio skonstruowane archiwa ZIP, zawierające w środku skompilowane klasy Javowe .class).
OK, w tym momencie, każda osoba która jest (lub była) programistą Javy (tudzież – generalnie developerem, który ma jakiekolwiek pojęcie o Javie), przeciera oczy ze zdumienia. Życzę też powodzenia osobom odpowiedzialnym za bezpieczeństwo, których zadaniem będzie przedstawienie powyższego “rozwiązania” zespołowi odpowiedzialnemu za tworzenie oprogramowania – nie spotka się ono bynajmniej z dobrym przyjęciem. Zresztą, autor artykułu (@breenmachine), doskonale zdaje sobie z tego sprawę! Oddajmy mu głos jeszcze raz:
(…) You can infuriate your developers and ops people by telling them to follow the instructions in “The Fix” section to remediate this in your environment. It will fix it, but it’s an admittedly ugly solution. (…)
Sam autor podkreśla, że “rozwiązanie” jest paskudne, z punktu widzenia wytwarzania oprogramowania. Pół biedy, gdyby przynajmniej ono działało, ale czy jest to prawdą? Pierwszy problem, który od razu nasuwa się do głowy to aktualizacje – jak zapewnić że aktualizacja biblioteki zostanie odpowiednio zmodyfikowana? Jest jeszcze gorzej – wbrew temu, co twierdzi @breenmachine (“it will fix it”), powyższe “rozwiązanie” nie naprawia problemu z deserializacją niezaufanych danych – jedyne co zostaje naprawione, to problem wykorzystania w celu exploitacji tej podatności, jednego łańcucha gadżetów (tu: oryginalny łańcuch od @frohoff & @gebl – tzw. CommonsCollections1 z narzędzia ysoserial)!
Ten problem bynajmniej nie jest teoretyczny. Jako przykład, można przytoczyć niedawno znaleziony błąd w (mniej znanej) aplikacji PowerFolder Server (więcej informacji – Exploit Database). Przytoczmy fragment opisu:
(…) The tested PowerFolder version contains a modified version of the Java library “ApacheCommons”. In this version, the PowerFolder developers removed certain dangerous classes like org.apache.commons.collections.functors.InvokerTransformer, however, exploitation is still possible using another gadget chain. (…)
A zatem, programiści zastosowali się do proponowanego “rozwiązania”, a i tak okazało się że aplikacja jest podatna, gdyż nie usunęli wszystkich gadżetów…
Nie da się jednak ukryć, że jakiekolwiek rozwiązanie jest nam koniecznie potrzebne. Statystyczny programista – jak każdy normalny człowiek – chciałby, aby było ono proste w implementacji, działało zawsze i dla wszystkich możliwych wektorów ataku – tak zwana srebrna kula (ang. silver bullet) zabijająca wszystkie potwory… ekhm, podatności. Niestety, jak się okazuje, rozwiązanie tego typu nie istnieje.
W dalszej części artykułu rozważymy niektóre z proponowanych w różnych źródłach możliwości. Żadna z nich nie jest rozwiązaniem idealnym – każda ma swoje plusy i minusy.
To “rozwiązanie” (po raz kolejny używam cudzysłowu) jest oczywiście tutaj tylko dla żartów. “Ukrywanie”, czy “obfuskacja” naszych obiektów Javowych, to nic innego niż Security by obscurity, i nikt chyba nie ma złudzeń że nie będzie działać na dłuższą metę.
Żarty – żartami; fakt, że tego typu propozycje wciąż się pojawiają, nie jest jednak śmieszny – na przykład, często można spotkać się z rozważaniami typu – “Przecież to tylko ciąg losowych bajtów… skąd atakujący będzie wiedział że to zserializowany obiekt Javowy?” lub “To może zaszyfrujemy (sic!) to w base64, wtedy już nikt się nie domyśli?”. Należy mocno i stanowczo przeciwstawiać się takim “rozwiązaniom”, które oferują minimalne zwiększenie bezpieczeństwa.
Korzystając z okazji, przypomnę pro-tip, przydatny szczególnie dla pentesterów: zserializowany obiekt Javowy zawsze będzie zaczynał się od bajtów AC ED 00 05, a ten sam obiekt, dodatkowo zakodowany base64, zacznie się od znaków rO0. Jak widać, wykrywanie takich obiektów przesyłanych w sieci, wcale nie jest takie trudne jak się niektórym wydaje :-)
Jeszcze raz należy podkreślić, że obfuskacja jako rozwiązanie, jest wspomniane w tym artykule jako antywzorzec postępowania oraz przestroga – pod żadnym pozorem nie należy go stosować.
Obfuskacja – plusy:
Rozwiązanie skuteczne przeciwko napastnikom opierającym się całkowicie na zautomatyzowanych skryptach, bez praktycznie żadnej wiedzy technicznej (Script Kiddies) – a i to nie zawsze.
Obfuskacja – minusy:
Nie oferuje żadnej ochrony przed atakującym o przynajmniej minimalnym pojęciu o błędach deserializacji w Javie – a właściwie – bezpieczeństwie w ogólności.
Przejdźmy zatem do pierwszego rozwiązania, które (przynajmniej czasami) może się sprawdzić. Przypomnijmy sobie, że w artykule pierwszym, sformułowaliśmy pięć koniecznych warunków na udaną exploitację. Zaburzając choćby jeden z nich, powstrzymamy potencjalny atak.
Punkty 1-3 są zależne całkowicie od twórców języka Java i maszyny JVM. Aby zaburzyć któryś z nich, musielibyśmy usunąć serializację z Javy całkowicie. Na szczęście, rozwiązanie tego typu zostało już zaproponowane: JEP (Java Enhancement Proposal) 154: Remove Serialization proponuje dokładnie to, o co nam chodzi!
Niestety, nasz dobry humor szybko skończy szybki rzut oka na datę zgłoszenia dokumentu – 01.04.2012. Jest jasne, że dokument ten był jedynie primaaprilisowym żartem. Usunięcie serializacji z Javy jest niemożliwe, choćby z powodu wstecznej kompatybilności. Z tego samego powodu, nie należy liczyć na duże zmiany w sposobie działania tej funkcjonalności. Punkty 1-3 pozostają więc poza naszą możliwością modyfikacji.
W porządku, zostają nam zatem punkty 4 i 5 z naszej listy, na które mamy wpływ. Punktem 4 zajmiemy się dalej, a na razie rozważmy punkt numer 5:
Konkretny program musi umożliwiać odebranie i deserializację obiektu od użytkownika.
Proste wymaganie – i proste rozwiązanie – wystarczy nie używać serializacji! Rzeczywiście – brak serializacji eliminuje nam podatność, w taki sam sposób, w jaki brak używania bazy danych SQL, eliminuje podatność SQL Injection. Oczywiście, sprawa nie jest taka piękna w praktyce – rozwiązanie to ma pewne konsekwencje. Co, jeżeli aplikacja już korzysta z serializacji? Każdy programista wie, jak trudno jest dokonać zmian takiego kalibru w aplikacji – szczególnie, gdy aplikacja jest duża. Dodatkowo – co, jeżeli aplikacja musi korzystać z serializacji? W drugiej części artykułu wspomniałem, jest możliwe (bez straty ogólności) założenie, że używanie jakiejś formy serializacji, jest bezwzględnym wymogiem w zdecydowanej większości aplikacji. Zakładając nawet, że mamy czas i środki żeby serializację “wyplewić” (albo – jeszcze jej nie używamy), możemy być postawieni przed koniecznością jej używania teraz, lub w przyszłości. I w końcu, co jeżeli aplikacja korzysta z bibliotek/frameworków/narzędzi, które używają serializacji? We wspomnianym już artykule @breenmachine, prezentowane luki występują w szeroko używanych narzędziach. Co z tego, że nasza aplikacja jest super bezpieczna (czyli – nie używa w ogóle serializacji), jeśli równocześnie używamy Jenkinsa do Continous Integration, lub serwera JBoss w którym przypadkiem skonfigurowaliśmy JMX jako dostępne z internetu? Oczywiście, wyżej wspomniane podatności są nienowe i załatane (a przynajmniej powinny być!), ale szansa powtórzenia się historii, jest bardzo duża. Świetnym przykładem na to, jest łatanie Jenkinsa w listopadzie, po odnalezieniu problemów z serializacją natywną (o czym wspominam w części pierwszej niniejszej serii), po to, żeby łatać go ponownie w lutym, w związku z odnalezieniem luk w serializacji XStream (co opisane jest w części drugiej niniejszej serii). Problemy mogą wystąpić zarówno Jenkinsie, który jest osobną aplikacją, w serwerze JBoss, na którym uruchomiona jest nasza aplikacja, a także w dowolnej bibliotece czy frameworku których nasza aplikacja używa…
Podsumowując – mimo, że metoda całkowitego pozbycia się serializacji jest skuteczna – jej praktyczne zastosowanie pozostawia wiele do życzenia.
Eliminacja serializacji – plusy:
Całkowicie naprawia problemy z deserializacją niezaufanych danych, w stworzonym kodzie.
Eliminacja serializacji – minusy:
Metoda niepraktyczna do zastosowania w dużych aplikacjach, wymagających sporych zmian w kodzie,
Metoda często niemożliwa w wykorzystaniu – serializacja może być (z niemałym prawdopodobieństwem) wymogiem biznesowym,
Nie zabezpiecza całego produktu – biblioteki, frameworki i inne narzędzia mogą być nadal podatne.
W porządku, spróbujmy lekko rozluźnić nasze podejście: rezygnujemy z serializacji natywnej i będziemy używać tylko, i wyłącznie zewnętrznych bibliotek.
Pierwszy problem z tym rozwiązaniem, jest oczywisty – jak zostało pokazane w części drugiej tej serii – sama rezygnacja z serializacji natywnej, nie oznacza automatycznie, że jesteśmy bezpieczni. W ostatnim czasie – dla przypomnienia – znajdowane były problemy w bibliotekach XStream i Kryo.
Nie należy jednak pochopnie wnioskować, że całe rozwiązanie jest mało wartościowe – zakładając, że znajdziemy bibliotekę, która tego typu problemów nie ma, jest to całkiem sensowny sposób obrony. Przykładem takiej biblioteki, jest Jackson – osobiście, nie jestem świadom istnienia podatności deserializacji w tym produkcie (jeśli Czytelnik ma przykłady na to że jest inaczej, zapraszam do komentowania – chętnie się o tym dowiem!). Należy jednak zaznaczyć fakt, że pomimo, iż Jackson nie posiada znanych podatności dziś, nie oznacza oczywiście, że nie będzie posiadał ich jutro…
Eliminacja serializacji natywnej – plusy:
Przy założeniu, że alternatywna metoda jest odporna na błędy deserializacji – całkowicie eliminuje problem z deserializacją w stworzonym kodzie.
Eliminacja serializacji natywnej – minusy:
W momencie odkrycia podatności – wracamy do punktu zero…
W dalszym ciągu wszystkie niezależne od nas komponenty (biblioteki, frameworki, narzędzia) mogą być podatne – w końcu nie muszą one stosować naszego bezpiecznego rozwiązania…
Narzucamy sobie konkretną technologię (może wolelibyśmy wykorzystać XStream oraz jego wspaniały i prosty w użyciu API?)
W rozwiązaniu numer 1, staraliśmy się uniemożliwić zaistnienie warunku nr 5 z naszej listy założeń koniecznych do exploitacji. Jak wspomniałem, jest jeszcze drugi warunek, na który możemy mieć wpływ – warunek numer 4:
Musimy znaleźć odpowiednie klasy obiektów, które posiadają wyżej wspomniane metody i robią w nich coś “interesującego”. Co więcej, klasy te muszą być “dostępne” (…).
Innymi słowy, warunek numer 4 wymaga istnienia gadżetów. Być może – zamiast walki z samą serializacją – powalczymy z gadżetami… ale jak? Otóż, jest kilka sposobów – zarówno od strony koncepcyjnej, jak i od strony użycia konkretnych narzędzi. Poniżej, przedstawione zostały najpierw dwie metody podejścia do problemu, a następnie, dwa konkretne przykłady projektów, które można w tym celu wykorzystać: SerialKiller i NotSoSerial. Od razu też dodam, że te konkretne projekty odnoszą się do serializacji natywnej, jako że nie posiada ona żadnej wbudowanej możliwości blokowania deserializacji niebezpiecznych klas. Serializacja z użyciem dodatkowych bibliotek, będzie wymagała wsparcia mechanizmów obecnych w tychże bibliotekach.
Pierwsza sprawa, nad którą musimy się zastanowić, to jakiego podejścia użyjemy do blokowania gadżetów. Podobnie jak w innych problemach walidacyjnych, mamy do czynienia z dwiema możliwościami: czarna lista (ang. blacklisting) czyli blokowanie danych wejściowych, o których wiemy, że są niebezpieczne (ang. known-bad), lub biała lista (ang. whitelisting), czyli blokowanie wszystkiego – poza danymi, o których wiemy, że są bezpieczne (ang. known-good). Nie ma potrzeby rozpisywanie zasad działania, gdyż koncepcja powinna być znana Czytelnikowi – wspomnę o pewnych specyficznych aspektach w kontekście problemów deserializacji. W artykule drugim, opisując problemy w bibliotece XStream, wspomniałem, że jej twórcy zdecydowali się na rozwiązanie w postaci gry w Gadget Whack-A-Mole. Whack-A-Mole jest typem gry, gdzie mamy pewną ilość otworów na planszy, z których – co chwila (losowo) – wynurza się tytułowy kret. Zadaniem gracza, jest jak najszybsze uderzenie kreta młotkiem, co powoduje, iż kret chowa się… aby za chwilę wyskoczyć z innego otworu! W naszym przypadku, porównanie powinno być oczywiste – nasz “kret” to gadżet, a uderzenie młotkiem – usunięcie możliwości jego wykorzystania w exploitacji. Niestety, jak w oryginalnej grze, usunięcie pojedynczego gadżetu z reguły kończy się pojawieniem innego…
Oczywiście, nie trudno zauważyć że Gadget Whack-A-Mole, to nic innego jak blacklisting gadżetów – usuwamy (zabraniamy użycia) te, o których wiemy, że są niebezpieczne.
Jako przykład z życia wzięty, odwołam się do wstępu niniejszego artykułu – rozwiązanie zaproponowane przez @breenmachine, jest niczym innym jak blacklistingiem – w końcu usuwamy z plików JAR to, o czym wiem, że może zostać użyte w ataku (konkretnie – klasa InvokerTransformer). I – jak również wspominałem we wstępie -klasyczne obejście tego rozwiązania, rzeczywiście występuje w praktyce (PowerFolder Server). Gadget Whack-A-Mole w praktyce.
Negatywne konsekwencje stosowania czarnych list są raczej jasne. Nie jest tajemnicą, że podejście białej listy jest zawsze preferowane w kontekście bezpieczeństwa aplikacji. Niekiedy jest ono traktowane jak remedium – niestety, nie w przypadku deserializacji.
Rozważmy dwa przykłady z części drugiej tej serii – ataki typu DoS za pomocą zbiorów (HashSet), lub tablic. Na pierwszy rzut oka, obie klasy wydają się całkowicie “niewinne” – wiemy jednak, że nie jest tak we wszystkich przypadkach. Ponieważ są to standardowe, bardzo często używane klasy natywne języka Java, szansa uwzględnienia ich na naszych białych listach, jest bardzo duża… Co więcej, nietrudno sobie wyobrazić sytuację, że klasy te, będą musiały być na białej liście, aby aplikacja działała!
Widzimy zatem, że oba rozwiązania koncepcyjne, same w sobie niosą pewne problemy, bez względu na ich konkretną implementację. W szczególności, plusy i minusy obu projektów opisanych poniżej (SerialKiller i NotSoSerial), są nadzbiorem plusów i minusów rozwiązań koncepcyjnych.
Blacklisting – plusy:
Małe konsekwencje po użyciu (blokujemy mało klas, a więc co najwyżej niewielka część aplikacji będzie dotknięta),
Pozwala zablokować znane wektory ataku.
Blacklisting – minusy:
Rozwiązanie działa tylko do odkrycia nowego łańcucha gadżetów.
Whitelisting – plusy:
Blokuje prawie wszystkie (czasami – wszystkie) wektory ataku.
Whitelisting – minusy:
Może spowodować błędy w istniejącej aplikacji, wymaga pewnego zachodu przy początkowym tworzeniu listy,
Utrudnia dalszy rozwój kodu (trzeba zawsze pamiętać o dodawaniu nowych klas do listy),
Pewne specyficzne ataki mogą zostać przeprowadzone mimo białej listy.
W porządku, wiemy już jak podejść do blokowania gadżetów – czas na praktykę. Na pierwszy ogień pójdzie biblioteka SerialKiller.
Zastanówmy się – dlaczego w ogóle potrzebujemy specjalnych narzędzi do blokowania gadżetów? Otóż, problem leży w sposobie, w jaki Java deserializuje obiekty. Najpierw, tworzone są konkretne instancje, a dopiero potem sprawdzane jest, czy instancje te są odpowiedniego (oczekiwanego) typu. To podejście umożliwia nasze ataki. Byłoby idealnie, gdybyśmy mogli przeprowadzić ten proces na odwrót, to znaczy – najpierw sprawdzić typ obiektu, a dopiero potem – jeśli typ się zgadza (a przynajmniej jeśli wiemy, że nie jest niebezpieczny) – zdeserializować go. To podejście, zwane deserializacją z patrzeniem wprzód (ang. look-ahead deserialization), zostało wykorzystane w projekcie SerialKiller.
Biblioteka implementuje subklasę klasy ObjectInputStream, dzięki czemu, konieczne zmiany w aplikacji są niewielkie. Minusem jest fakt, że musimy pamiętać o używaniu klasy SerialKiller, zamiast ObjectInputStream. Zobaczmy, jak wyglądałby nasz kod z części pierwszej tej serii, po niezbędnych zmianach (zmienione linie zostały pogrubione):
@WebServlet(
name = "Servlet",
urlPatterns = {"/"}
)
public class Servlet extends HttpServlet {
private final String SERIAL_KILLER_CONFIG_PATH = "src/main/resources/serialkiller.xml";
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
Cookie[] cookies = request.getCookies();
Data data = null;
if (null != cookies) {
for (Cookie cookie : cookies) {
if (cookie.getName().equals("data")) {
try {
byte[] serialized = Base64.decodeBase64(cookie.getValue());
ByteArrayInputStream bais = new ByteArrayInputStream(serialized);
ObjectInputStream ois = new SerialKiller(bais, SERIAL_KILLER_CONFIG_PATH);
data = (Data) ois.readObject();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (ConfigurationException e) {
e.printStackTrace();
}
}
}
}
if (null == data) {
data = new Data("Anonymous");
}
request.setAttribute("name", data.getName());
request.getRequestDispatcher("page.jsp").forward(request, response);
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
if (null != request.getParameter("name")) {
Data data = new Data(request.getParameter("name"));
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(data);
Cookie cookie = new Cookie("data", Base64.encodeBase64String(baos.toByteArray()));
response.addCookie(cookie);
}
response.sendRedirect("/");
}
}
Jak widać, jedyne zmiany to użycie klasy SerialKiller w linii 21, zamiast ObjectInputStream i zdefiniowanie ścieżki do pliku konfiguracyjnego w linii 6.
Biblioteka SerialKiller składa się zasadniczo z jednej klasy – również SerialKiller. Jako, że nie występuje ona w publicznych repozytoriach Mavena, w przykładowym projekcie (dla uproszczenia), klasa ta została po prostu skopiowana do projektu.
Aby SerialKiller był cokolwiek wart, należy oczywiście odpowiednio zdefiniować jego plik konfiguracyjny. Rzeczywiście, rozważmy następujący plik:
<?xml version="1.0" encoding="UTF-8"?>
<config>
<refresh>6000</refresh>
<blacklist>
</blacklist>
<whitelist>
<regexp>.*</regexp>
</whitelist>
</config>
To znaczy: czarna lista jest pusta, a wyrażenie regularne na białej liście, pasuje do wszystkiego (czyli, pozwalamy na deserializację dowolnych klas). Po ustawieniu naszego ciastka na payload z pierwszej części, zobaczymy znajomy widok:
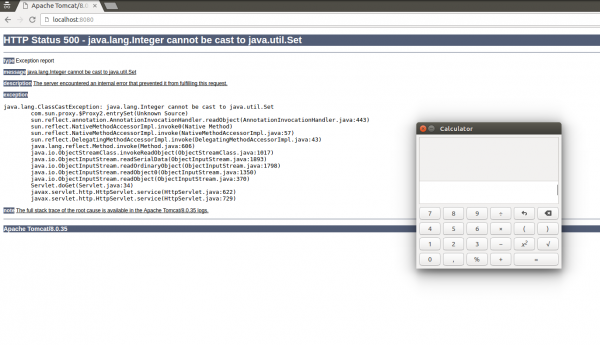
Rys 1. Wykonanie payloadu
Zatem, deserializacja działa bez zmian i nasz payload się wykonuje.
Aby temu zapobiec, umieśćmy używany przez nas gadżet (InvokerTransformer) na czarnej liście:
<?xml version="1.0" encoding="UTF-8"?>
<config>
<refresh>6000</refresh>
<blacklist>
<regexp>org\.apache\.commons\.collections\.functors\.InvokerTransformer$</regexp>
</blacklist>
<whitelist>
<regexp>.*</regexp>
</whitelist>
</config>
Przeładowując stronę, tym razem zobaczymy widok, który się różni od poprzedniego:
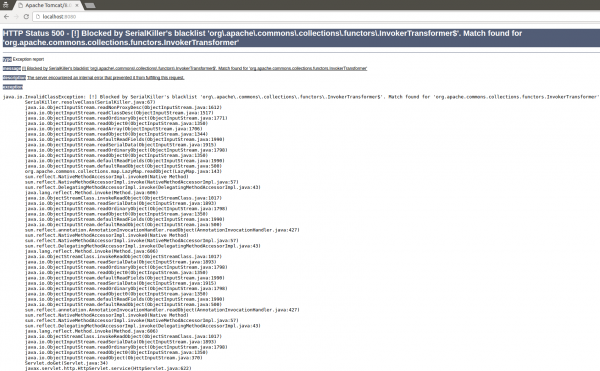
Rys. 2 Blokada payloadu – wykorzystanie czarnej listy
Wyjątek jest inny (i dość wyraźnie wskazuje na przyczynę), a co najważniejsze – ani śladu naszego kalkulatora. Jak widać, biblioteka skutecznie zablokowała nasz payload.
Dodatkowym plusem jest fakt, że SerialKiller wspiera dynamiczne odświeżanie konfiguracji (z konfigurowalnym interwałem – w przykładzie – 6 sekund). Możemy więc szybko reagować na nowe gadżety, modyfikując jedynie plik konfiguracyjny – niepotrzebny jest redeployment, czy nawet – restart serwera.
SerialKiller – plusy:
Metoda dość łatwa w użyciu, wymagająca stosunkowo niewielkich zmian w kodzie,
Możliwość konfiguracji w trybie blacklisting i whitelisting,
W zależności od konfiguracji, może oferować pełne zabezpieczenie przed atakami deserializacji w stworzonym kodzie,
Umożliwia odświeżanie reguł blokowania bez restartu i redeploymentu serwera.
SerialKiller – minusy:
Nie eliminuje problemów dla fragmentów kodu niezależnych od programisty – z bibliotek, frameworków, narzędzi itp.,
Wymaga modyfikacji w kodzie – w przypadku decyzji o rezygnacji z biblioteki (na przykład gdy chcemy zmienić rozwiązanie), musimy po raz kolejny przeglądać cały nasz projekt i poprawiać fragmenty, w których dokonujemy deserializacji,
Nie wymusza bezpieczniej deserializacji – niedoświadczony, nieświadomy lub leniwy programista, nadal może użyć standardowego ObjectInputStream,
Działa tylko dla natywnej serializacji,
W przypadku złej konfiguracji, nadal umożliwia pewne ataki,
Jak wspomina dokumentacja, biblioteka może nie być gotowa do użycia na środowisku produkcyjnym – rzeczywiście, problematyczny jest chociażby brak zależności mavenowej.
Podejście biblioteki SerialKiller jest ciekawe, jednak ma pewne (wcale nie takie małe…) minusy. Czy jest możliwe, abyśmy znaleźli coś podobnego, co przy okazji, wymagałoby minimalnych zmian w aktualnym kodzie i działało automatycznie? Biblioteka NotSoSerial stara się zaoferować takie rozwiązanie.
Istota działania jest właściwie bez zmian – różni się mechanizm. Zamiast dziedziczenia klasy ObjectInputStream użyjemy pakietu java.lang.instrument, który umożliwia nam tworzenie tak zwanych Java Agents – klas, które pozwalają instrumentować wykonywany kod. W tym momencie, powinniśmy zaprezentować kod naszej aplikacji, ale dzięki takiemu, a nie innemu rozwiązaniu, jest on dokładnie taki sam, jak kod z części pierwszej tej serii. Jedyna zmiana, to dodanie naszego agenta do argumentów JVM, przy starcie naszego serwera. Jako, że przykład używa serwera Tomcat Embedded, sprowadza się to do jednej, dodatkowej linii (numer 5 – pogrubiona) w pliku pom.xml:
(...)
<configuration>
<assembleDirectory>target</assembleDirectory>
<extraJvmArguments>-javaagent:<lokacja pliku notsoserial.jar></extraJvmArguments>
<programs>
<program>
<mainClass>Main</mainClass>
<name>webapp</name>
</program>
</programs>
</configuration>
(...)
Agent NotSoSerial domyślnie ma załadowaną konfigurację, składającą się z części znanych, niebezpiecznych gadżetów, których deserializację blokuje. Dlatego, po uruchomieniu serwera z naszą zmianą i po wykonaniu próby podania naszego standardowego payloadu, otrzymamy następujący wynik:
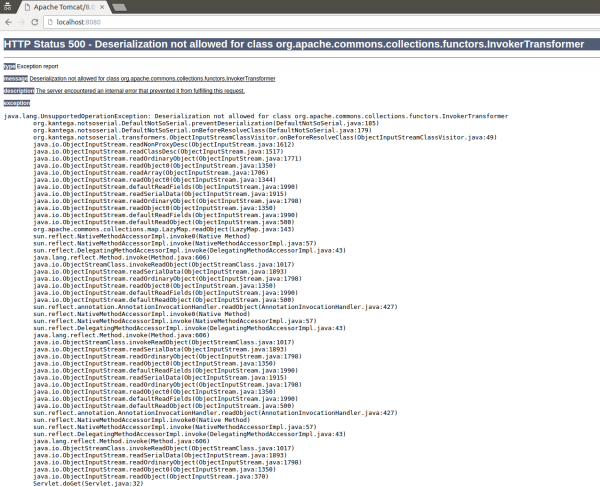
Rys 3. Próba wykonania payloadu po modyfikacji z NotSoSerial
Oczywiście, tak jak w poprzednim przykładzie, nasze rozwiązanie będzie silne na tyle, na ile dokładnie skonfigurujemy nasze czarne i/lub białe listy. W ramach próby, załóżmy, że jesteśmy maniakami, którzy nie chcą żadnej deserializacji w systemie. Aby to zrobić, przygotowujemy białą listę, która będzie po prostu pustym plikiem tekstowym. Następnie, dodajemy ją do konfiguracji – dzieje się to przez ustawienie kolejnego parametru JVM w linii 5 (pogrubione):
(...)
<configuration>
<assembleDirectory>target</assembleDirectory>
<extraJvmArguments>-javaagent:<lokacja pliku notsoserial.jar>-Dnotsoserial.whitelist=<lokalizacja
listy></extraJvmArguments>
<programs>
<program>
<mainClass>Main</mainClass>
<name>webapp</name>
</program>
</programs>
</configuration>
(...)
Po przebudowaniu i restarcie serwera, próba normalnego użycia aplikacji skończy się oczywiście niepowodzeniem:
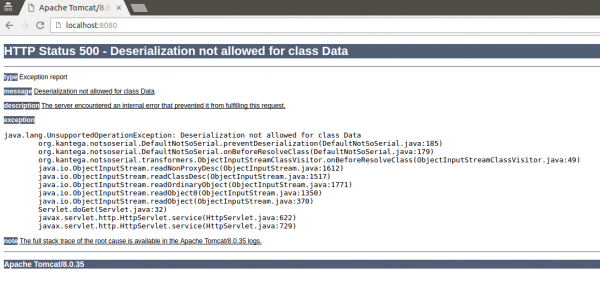
Rys. 4. Użycie aplikacji po zmianie konfiguracji
Jest jasne że chcielibyśmy tego uniknąć. W naszym prostym przykładzie, dobrze wiemy, które klasy są wymagane do działania programu. Niekoniecznie jednak musi być to prawdą w przypadku dużej aplikacji, szczególnie, gdy serializacja jest używana przez zewnętrzne biblioteki, a nie przez nasz kod. NotSoSerial udostępnia bardzo ciekawą funkcjonalność, która może nam pomóc: uruchomienie testowe (ang. dry run). Włączamy je kolejnym argumentem JVM (pogrubiona linia 5. poniższego kodu ):
(...)
<configuration>
<assembleDirectory>target</assembleDirectory>
<strong> <extraJvmArguments>-javaagent:<lokacja pliku notsoserial.jar> -Dnotsoserial.whitelist=<lokalizacja
listy> -Dnotsoserial.dryrun=<lokalizacja wyjściowego raportu></extraJvmArguments></strong>
<programs>
<program>
<mainClass>Main</mainClass>
<name>webapp</name>
</program>
</programs>
</configuration>
(...)
Po kolejnym przeładowaniu aplikacji, poklikajmy po niej trochę – wygląda na to, że wszystko działa. Zaglądając natomiast do pliku wyjściowego, znajdziemy tam wszystkie klasy, które zostały zdeserializowane – w naszym przypadku będzie to jedna linia – Data, gdyż niczego innego nie używamy. Możemy następnie użyć tego pliku, jako naszej białej listy.
Jak widać, projekt NotSoSerial udostępnia sporo ciekawych opcji i jest bardzo przyjazny w użyciu.
NotSoSerial – plusy:
Działa transparentnie i automatycznie dla każdej operacji deserializacji (także w bibliotekach i frameworkach),
Nie wymaga praktycznie żadnych modyfikacji w projekcie,
Użycie bezpiecznej serializacji jest wymuszone na programiście (bez narzutu na pisanie kodu!),
Posiada zarówno tryb blacklisting, jak i whitelisting,
W zależności od konfiguracji, może oferować pełne zabezpieczenie przed atakami deserializacji,
Posiada tryb dry-run, który umożliwia stworzenie początkowej białej listy.
NotSoSerial – minusy:
Działa tylko dla natywnej serializacji,
W przypadku złej konfiguracji, nadal nie chroni przed pewnymi atakami.
Wróćmy raz jeszcze do punktu 5 z naszej listy wymogów dla skutecznego wykorzystania podatności deserializacji:
Konkretny program musi umożliwiać odebranie i deserializację obiektu od użytkownika
Powyższe zdanie nie mówi o tym wprost, ale kryje w sobie pewne założenie: nasz “obiekt od użytkownika”, jest tym, który użytkownik mógł dowolnie zmodyfikować. Rzeczywiście, jeśli użytkownik będzie nam wysyłał tylko obiekty stworzone oryginalnie przez serwer, a zakładamy przecież, że serwer jest zaufany (w przeciwnym wypadku – czemu w ogóle chcemy go bronić?), jest jasne, że nigdy nie zdeserializujemy niebezpiecznych danych. To daje nam ciekawą opcję obrony – gdybyśmy uniemożliwili użytkownikowi modyfikację danych, bylibyśmy się w stanie obronić przed atakiem!
Brzmi to pięknie, ale w rzeczywistości, nie jesteśmy w stanie (w żaden sposób) uniemożliwić użytkownikowi modyfikacji danych, które fizycznie posiada… OK, spróbujmy trochę osłabić założenie: użytkownik może modyfikować dane, ale serwer jest w stanie wykryć każdą (nawet najmniejszą!) modyfikację. Jeśli serwer, z góry będzie odrzucał każde żądanie, w którym wykryje oznaki ingerencji, jedynie zdeserializowane obiekty będą tymi, które pierwotnie stworzył sam, a więc z powrotem osiągamy nasz cel.
Czy możemy wykrywać takie modyfikacje? Otóż tak! Na pomoc przychodzi nam kryptografia, a konkretnie – kryptograficzne podpisy: MAC (ang. Message Authentication Code) dla kryptografii symetrycznej, lub podpisy cyfrowe (ang. Digital Signatures), dla kryptografii asymetrycznej.
Jak będzie wyglądało (w zarysie) nasze rozwiązanie? Mianowicie, każda potencjalnie niebezpieczna dana, którą wyślemy do użytkownika (na przykład – ciastko), w trakcie wysyłania będzie miała doklejony kryptograficzny podpis. Gdy owa dana wróci na serwer, zanim zostanie przekazana do przetworzenia (to bardzo istotny fragment rozwiązania!), musi najpierw przejść test poprawności danych w stosunku do podpisu. W przypadku błędu, żądanie jest automatycznie odrzucane, a w przypadku sukcesu – przekazywane dalej i przetwarzane.
UWAGA!
Poprawna implementacja rozwiązań kryptograficznych, jest niezwykle trudna – prawdopodobieństwo popełnienia małego błędu, skutkującego całkowitym brakiem bezpieczeństwa – jest wysokie. Aby dowiedzieć się więcej o kryptografii, polecam lekturę artykułów na Sekuraku, z tagiem kryptografia.
Poniższy kod służy tylko i wyłącznie, jako demonstracja idei.
Zdecydowanie nie jest to rozwiązanie typu “skopiuj-i-wklej” – nie jest przeznaczone do bezpośredniego zastosowania w systemie produkcyjnym, z racji współistnienia wielu, bardzo ważnych problemów do rozwiązania – na przykład, zarządzanie kluczami. Czytelnik został ostrzeżony.
W praktyce, implementacja rozwiązania (po raz kolejny, na przykładzie z pierwszej części tej serii), będzie wyglądała następująco (dodatkowe i zmienione linie są pogrubione):
@WebServlet(
name = "Servlet",
urlPatterns = {"/"}
)
public class Servlet extends HttpServlet {
private static final SecretKeySpec keySpec = new
SecretKeySpec("3BaUHxi9OBp2FtnPipB9OZxehd7O5UDxvJYxdNwSk9I6sXnEbTQJSh5H2Y988VU".getBytes(),
"HmacSHA256");
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
Cookie[] cookies = request.getCookies();
Data data = null;
if (null != cookies) {
for (Cookie cookie : cookies) {
if (cookie.getName().equals("data")) {
try {
byte[] serialized =
Base64.decodeBase64(verifyAndGetCookie(cookie.getValue()));
ByteArrayInputStream bais = new ByteArrayInputStream(serialized);
ObjectInputStream ois = new ObjectInputStream(bais);
data = (Data) ois.readObject();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
}
if (null == data) {
data = new Data("Anonymous");
}
request.setAttribute("name", data.getName());
request.getRequestDispatcher("page.jsp").forward(request, response);
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
if (null != request.getParameter("name")) {
Data data = new Data(request.getParameter("name"));
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(data);
Cookie cookie = new Cookie("data",
signCookie(Base64.encodeBase64String(baos.toByteArray())));
response.addCookie(cookie);
}
response.sendRedirect("/");
}
private String verifyAndGetCookie(String cookie) throws ServletException {
String [] parts = cookie.split("\\.");
if (parts.length != 2) {
throw new ServletException("Malformed cookie!");
}
try {
String b64value = parts[0];
String b64mac = parts[1];
Mac mac = Mac.getInstance("HmacSHA256");
mac.init(keySpec);
// MessageDigest.isEqual is constant-time in recent Java versions
if (!MessageDigest.isEqual(mac.doFinal(Base64.decodeBase64(b64value)), Base64.decodeBase64(b64mac))) {
throw new ServletException("Malformed cookie!");
}
return b64value;
} catch (NoSuchAlgorithmException e) {
throw new ServletException("MAC algorithm not found");
} catch (InvalidKeyException e) {
throw new ServletException("Bad key spec");
}
}
private String signCookie(String cookie) throws ServletException {
try {
Mac mac = Mac.getInstance("HmacSHA256");
mac.init(keySpec);
String sig = Base64.encodeBase64String(mac.doFinal(Base64.decodeBase64(cookie.getBytes())));
return cookie + '.' + sig;
} catch (NoSuchAlgorithmException e) {
throw new ServletException("MAC algorithm not found");
} catch (InvalidKeyException e) {
throw new ServletException("Bad key spec");
}
}
}
Jak widać, istota programu się nie zmieniła – doszły za to dwie metody, które z pomocą kryptograficznego API dostępnego przez JCA, wykonują dodatkowe operacje na ciastku. Pierwsza z nich, to signCookie() (zdefiniowana w liniach 83-96, a wykorzystana w linii 49.), która jako argument przyjmuje oryginalne ciastko (czyli zserializowany obiekt Javowy), wylicza dla niego MAC (u nas za pomocą algorytmów HMAC i SHA256) i ostatecznie, zwraca oryginalną wartość, z doklejoną sygnaturą.
Druga metoda – verifyAndGetCookie(), definicja w liniach 56-81, użycie w linii 20. – dostaje na wejściu ciastko od użytkownika, które składa się (a przynajmniej powinno się składać, zakładając że użytkownik nie próbował ciastka modyfikować!) ze sklejonego zserializowanego obiektu Javowego i odpowiadającej mu wartości MAC. Wartości te, są ze sobą porównywane i jeśli sobie odpowiadają, program kontynuuje wykonywanie pracy (czyli deserializację obiektu i użycie go). Jeśli wartości się nie zgadzają (to znaczy – zserializowany obiekt z ciastka daje inny MAC niż ten w ciastku), wykonywanie jest natychmiast przerywane, poprzez rzucenie odpowiedniego wyjątku. Ostatnia, istotna zmiana, to zdefiniowanie w linii 7. klucza, którego serwer będzie używał do wyliczania MAC. Nie muszę chyba dodawać, że krytycznym jest, aby klucz ten był kryptograficznie silny…
Czy zadziała to w praktyce? Sprawdźmy. Po uruchomieniu serwera, nie widzimy na pierwszy rzut oka żadnych zmian. Gdy poszukamy jednak dokładniej, zobaczymy, że nasze ciastko faktycznie wygląda inaczej:

Rys. 5. Zastosowanie kryptografii
Pierwsza połowa, to nadal nasz zserializowany obiekt (rozpoznajemy po tym, że zaczyna się od znaków rO0), ale dalej, następuje kropka (która pełni rolę separatora) i zakodowany w base64 – MAC. Dopóki używamy aplikacji w sposób standardowy, wszystko działa jak powinno – co się jednak stanie gdy zmodyfikujemy choć jeden bit w naszym ciastku?
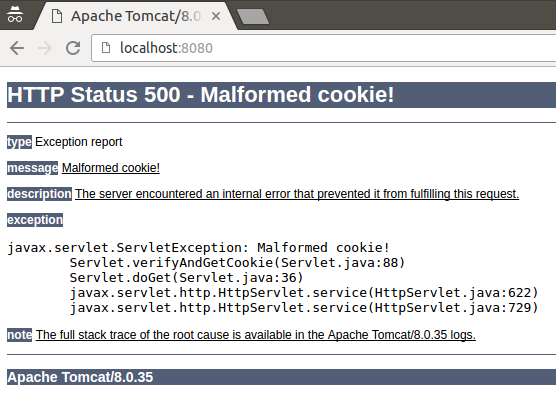
Rys. 6. Komunikat po modyfikacji ciastka
Jak widać, zgodnie z założeniami serwer odrzuca nasze żądanie. Nie nastąpiła także deserializacja, a więc potencjalny atak się nie powiódł.
Na marginesie: przykładowy kod używa kryptografii symetrycznej i MAC, zamiast (dużo szerzej znanych) podpisów cyfrowych kryptografii klucza publicznego. Zasadniczo, z punktu widzenia bezpieczeństwa – nie jest istotne, którą z opcji wybierzemy – jednakże kryptografia symetryczna, jest z założenia szybsza w działaniu, więc uzasadnione jest stosowanie jej, kiedy tylko jest taka możliwość.
W naszym przykładzie – zarówno podpis, jak i weryfikacja – jest wykonywana na serwerze, nie ma więc powodów, aby klucz udostępniać gdziekolwiek, a więc kryptografia symetryczna i technologia MAC, mają dużo większy sens.
Jak można było prześledzić na przykładach, kryptografia skutecznie pomaga nam bronić się przed atakami deserializacji, a nawet więcej – w pośredni sposób – uniemożliwia dowolne modyfikacje danych, uzyskanych od użytkownika.
Kryptografia – plusy:
Prawidłowo zaimplementowana, blokuje wszystkie ataki deserializacji niezaufanych danych (gdyż w pewnym sensie uniemożliwia otrzymanie niezaufanych danych!),
Stosunkowo niewielki narzut na kod programu (wystarczy jedno wspólne miejsce odpowiedzialne za podpisywanie i weryfikację danych),
Działa dla każdej formy serializacji.
Kryptografia – minusy:
W dużej aplikacji, wprowadzenie może być problematyczne – na przykład – w aplikacji, która działa już jakiś czas na produkcji, stare zapisane dane (jak ciastka), zostaną nagle uznane za błędne, gdyż nie są podpisane,
Prawidłowa implementacja metod kryptograficznych, jest niezwykle trudna i łatwo jest popełnić drobny błąd, który sprawi, że całość rozwiązania przestanie być bezpieczna.
Zapobieganie atakom powinno być pierwszym celem każdej osoby, która dba o bezpieczeństwo. Truizmem będzie jednak twierdzenie, że w większości przypadków stworzenie “kuloodpornej” aplikacji, jest właściwie niemożliwe i błędy mogą wystąpić zawsze. W takich przypadkach, nie mniej istotne od zapobiegania, jest szybkie wykrycie i reakcja.
W przypadku błędów deserializacji w Javie, okazuje się że jesteśmy na całkiem niezłej pozycji. Aby monitorować potencjalne ataki deserializacji, możemy zrobić dwie rzeczy.
Jak już kilkakrotnie było to wspomniane, zserializowane (natywnie) obiekty Javowe mają charakterystyczną strukturę, a konkretnie – zaczynają się od specyficznych bajtów (dla przypomnienia – obiekt Javowy rozpoczyna się od bajtów AC ED 00 05 – co po zakodowaniu przez base64 da rO0). W związku z tym, urządzenia sieciowe mogą zostać “nauczone”, aby zgłaszać wszystkie wystąpienia tych sekwencji. Oczywiście, niesie to za sobą pewne problemy – sygnatury są krótkie, więc jest dość duża szansa wystąpienia fałszywych alarmów (ang. false positives). Co więcej, prawdopodobieństwo wykrycia jest z pewnością mniejsze od 100%, gdyż dowolna obfuskacja zserializowanego obiektu, ukryje potencjalne problemy. Dodatkowo, jeśli musimy korzystać z zserializowanych obiektów, analizowanie alertów nieuzasadnionych i tych, które są potencjalnymi atakami, może być utrudnione. Jest też raczej oczywiste, że metoda ta zadziała tylko dla natywnej serializacji.
Mimo minusów, jest to metoda warta rozważenia (a przynajmniej – przetestowania), jeśli nie spodziewamy się żadnych zserializowanych obiektów Javowych w naszej sieci.
Java jest językiem silnie typowanym. W związku z tym, jak można było zaobserwować w przykładach, właściwie każdy atak – nieważne czy udany, czy tylko próba – kończy się wyjątkiem typu ClassCastException. We względnie stabilnej aplikacji (na przykład – na środowisku produkcyjnym), taki wyjątek powinien być niezwykle rzadki, gdyż powodowany jest albo przez duży błąd programisty, albo atakującego. Zatem monitorowanie logów pod kątem tego wyjątku, może nam dość szybko dać informacje o trwającym ataku – a przy odrobinie szczęścia – nawet, zanim atakującemu uda się znaleźć odpowiedni łańcuch gadżetów i z sukcesem wykorzystać błąd.
Jak widać, możliwości obrony przed problemami związanymi z deserializacją niezaufanych danych, jest sporo. Niestety, żadna z nich nie jest pozbawiona wad. Przed zastosowaniem konkretnej metody, zdecydowanie polecam dokładną analizę “za i przeciw” rozpatrywanych rozwiązań.
W mojej osobistej opinii, jeśli tylko czujemy się na siłach, powinniśmy zastanowić się nad zastosowaniem rozwiązania numer 3, czyli kryptografii – dobrze zaimplementowana blokuje właściwie wszystkie ataki. Jeśli z różnych powodów, kryptografia nie wchodzi w grę, a zależy nam na możliwie prostym w implementacji rozwiązaniu, proponuję użycie biblioteki NotSoSerial – w tym wypadku należy jednak poświęcić odpowiednią ilość czasu na stworzenie bardzo dokładnej konfiguracji – najlepiej, w trybie białej listy. Bez względu, jakie rozwiązanie wybierzemy, warto rozważyć też (zgodnie z paradygmatem Defence in depth) odpowiednie monitorowanie, które może być nieocenioną, ostatnią linią naszej obrony.
Niniejsza seria jest wierzchołkiem góry lodowej, jeśli chodzi o problemy deserializacji w ogólności. Jak wielokrotnie wspominałem, podatności tego typu są niezależne od języka, technologii, formatu i wielu innych rzeczy (nie znaczy to że występują powszechnie – potencjalnie, mogą wystąpić wszędzie). Deserializacja niezaufanych danych, mimo że nie jest spotykana na każdym kroku, prowadzi do poważnych konsekwencji (bardzo często RCE). Jej waga została ostatnio podkreślona i doceniona w ramach pwnie awards – Steve Breen jest nominowany w kategorii “najlepszego” błędu po stronie serwera (ang. Pwnie for Best Server-Side Bug).
Z punktu widzenia programisty, jest to problem – mało kto zdaje sobie sprawę z istnienia tego typu podatności. Bardzo istotne jest więc nagłaśnianie zagadnień serializacji i deserializacji oraz edukacja w tym zakresie. Co więcej, łatanie tego typu błędów, może być bardzo trudne – szczególnie w dużej aplikacji, która już od jakiegoś czasu jest dostępna na środowisku produkcyjnym. Najlepiej więc – już na etapie planowania, projektowania i implementacji aplikacji – mieć pewną wiedzę o konsekwencjach serializacji i deserializacji obiektów.
Z punktu widzenia pentestera lub badacza bezpieczeństwa, problemy tego typu są interesującym polem do szukania błędów. Niska świadomość społeczeństwa deweloperów i fakt, że o możliwościach wykorzystania luk w serializacji i deserializacji, zrobiło się głośno dopiero w ciągu ostatniego roku, są czynnikami, które zwiększają nasze szanse na ciekawe odkrycia. I rzeczywiście, wydaje się, że błędy tego typu są na topie, badania trwają… i pewnie przez jeszcze jakiś czas będziemy o nich słyszeć.
–Mateusz Niezabitowski jest byłym Developerem, który w pewnym momencie stwierdził że tworzenie aplikacji jest fajne, ale psucie ich jeszcze bardziej. Aktualnie pracuje na stanowisku AppSec Engineer w firmie Ocado Technology.

W sumie to problem można streścić w jednym zdaniu: nie należy ufać niczemu co przychodzi do serwera z sieci. Ta zasada została złamana i efekty są łatwe do przewidzenia. Serializację natywną można stosować tylko lokalnie na serwerze. Wszystkie inne dane trzeba weryfikować zanim się z nich zacznie korzystać.
Cześć,
Bardzo ciekawa seria. Myślę że sprawę należy jak najbardziej nagłaśniać. Sam osobiście zastosowałem podejście z kryptografią, testując aplikację pod kątem pokazanych w serii luk, nie stwierdziłem przebić :)
Niestety mój przełożony doszedł do wniosku że nie ma sensu poświęcać czasu na implementację moich rozwiązań: “bo przecież i tak nikt nie sprawdza security”. Ot, społeczność. Myślę że przydałaby się seria ogólna, jeżeli chodzi o np. zabezpieczanie aplikacji pod kątem przyjmowania/przetwarzania samych requestów :-)
Pozdrawiam
Fajna seria artykułów, ale generalnie widać że chodzi tutaj bardziej o takie biblioteki do serializacji (no i natywny) które pozwalają zdefiniować typy obiektów po deserializacji. Zobaczcie, że gdyby Xstream wymuszał podanie typu obiektu, a serializowałby tylko wartości pól, to już prawdopodobnie byłby bezpieczny. Dlatego zapewne Jackson jest bezpieczny – on instancjonuje tylko podany w kodzie (czyli przez deva) obiekt i wypełnia jego pola, nie pozwala nam (chyba że jest taka opcja a o niej nie wiem) podać w zserializowanej wersji nic innego niż wartości pól, a typy kolekcji sam wybiera
“Zobaczcie, że gdyby Xstream wymuszał podanie typu obiektu”
Mam na myśli wymuszał na developerze
Masz 99% racji :-) niestety, poza bezpieczenstwem dochodzi tez wygoda stosowania – z punktu widzenia dewelopera, XStream i jego super proste API jest zdecydowanie kuszace. Nie mowie ze to argument aby stosowac ta biblioteke, ale jest to powod dla ktorego tego typu biblioteki istnieja…
Ten 1% w ktorym racji nie masz, to ze mozna wyobrazic sobie przyklady kiedy oryginalny obiekt sam w sobie daje jakas mozliwosc atakujacemu. Dla przykladu: obiekt User z polem isAdmin (ustawiamy na true i voila), HashSet ktory daje nam mozliwosc DoSa (cz. 2), czy w przypadku bezmyslnosci programisty jakis obiekt ktory sam w sobie wykonuje jakies polecenie systemowe…