Konferencja Mega Sekurak Hacking Party w Krakowie – 26-27 października!

Bezpieczeństwo aplikacji internetowych bazujących na platformie Node.js. Część 1.
Wstęp
Od pewnego czasu obserwujemy bardzo dynamiczny rozwój technologii pozwalających na budowanie aplikacji internetowych jedynie z wykorzystaniem języka JavaScript.
Do najpopularniejszych platform umożliwiających taką pracę należy Node.js – jedna z wersji silnika JavaScript V8 stosowanego przez Google w przeglądarce Google Chrome. Ta stosunkowo nowa technologia narażona jest na zagrożenia wynikające z chorób “wieku dziecięcego”. Niektóre z nich już wyeliminowano, inne zapewne dopiero zostaną odkryte. Z tego powodu ważne jest, by osoby tworzące aplikacje w JavaScript z użyciem Node.js, systemu pakietów npm oraz coraz bogatszego zbioru bibliotek, frameworków i systemów szablonów zdawały sobie sprawę z czyhających na nich zagrożeń.
Także przed osobami na co dzień zajmującymi się bezpieczeństwem aplikacji internetowych Node.js stawia nowe wyzwania, na przykład podczas przeprowadzania testów penetracyjnych takich aplikacji. W listopadzie 2012 roku, na German OWASP Day 2012, w skrócie tę tematykę zaprezentował Sven Vetsch. Zachęcam do zapoznania się z jego prezentacją.
W części pierwszej niniejszego opracowania postaram się omówić kilka kwestii związanych z samym Node.js oraz zagrożenia, jakie wiążą się z jego używaniem.
W części drugiej dokładniej przyjrzymy się m.in. aplikacjom zbudowanym z wykorzystaniem framework Express.js, a także korzystającym z NoSQL-owej bazy danych MongoDB.
Architektura aplikacji zbudowanych z wykorzystaniem platformy Node.js
Na początku parę słów o samej platformie: Node.js to stworzony na początku 2009 roku projekt oparty na silniku JavaScript firmy Google – V8. Umożliwia tworzenie wysoko wydajnych aplikacji jedynie przy użyciu JavaScript. Działanie Node.js opiera się na tzw. pętli zdarzeń. Node pracuje jako jeden wątek, natomiast wszystkie zdarzenia zachodzące w cyklu działania programu (np. aplikacji internetowej) obsługiwane są we wspomnianej kolejce, w kolejności, w jakiej się w niej znajdą, oraz, co najważniejsze, asynchronicznie. Oznacza to, że żadne z obsługiwanych zdarzeń nie blokuje wykonywania pozostałych. Pętla (event loop) odpowiada jedynie za przyjęcie zdarzenia, jego wykonanie i zwrócenie wyniku do działającego wątku Node.
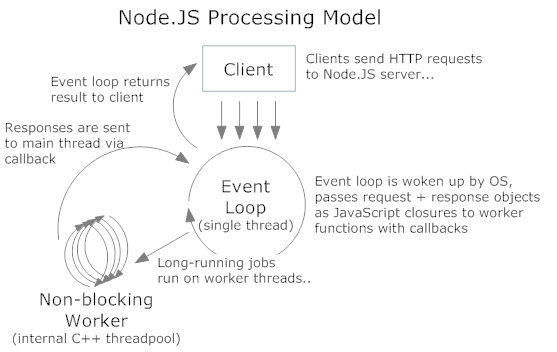
1. Schemat działania pętli zdarzeń w Node.js.
Aby uzyskać taki efekt, aplikacja musi zostać napisana jako sterowana zdarzeniami. Intensywnie wykorzystywana jest tu także koncepcja tzw. callbacków, czyli funkcji zwrotnych. W skrócie: odpowiadają one za kontynuowanie wykonania programu po odebraniu wyników wywołania zdarzenia – jest to tzw. CPS (Continuation-passing style, czyli “kontynuowanie przez przekazanie”). Stąd w większości kodu brak tradycyjnych instrukcji powrotu ‘return’.
Najczęstszym wzorcem, w jakim tworzone są aplikacje Node.js, jest tak zwany SPA, czyli Single-page application. SPA to nic innego, jak aplikacja w całości działająca w ramach jednego okna przeglądarki, w którym nie następuje przeładowanie strony po każdym żądaniu, tak jak się to dzieje w tradycyjnym modelu żądanie-odpowiedź. Komunikacja odbywa się asynchronicznie, a dane przekazywane są pomiędzy klientem (przeglądarką), a serwerem (Node.js) poprzez REST-owe wywołania (REST – Representational state transfer), zwracające dane w formacie JSON (JavaScript Object Notation). Wszystkie zmiany widoczne w oknie przeglądarki wprowadzane są przez manipulację drzewem DOM oraz stylami CSS. W uproszczeniu jest to wręcz podręcznikowy przykład działania technologii określanych akronimem AJAX (Asynchrous JavaScript and XML).
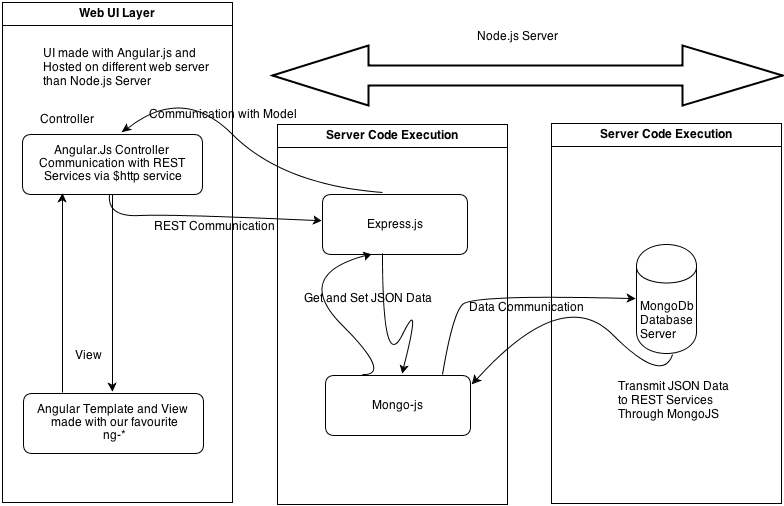
2. Przykładowa architektura aplikacji SPA. Na schemacie widać elementy w postaci frameworka Express.js oraz bazy danych MongoDB po stronie serwera, a także frameworka AngularJS po stronie klienta. Komunikacja odbywa się poprzez komunikaty REST, dane wymieniane są w formacie JSON. Jest to jeden z najpowszechniej spotykanych schematów w aplikacjach SPA zbudowanych na Node.js.
Typowe zagrożenia aplikacji opartych na platformie Node.js
Czas przedstawić zagrożenia, na jakie może natknąć się każdy, kto chce stworzyć aplikację z wykorzystaniem Node.js. Ze względu na charakterystykę działania nie da się dokonać bezpośredniego porównania z innymi serwerami aplikacji webowych, jak choćby Apache czy nginx. Listę otwiera coś, czego nie spotkamy w wymienionych powyżej:
1. Konfiguracja Node.js. A raczej jej brak.
Serwer Node.js nie zawiera żadnej, nawet domyślnej konfiguracji. Tak naprawdę w momencie uruchomienia kodu w JavaScript nie musi to być nawet aplikacja internetowa, może to być dowolny, poprawny składniowo kod napisany w EcmaScript 5 (czyli aktualnie obowiązującej specyfikacji języka JavaScript).
Dopiero po dołączeniu do aplikacji poleceniem require() modułu “http” uzyskujemy coś, co już można nazwać serwerem WWW. Kod najprostszej aplikacji internetowej wygląda tak, jak na poniższym listingu:
// <i>app.js - najprostsza aplikacja webowa w Node.js</i>
var http = require('http'); <i>// dołączenie modułu HTTP</i>
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');
Nie występuje tutaj żadna konfiguracja – kod wykonywany jest “ad hoc”. Po uruchomieniu poleceniem:
$ node app.js
i po wpisaniu w pasku adresu przeglądarki:
http://localhost:1337
na ekranie ukaże nam się strona zawierająca tekst ‘Hello world’. Nie definiujemy żadnego katalogu, na wzór Apache’owego DOCUMENT_ROOT. Nie ma ani jednej zmiennej określającej działanie serwera, czasu przetwarzania żądania, żadnych modułów, jak mod_rewrite czy mod_security w serwerach Apache. Node.js wykonuje kod JavaScript, nie zwracając najmniejszej uwagi na to, co ten kod robi.
Takie działanie stawia programistów w niezwykle niebezpiecznej sytuacji. Już w lipcu 2011 roku na konferencji BlackHat Bryan Sullivan z Adobe wskazywał w swojej prezentacji na możliwość wstrzyknięcia kodu do aplikacji Node.js (Server-Side JavaScript Injection). Tego rodzaju podatności są coraz rzadsze, ale wciąż istnieją i wynikają z budowy i działania platformy.
2. Obsługa błędów (error handling)
Jedną z konsekwencji budowy platformy Node.js jest brak domyślnej obsługi jakichkolwiek błędów. Skutkuje to możliwością wyłączenia serwera przez wywołanie np. nieobsłużonego wyjątku lub błędu skutkującego niepoprawnym działaniem aplikacji. Na poniższych ilustracjach widać przykładowy efekt takiej sytuacji:

3. Formularz na przedstawionym screenie przyjmuje jako argument liczbę. Niestety, w aplikacji brakuje kodu, który obsłużyłby sytuację przesłania danych innych niż liczby…
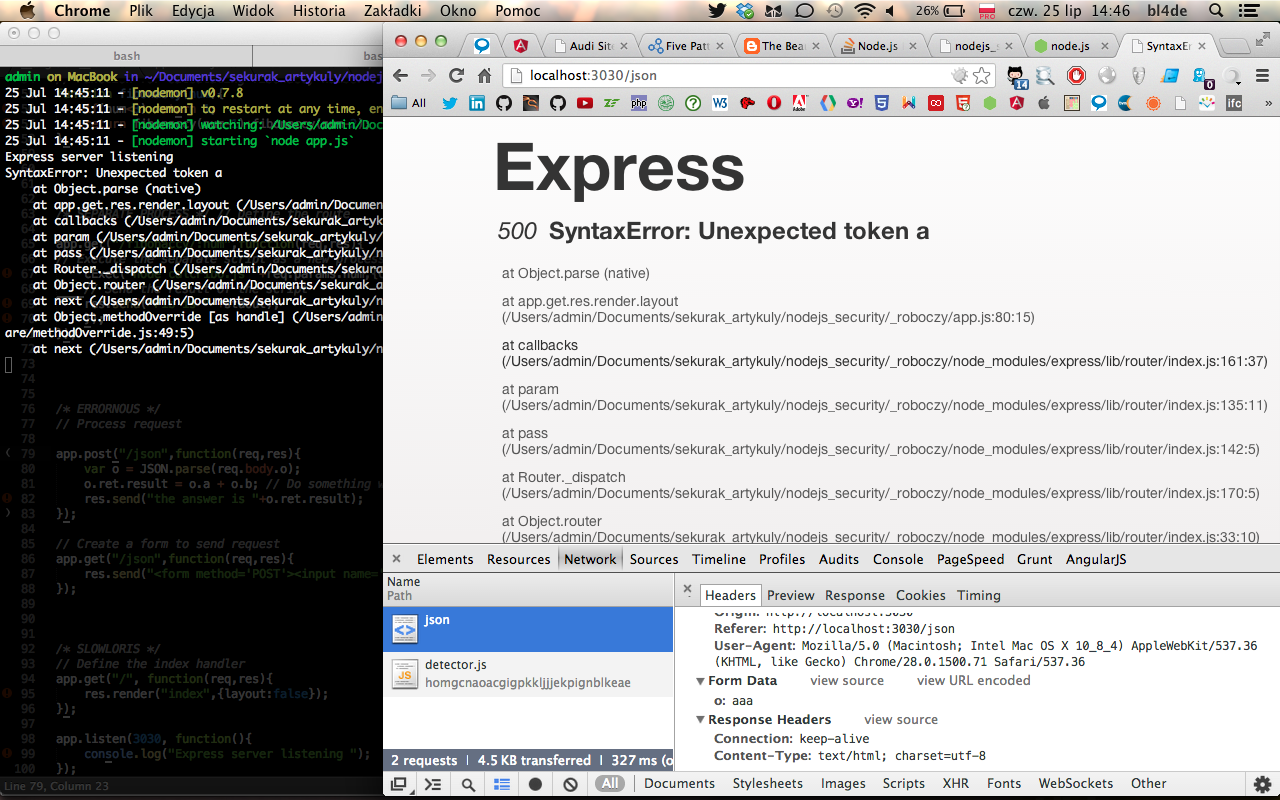
4. … skutkiem czego jest awaria aplikacji.
W przedstawionym przykładzie wykorzystałem framework Express.js, który informuje o błędzie. W innym przypadku użytkownik nie zostałby w żaden sposób poinformowany o zaistniałej sytuacji, a w konsoli pojawiłaby się informacja o nieobsłużonym wyjątku i zakończeniu procesu Node.js.
Ubocznym skutkiem takiego zachowania jest możliwość dokonywania ataków DDoS (Distributed Denial of Service) przez celowe wywoływanie podobnych błędów, co skutkuje zwiększonym czasem odpowiedzi serwera po każdym takim błędzie. We wczesnych wersjach możliwy był także atak DDoS za pomocą odpowiednio spreparowanych żądań, ale zostało to naprawione wraz z wersją 0.6.17 platformy (HTTP Server Security Vulnerability: Please upgrade to 0.6.17 – artykuł na blogu projektu Node).
3. Wykonanie kodu przesłanego w parametrach POST lub GET do funkcji eval()
Jak do tej pory to chyba najbardziej niebezpieczna podatność Node.js.
Dlaczego? Przeanalizujemy na podstawie dwóch praktycznych przykładów, zarówno dla żądania POST, jak i GET.
Przyjrzyjmy się przykładowej aplikacji:
/* CORRUPTABLE */
// Show the form to client
app.get("/sum",function(req,res){
res.send("<form method='POST'>"+
"<input name='first' /><input name='second' />"+
"<input type='submit' value='submit' />");
});
// Process the form
app.post("/sum",function(req,res){
var sum = eval(req.body.first +"+"+req.body.second);
res.send("the answer is "+sum);
});
Jak widać na listingu, wynik obliczany jest przy pomocy wyrażenia parsowanego przez wbudowaną w interpreter JavaScript funkcję eval(). Funkcja eval() wykonuje przekazany jako argument kod w taki sposób, jakby był to fragment aplikacji (opis funkcji eval() w Mozilla Developer Network).
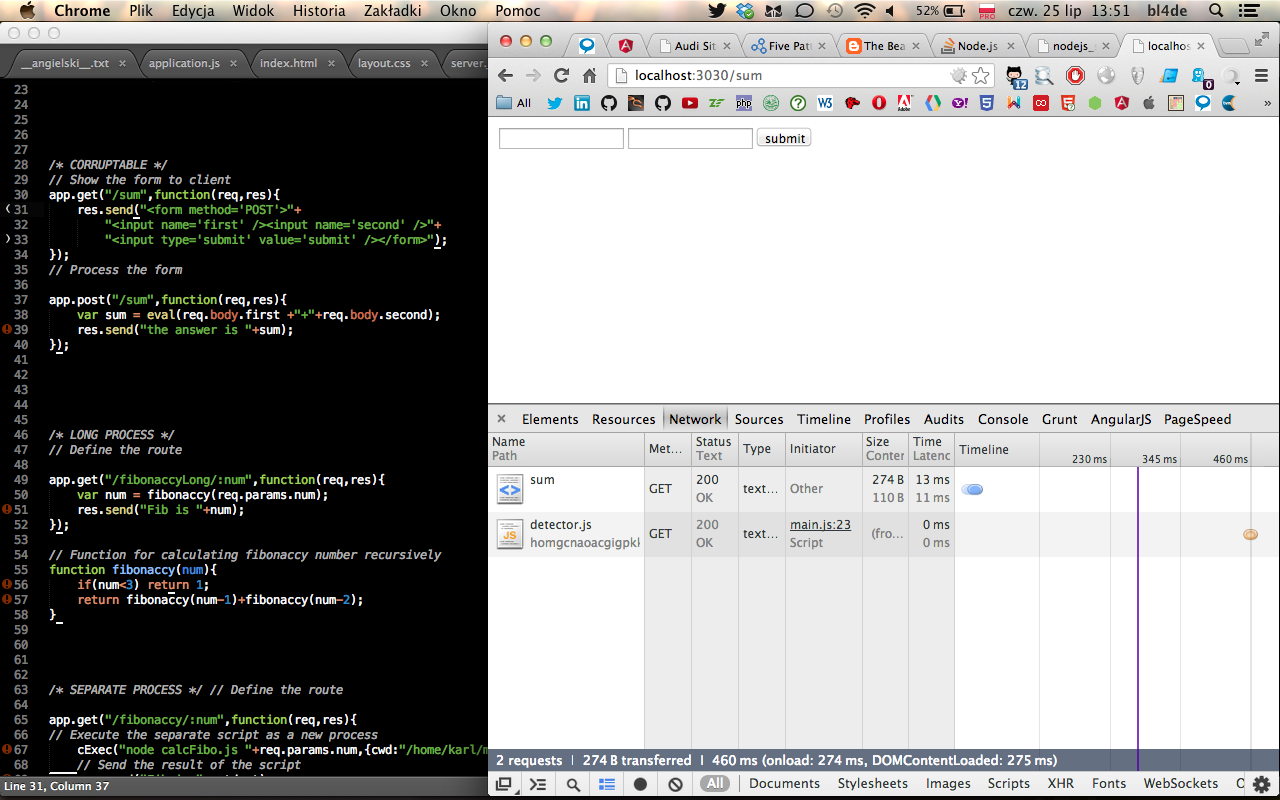
4. Aplikacja dodająca do siebie dwie przesłane z formularza metodą POST liczby.
Aplikacja działa bezbłędnie dla dwóch dowolnych liczb, wyświetlając ich sumę. Co jednak się stanie, gdy w jednym z pól prześlemy taki oto payload:
3; app.get("/hacked", function(req,res) { res.send("Hacked!!!"); });
Powyższy kod wymaga małego wyjaśnienia: po znaku średnika zawiera on definicję metody obiektu app(), która obsługuje (jest callbackiem, czyli funkcją zwrotną) żądanie HTTP GET pod adresem ‘/hacked’. Ponieważ oba argumenty przesłane do aplikacji są parsowane i wykonywane przez funkcję eval(), powyższy kod zostanie wykonany w kontekście uruchomionej aplikacji, czyli w rezultacie aplikacja zostaje rozszerzona o nową funkcjonalność!
Przyjrzyjmy się, jak zachowa się nasz przykładowy formularz:
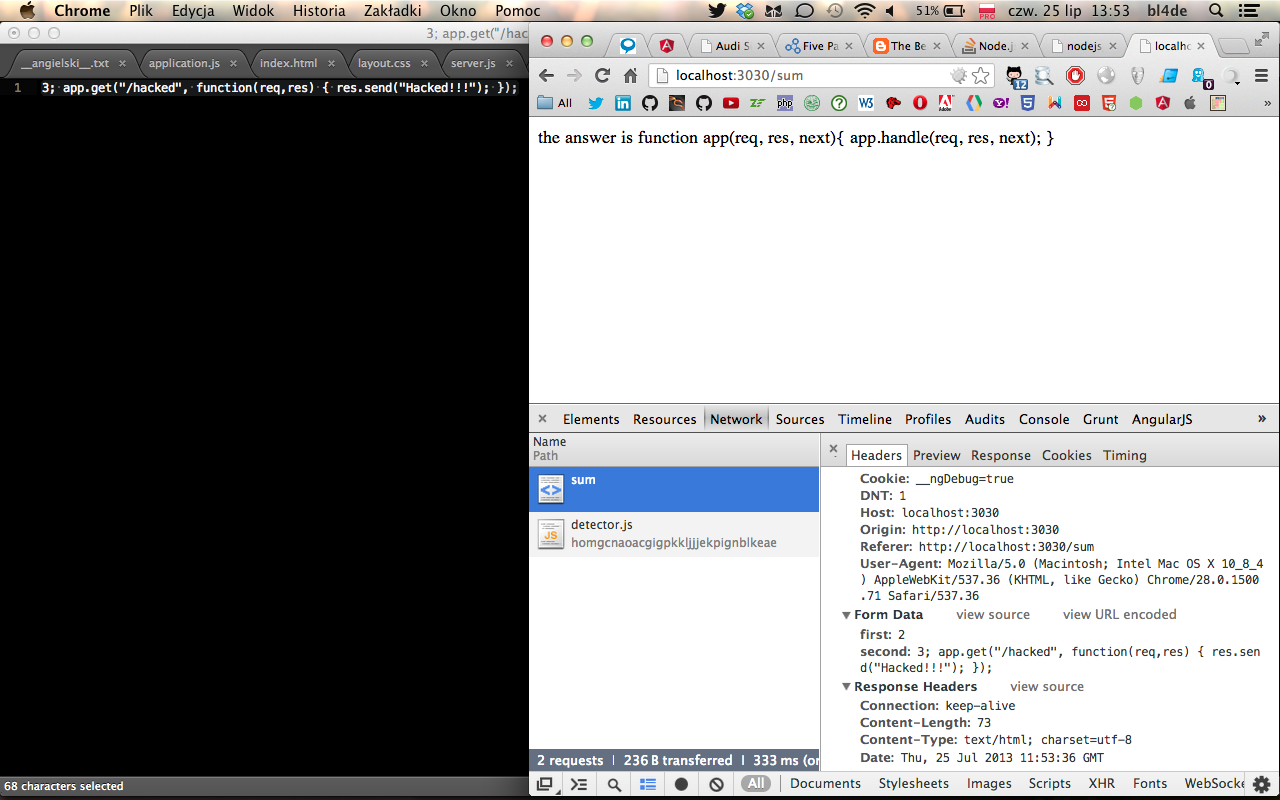
5. Wynik przesłania payloadu przez formularz.
Teoretycznie, poza dość dziwną odpowiedzią, nic się nie wydarzyło. Pozornie. Spróbujmy przejść teraz pod adres ‘/hacked’, ten sam, dla którego payload “dopisał” kod jego obsługi w postaci callbacka:
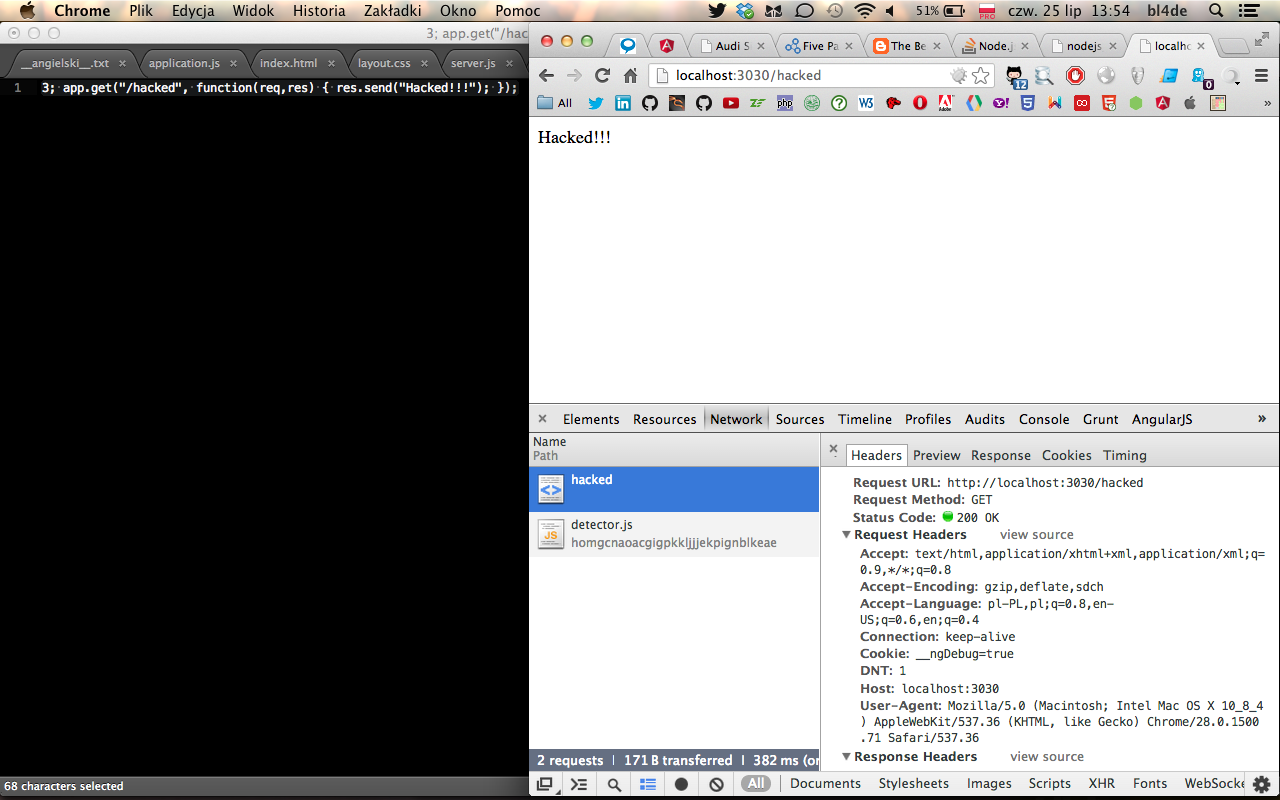
6. Wynik działania kodu, dopisanego przez przesłany jako argument dla eval() callback.
Taki atak jest bardzo niebezpieczny z wielu powodów.
Atakujący jest w stanie “w locie” modyfikować działanie aplikacji (pamiętajmy, że działa ona jako jeden wątek, więc takie zmiany są widoczne dla wszystkich jej użytkowników). Poza tym z uwagi na to, że Node nigdzie nie zapisuje w logach żądań HTTP, oraz że atak ten nie powoduje awarii aplikacji (jeśli oczywiście payload nie zawiera błędów sam w sobie) – atak nie jest w żaden sposób widoczny!
Nie wykaże go także analiza kodu źródłowego, bo po prostu nic w kodzie źródłowym nie zostało dodane. Dopóki wątek Node będzie działał, dopóty zadeklarowany w ten sposób fragment kodu będzie działał. Dokładnie tak samo jak dowolna funkcja JavaScript napisana w konsoli Firebug’a bądź Chrome DevTools zadziała w kontekście otwartej w przeglądarce dowolnej strony WWW, mimo tego, że nie dopisaliśmy ani linijki kodu do skryptów JavaScript samej strony internetowej!
Z punktu widzenia administratora czy osoby odpowiedzialnej za bezpieczeństwo taka sytuacja jest koszmarem. Dodatkowym problemem jest całkowita “odporność” takiego ataku na rodzaj protokołu. Zadziała on niezależnie od tego, czy użyty został HTTP, czy jego bezpieczna wersja HTTPS. Kolejnym problemem jest fakt, że nie ma żadnego znaczenia, z jakimi uprawnieniami działa Node.js.
Przyjrzyjmy się teraz innemu przykładowi, tym razem manipulacji przy parametrach przekazywanych w GET. Poniższy fragment kodu źródłowego zawiera w sobie linijkę wypisującą w konsoli (polecenie console.log()) pewne informacje diagnostyczne, w tym jeden z parametrów odczytany z adresu URL o nazwie ‘log’:
var http = require('http'), url = require("url");
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
var queryData = url.parse(req.url, true).query;
eval("console.log('"+queryData.log+"')");
console.log("injected above");
res.end("Check Your console, bro..");
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');
Sytuacja jest analogiczna jak w poprzednim przypadku: na pierwszy rzut oka nic nie wskazuje na czyhającą pułapkę. Do momentu, gdy przekażemy aplikacji następujący payload:
http://localhost:1337/?log=');%20function%20a()%20{return%2010;};console.log(a());//
Ciąg przekazany jako wartość parametru ‘log’ to kolejno:
- zamknięcie instrukcji z linijki
eval("console.log('"+queryData.log+"')");zaraz za ciągiemqueryData.log+
- prawidłowa składniowo definicja funkcji a(), której jedynym zadaniem jest zwrócenie liczby 10,
- wykonanie tak zdefiniowanej funkcji, jako argumentu dla console.log(), co skutkuje wypisaniem rezultatów wykonania w konsoli,
- zamknięcie ciągu i znak komentarza jednolinijkowego powodujący, że nie wykona się nic, co znajduje się za instrukcją w tej samej linijce.
Spójrzmy na wynik końcowy (proszę zwrócić uwagę na konsolę i wyświetloną liczbę 10 – jest to rezultat wykonania funkcji a(), zadeklarowanej tylko w parametrze ‘log’ w url):
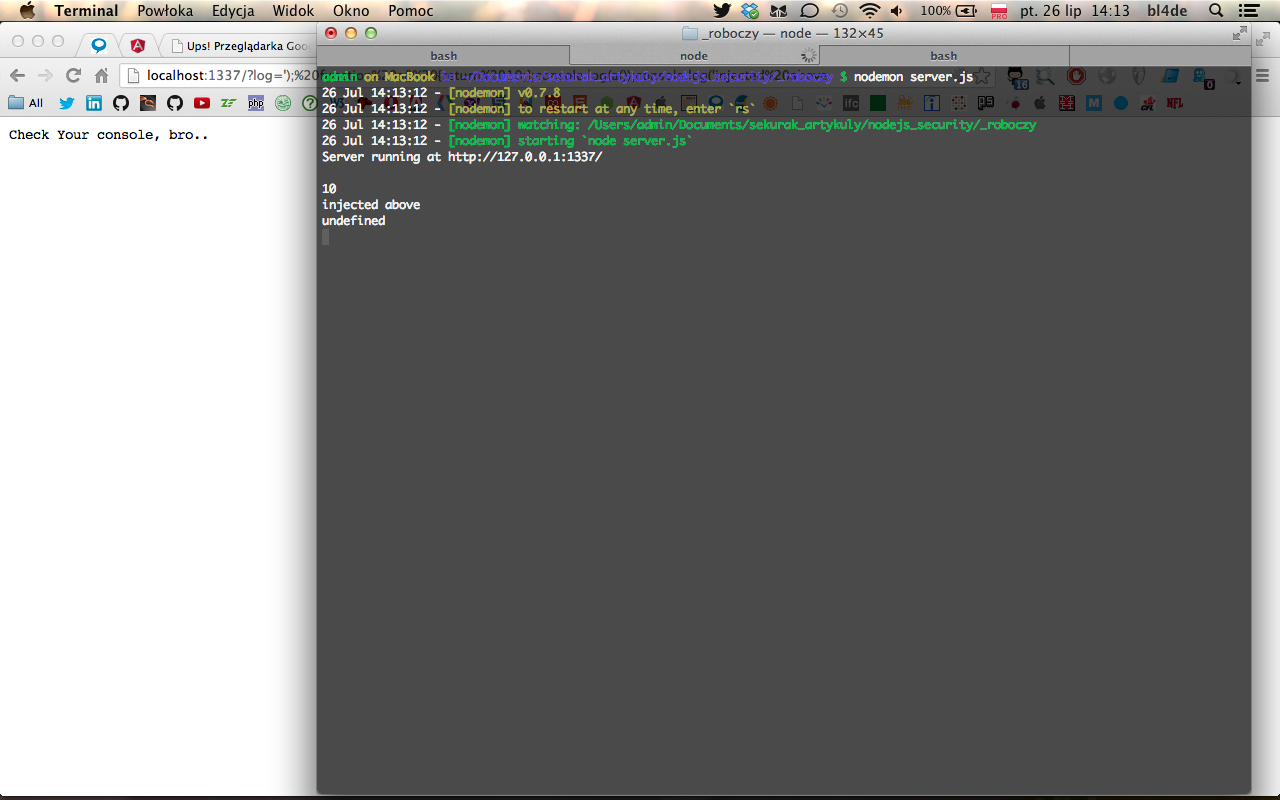
7. Wynik działania payloadu przesłanego w parametrze GET do funkcji eval().
Możliwości, jakie niesie ze sobą ten rodzaj ataku, są praktycznie nieograniczone. Dodatkowo, gdy atakujący natrafi na instancję Node.js działającą z uprawnieniami użytkownika uprzywilejowanego (root), w żaden sposób nie logujący i nie sygnalizujący takich prób serwer jest bezbronny – (pamiętajmy, że musimy we własnym zakresie zadbać o obsługę błędów czy zapis działania serwera do logów) – skutki mogą być dramatyczne.
4. Global Namespace Pollution
Działanie aplikacji na platformie Node oznacza, że każde żądanie, niezależnie od liczby użytkowników, obsługiwane jest tylko przez jeden wątek (kolejne żądania lądują jedynie w event loop, tak, jak to opisałem na początku). Skutkiem tego jest pewna specyficzna podatność, określana jako “Global Namespace Pollution”, czyli “zatrucie” globalnej przestrzeni nazw. Co to oznacza, wytłumaczę na przykładzie.
Poniżej znajduje się kod aplikacji napisanej w języku PHP i uruchomionej na serwerze Apache. Co się stanie ze zmienną $global, gdy adres URL, pod którą się ona znajduje, poda w swoich przeglądarkach kilku użytkowników?
<?php $global = 0; $global = $global + 1; echo "zmienna global ma teraz wartość: " . $global; <i>// zawsze wyświetli 1</i>
Otóż dla każdego z tych żądań, serwer Apache uruchomi oddzielny wątek, a zmienna $global będzie sobie żyła w swojej własnej, niezależnej od innych przestrzeni nazw (czyli każda jej instancja znajdzie się w innym miejscu pamięci RAM maszyny, na której działa Apache). Zawsze, dla każdego kolejnego żądania wartość zmiennej będzie wynosić 1.
Spójrzmy teraz na kod aplikacji w JavaScript. Pozornie mogłoby się wydawać, że rezultat będzie ten sam.
var express = require("express"),
app = express();
var global = 0;
app.get('/', function(req, res) {
global = global + 1;
res.send("zmienna global ma teraz wartość: " + global);
});
app.listen(3333);
Niestety, zmienna global została zadeklarowana w przestrzeni globalnej, tzn. jest dostępna w całym zakresie kodu aplikacji. Ponieważ aplikacja działa na jednym wątku, każde wywołanie adresu URL aplikacji spowoduje inkrementację zmiennej global o 1. Oznacza to, że dla setnego użytkownika aplikacji będzie ona miała już wartość 100!
Jeśli stan aplikacji jest w jakikolwiek sposób zależny od zmiennych znajdujących się w przestrzeni globalnej, to każda zmiana stanu tych zmiennych ma wpływ na każde żądanie, niezależnie, skąd pochodzi. Przykładem na takie działanie może być przypadek z dopisaniem nowego callbacka dla url ‘/hacked’ opisane w punkcie o niebezpieczeństwach funkcji eval(). Teraz zaprezentuję inną sytuację.
Kod na poniższym listingu sprawdza, czy użytkownik chcący skorzystać z określonej części aplikacji jest zalogowany czy nie. Niefortunnie, programista zadeklarował zmienną isLogged w przestrzeni globalnej nazw. Niestety, ma to katastrofalne skutki:
var express = require("express"),
app = express();
var isLogged = false;
app.get('/login', function(req, res) {
// fragment aplikacji sprawdzający uprawnienia
// ...
isLogged = true;
res.send("You're now logged in.");
});
// dostęp do tej części aplikacji wymaga, by user był zalogowany
app.get('/', function(req, res) {
// problemem jest globalna zmienna isLogged:
if (isLogged) {
res.send("Welcome, user. What would You like to do? :D");
} else {
res.send("Acces denied!");
}
})
app.listen(3333);
Prześledźmy krok po kroku, co się wydarzy, gdy do aplikacji zaloguje się użytkownik uprawniony, a zaraz po tym zacznie z niej korzystać ktoś bez uprawnień (nie ma znaczenia, czy zrobi to nieświadomie, czy będzie to celowe działanie). Użytkownikiem uprawnionym jest Ewa, korzystająca z przeglądarki Chrome, natomiast nieuprawnionym Aleks korzystający z Firefoxa.
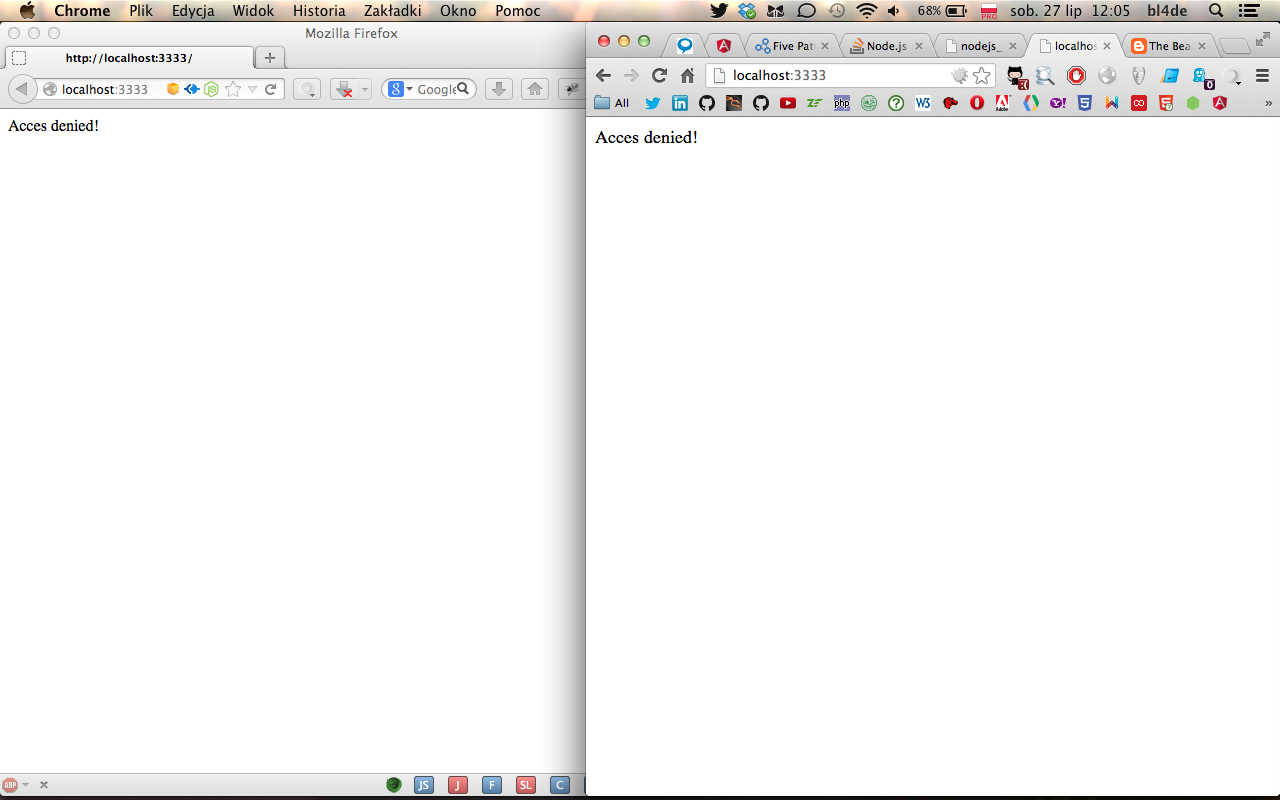
8. Okno przeglądarki Chrome (po prawej) to przeglądarka Ewy, czyli użytkownika uprawnionego, znającej dane dostępowe do aplikacji. Okno po lewej (Firefox) to widok z perspektywy Aleksa, czyli naszego użytkownika nieuprawnionego.
Ewa loguje się do aplikacji, korzystając z nadanych jej przez administratora danych (loginu, hasła, tokenu jednorazowego itp.).

9. Ewa zostaje prawidłowo uwierzytelniona. Zmienna isLogged ma w tym momencie wartość true.
Po chwili na scenie pojawia się Aleks i niczego nieświadomy lub (co oczywiście oznacza dużo gorszy przypadek) doskonale zdający sobie sprawę z tego, co robi, podaje w pasku adresu link do zastrzeżonej części aplikacji, która sprawdza wartość zmiennej isLogged. Zmienna ta, znajdująca się w globalnej przestrzeni nazw, przed chwilą została ustawiona na true, jako efekt prawidłowego logowania Ewy (wyobraźcie sobie taką sytuację w aplikacji PHP uruchomionej na serwerze Apache bądź aplikacji JSP/JSF działającej na dowolnym serwerze aplikacji J2EE – co się wtedy dzieje?).

10. Aleks widzi zawartość, która nie powinna być dla niego dostępna bez uprzedniego zalogowania się.
Oczywiście także Ewa ma dostęp do części zabezpieczonej logowaniem. Niestety, ma ją także każdy, kto zna poprawny adres www tej sekcji.

11. Także Ewa, jako uprawniony użytkownik, widzi część zastrzeżoną serwisu.
Problemy tego rodzaju są specyficzne dla sposobu, w jaki działa Node.js i aplikacje internetowe z niego korzystające. Na szczęście powstaje coraz więcej różnego rodzaju frameworków (jak używany przeze mnie w przykładach Express.js) działających zarówno po stronie serwera, jak i klienta (AngularJS, Ender, Backbone), częściowo eliminujących tego rodzaju problemy. Oczywiście ostateczny efekt zależy od programisty i kodu aplikacji, dlatego na końcu opracowania podałem kilka wskazówek, o których powinien pamiętać każdy, kto ma lub będzie miał styczność zarówno z budowaniem, jak i testowaniem aplikacji dla platformy Node.
5. Systemy szablonów
W aplikacjach budowanych przy użyciu jedynie JavaScript, w tym w aplikacjach SPA (Single Page Application), dość intensywnie wykorzystywane są systemy szablonów. Działają dokładnie na takiej samej zasadzie, jak analogiczne szablony w aplikacjach PHP (Smarty, Twig), ASP czy JSP/JSF. W kodzie HTML umieszczone są specjalne znaczniki, w miejsce których, w trakcie kompilacji albo interpretowania kodu przez serwer, podstawiane są właściwe zmienne przekazane przez skrypt.
Należy pamiętać o tym, że kod aplikacji SPA dla Node składa się tylko i wyłącznie z HTML (po stronie klienta) i JavaScript (po obu stronach). Stąd naturalna podatność tych aplikacji na ataki XSS (Cross Site Scripting, XSS). Dlatego obowiązują tutaj takie same zasady jak w przypadku innych platform – żaden kod nie może zostać przekazany do szablonu, dopóki nie zostanie odpowiednio zneutralizowany przed wyświetleniem go na ekranie. A już na pewno nie kod, który pochodzi od użytkownika.
O samej podatności XSS można znaleźć masę informacji, polecam zapoznać się choćby z opracowaniami na stronie OWASP (https://www.owasp.org/index.php/Cross_Site_Scripting_Flaw, XSS Filter Evasion Cheat Sheet).
6. CVE 2012-2330
Jak do tej pory, w bazie danych CVE National Vulerability Database można znaleźć jeden wpis, dotyczący Node.js:
The Update method in src/node_http_parser.cc in Node.js before 0.6.17 and 0.7 before 0.7.8 does not properly check the length of a string, which allows remote attackers to obtain sensitive information (request header contents) and possibly spoof HTTP headers via a zero length string. http://www.cvedetails.com/vulnerability-list/vendor_id-12113/Nodejs.html.
Nowsze wersje platformy pozbawione są już tej podatności, dlatego zaleca się nieużywania Node.js w wersjach starszych niż 0.8.
Ponieważ Node.js to projekt bazujący na silniku JavaScript firmy Google, wykorzystywany w przeglądarce Google Chrome, pewną wskazówką na co zwrócić uwagę może też być lista podatności dla V8 właśnie. Można ją przejrzeć pod adresem Google » V8 : Security Vulnerabilities, choć podobnie jak dla samego Node.js nie jest to długa lista. :)
Tym z Was, którzy mają ochotę nieco bliżej przyjrzeć się samemu kodowi platformy, polecam oficjalne repozytorium projektu na GitHubie. Znajduje się tam m.in. szczegółowa instrukcja kompilacji. Projekt jest całkowicie opensource’owy i darmowy, więc każdy, kto ma chęć i umiejętności, może stać się jego współtwórcą jako niezależny contributor: https://github.com/joyent/node.
Wskazówki dla programistów tworzących aplikacje na platformę Node.js
Poniżej podaję kilka wskazówek dotyczących tego, na co należy zwrócić uwagę podczas tworzenia aplikacji na tę platformę.
- Ze względu na proces developerski Node’a (dość częste aktualizacje) w przypadku aplikacji intensywnie korzystających z jakiś specyficznych mechanizmów zaleca się “freezowanie” (zamrażanie) używanej wersji platformy. Nowe wersje mogą bowiem zawierać kod potencjalnie niebezpieczny dla aplikacji napisanych stricte pod starsze wersje. Nowe wersje pojawiają się średnio co 11 dni, aktualną w chwili pisania tego opracowania była 0.10.11 (koniec lipca 2013 roku).
- Zawsze należy zapewnić obsługę błędów. Nawet najdrobniejszy nieobsłużony błąd lub wyjątek spowoduje “zabicie” procesu Node’a. Pamiętać należy, że będzie to dotyczyło wszystkich użytkowników.
- Zawsze deklaruj zmienne, używając słowa kluczowego ‘var’.
- Bezwzględnie należy używać analizatorów składni JavaScript, takich jak JSLint oraz JSHint – najlepiej z najbardziej restrykcyjnymi opcjami (pokazują wtedy m.in. użycie niezadeklarowanych zmiennych, nieprawidłowych operatorów porównania itp.). Należy także używać tzw. “strict mode”, co przełącza silniki JavaScript w tryb zgodności z przyszłymi i zalecanymi praktykami programistycznymi oraz uniemożliwia uruchomienie kodu zawierającego pewne specyficzne konstrukcje językowe (“Strict mode” w Mozilla Developer Network).
- Pod żadnym pozorem nie wolno uruchamiać procesu Node z uprawnieniami użytkownika uprzywilejowanego.
- Jeśli korzystasz z ciasteczek sesyjnych (więcej o sesjach w aplikacjach Node w drugiej części) zawsze ustawiaj flagi ‘Secure’ oraz ‘HTTPOnly’.
Podsumowanie
Aplikacje tworzone na platformę Node.js z punktu widzenia web applications security to w zasadzie “krok w tył” (całkiem nowe zagrożenia oraz stare zagrożenia w “nowej” skórze, jak choćby XSS). Z drugiej strony – nie do przecenienia jest szybkość działania oraz ‘event loop’ pozwalające na tworzenie naprawdę bardzo szybkich i wydajnych aplikacji internetowych, w których szybkość i możliwość wykonywania asynchronicznie wielu żądań jest niezastąpiona.
Należy pamiętać, że zarówno sam projekt Node.js, jak i aplikacje na nim bazujące to dość nowa rzecz. Oznacza to, że wciąż jest niewiele osób, które interesują się tematyką bezpieczeństwa tej platformy, niewiele jest także aplikacji, które można atakować (to oczywiście uwaga dotycząca sieciowych przestępców). Stąd, jak na razie, stosunkowo mało informacji o podatnościach Node’a, na które można się natknąć w Internecie oraz brak doniesień o spektakularnych atakach na takie aplikacje.
Jak dotąd największą znaną aplikacją webową zbudowaną na platformie Node.js jest nowa wersja portalu społecznościowego MySpace. Korzysta z niej również Yahoo!, eBay, Microsoft, LinkedIn, a w USA istnieje firma zapewniająca hosting Node – Nodejitsu. Więcej informacji na ten temat można znaleźć na stronie Node.js – Industry.
Jak piszą niektórzy programiści JavaScript na swoich blogach, mottem dla piszącego bezpieczne aplikacje dla Node powinno być zawsze:
“Node is powerful, and with power comes responsibility”
(Node jest potężny, a wraz z potęgą powinna podążać odpowiedzialność).
Warto zapamiętać sobie te słowa, siadając do projektowania aplikacji w JavaScript.
To jeszcze nie koniec…
W drugiej części opracowania zaprezentuję niebezpieczeństwa związane z użyciem w aplikacjach SPA takich technologii, jak serwerowy framework Express.js, frontendowe frameworki AngularJS oraz Backbone.js, a także zagrożenia związane z wykorzystywaniem w aplikacjach SPA NoSQL-owych baz danych na przykładzie najpopularniejszej z nich – MongoDB.
Źródła
- Analysis of Node.js platform web application
- The Node Security Project
- https://media.blackhat.com/bh-us-11/Sullivan/BH_US_11_Sullivan_Server_Side_WP.pdf
- Node.js Security Old vulnerabilities in new dresses – Sven Vetsch, German OWASP Day 2012
- Content Security Policy 1.1 – W3C Working Draft 04 June 2013
- oficjalna strona projektu Node.js
–-Rafał ‘bl4de’ Janicki (bloorq[at]gmail.com)

Jak zwykle świetny artykuł, wielkie dzięki i z niecierpliwością czekam na kolejną część – zwłaszcza dot. lubianego przeze mnie MongoDB :)
więcej artykułów typu how know i będę happy :)
Spoko, Rafał już pracuje nad kolejną częścią.
Z kolei mamy już gotowy prawie w połowie długi, przeszło 30 stronicowe kompendium dotyczące bezpieczeństwa WiFi – publikacja po wakacjach :)
–ms
Dzięki za świetny artykuł na niezbyt często poruszany temat.
Swietny art, wiele nowych rzeczy do przemyslenia, ALE akurat uzywanie “eval()” nie jest bezpieczne chyba na kazdej mozliwej platformie ever :)
Dokładnie. Jak zobaczyłem przykład z eval() to całą sekcję przewinąłem, bo jak ktoś robi eval() z parametru POST/GET to prosi się o exploit.
Każdy, kto ma jakiekolwiek doświadczenie z językami mającym funkcję eval wie, że należy jej unikać jak ognia. Kod który zawiera eval jest na 99,9% złym kodem.
Z kolei ten, kto próbował napisać aplikację na więcej niż jednym wątku, modułową, lub po prostu dużą, szybko się przekonał, że w globalu należy trzymać nic lub tylko to, co naprawdę jest niezbędne. Tak samo przekonał się, że obsługa błędów jest ważna i musi być traktowana poważnie.
Node.js zupełnie nie jest jak php, do którego autor próbuje go porównywać. Prędziej już przypomina C/C++, perla, Javę albo cokolwiek użyte z fastcgi, tyle że można (ale wcale nie trzeba) użyć wbudowanego serwera www.
@R
@Ojezu
Dziękuję za komentarze.
@Ojezu
W artykule postarałem się opisać zagrożenia dot. aplikacji na Node.js, więc fragment o f-cji eval() opisuje właśnie związane z nią zagrożenia oraz dlaczego nie należy jej stosować, a nie opis jej użycia.
Dokładnie to samo dotyczy porównań aplikacji dla Node z aplikacjami napisanymi dla innych platform – starałem się wskazać różnice, z których wynikają choćby takie zagrożenia, jak Global Namespace Pollution. Przedstawiony obrazowo PoC z logowaniem Ewy i Aleksa jest nie do “odtworzenia” np. w podobnej aplikacji napisanej dla Apache’a w PHP czy w Perlu, prawda?
@bl4de
Sęk w tym, że PoC jest na skrypt, który nigdy nie powinien powstać, bo jest napisany niepoprawnie, a ta niepoprawność wynika z fundamentalnego niezrozumienia, jak działa Node.js, o które można by posądzać autora takiego kodu.
Artykuł nie jest zły – po prostu sądzę, że nie wnosi zbyt wiele nowego z punktu widzenia człowieka, który wie, co to jest Node.js, i jak działa (i.e. czym jest callback).
Argument o obsłudze błędów, jakkolwiek trafiony w kontekście Node.js, dotyczy w zasadzie wszystkich aplikacji zdarzeniowych w każdym języku (hint: libev w C++ i throw z event handlera dają niezłą wybuchową miesankę). Tutaj jest tylko ten problem, że “rzucanie” wyjątków jest niebezpieczne, ale można to rozwiązać np. za pomocą domen (a od niedawna także w semantyce Promises/A – funkcja zwraca promise/wartość lub rzuca wyjątek, ale nie przyjmuje callbacków). Nie jestem za to pewien, czy w Javie/Async było to zrobione lepiej. W .NET jest async/wait, ale to dość niszowa platforma w tych czasach… Kilka osób próbowało przenosić te rozwiązania także do Node.js (głównie za pomocą generatorów-iteratorów, patrz https://github.com/bjouhier/galaxy ), ale w obecnej formie, w moim odczuciu są jeszcze groźniejsze niż styl callbackowy (ponieważ nie zawsze jest jasne, gdzie może nastąpić yield, więc ktoś może nam się wbić w sekcję krytyczną). Być może najlepszym pomysłem byłoby połączenie generatorów-iteratorów z promises – taki yield na obietnicy, który wyszczególniałby miejsca przełamania wykonania i powrotu do kontekstu w samej składni kodu. Do tego jednak jeszcze dość długa droga.
Póki co, piszę przy użyciu Promises/A pewien framework, i sprawują się całkiem dobrze. Wywołania do “niepromisowatych” funkcji trzeba owijać w callbacki, domeny, i try/catch (wszystkie zastosowane liberalnie według uznania), ale da się to przeżyć – szczególnie, że nie jest ich wcale tak dużo w dobrze zaprojektowanej aplikacji, która segreguje obowiązki takie jak I/O i umieszcza w jednej tylko lokalizacji w kodzie.
Liczę za to na ciekawsze materiały n.t. Express i MongoDB (byle bez eval’a JS od usera w kontekście Mongo – kto by coś takiego zrobił?).
@bl4de
Właśnie, node.js jest inny i ma inne podatności, ale moim zdaniem nie można tego nazwać “»krokiem w tył«”. Nie można nawet za bardzo porównywać jego podatności z php, choćby dlatego, że node.js jest frameworkiem i środowiskiem uruchomieniowym dla zdarzeniowych aplikacji asynchronicznych, a nie językiem do serwowania dynamicznych stron internetowych. Mnóstwo wad php siedzi w jego ogromnej bibliotece standardowej/standardowych rozszerzeniach, która w node.js po prostu ma zupełnie inne funkcje. (ile projektów korzysta z mysql_query/psql_query budowanych z danych od użytkownika?).
Na node.js należy dopiero zbudować framework do stron internetowych, który da się napisać tak, by był bezpieczny. I tak jak w przypadku bezpiecznego używania php wystarcza do tego znajomość i zastosowanie paru prostych reguł.
@☃
Artykuł powstał właśnie dla takich osób, które z racji świeżości Node.js mogli nie zetknąć się jeszcze z tematyką bezpieczeństwa związaną z nim. Nie miałem na celu wyczerpać tematu (co jest niemożliwe w tak krótkim opracowaniu) – bardziej miałem zamiar nakreślić pewne zagadnienia, które mogą pojawić się w kontekście tworzenia aplikacji dla Node.
Ponieważ artykuł o aspektach związanych z Express.js, Mongo, czy Angularem mam nadal w stadium developerskim”, postaram się zagłębić w temat tak, by nie poruszać kwestii oczywistych, jak wspominany tu już nie raz eval() :)
@Ojezu
Nie chodzi o porównania z PHP w sensie 1 do 1, bardziej o wskazanie różnic, czy pewnych klas podatności, które są obecne w jednej, a nie istnieją w drugiej platformie. Kwestia być może nazewnictwa lub interpretacji :) Postaram się jaśniej formułować myśli w kolejnych tekstach.
Oczywiście zgadzam się z Twoją wypowiedzią w pełni, poza jednym – mimo, że coraz rzadziej, niż kiedyś, ale jednak wciąż można natrafić na serwisy, w których banalne podatności są na porządku dziennym ;)
Jeśli po pominiemy informacjie na temat eval wychodzi na to że node jest całkiem bezpieczny :)
Sam javascript ma wiele wad. Najpoważniejsze w moim rankingu to :
1. Evel – powinno się zaorać w specyfikacji języka.
2. Definicja zmiennej bez var powinna być zabroniona.
To o czym piszesz “4. Global Namespace Pollution” – ta przypadłość wynika z połączenia dwóch powyższych. Ale to że można sobie zdefiniować zmienną w scpe wyżej to jest fantastyczna zaleta. Po prostu trzeba wiedzieć co się robi.
Pisząc w nodejs należy używać tylko tej dobrej części języka który minimalizuje potencjalne błędy. Żeby node mógł się bardziej rozwinąć, powinna być większa presja na rozwój samego języka a zawłaszcza na usuwanie jego słabych stron.
Pisząc w node nie można sobie pozwolić na takie niedbalstwo jakie występuje w php. Zasadniczo tworzona aplikacja to już pełną parą proces nad którym mamy w 100% kontrolę. Wkraczają tutaj takie same problemy jakie występują przy pisaniu aplikacji np. w c++ (między innymi trzeba zapobiegać wyciekom pamięci).
W EventEmitter podoba mi się to że domyślnie jest ustawiony limit 10 możliwych callbacków do dodania. Można go oczywiście przestawić na więcej ale dzięki temu ostrzeżeniu wyeliminowałem problem w swojej aplikacji który mógł spowodować wycieki.
@Grzegorz – trochę nawiasem mówiąc, rzeczywiście ten eval powinni wywalić – szczególnie że node.js to nie jest jakaś mega staroć, gdzie trzeba by zachować kompatybilność wsteczną. To tak jak w SQLu, gdyby od początku wymusić w językach programowania czy lepiej w DB, niedynamicznie robione zapytania parametryzowane, to pewnie problem z SQLi byłby bardziej niszowy. No ale tu nie ma tak łatwo ze względu właśnie na kompatybilność wsteczną.
Gdybym ja znał jakiegoś programistę strictę pod Node.JS (hobbystę), który wie kiedy wykorzystać PHP (no bo z tego co widzę, Node.JS jest dość podobny C# – a jak każdy dobrze wie, C# nie używa się na siłę do wszystkiego), to bym zarobił miliony $ :(
Tyle projektów, tyle pomysłów…
@józek: jestem ;) ale nie hobbysta :P
Art trochę tendencyjny, bo o większości języków webowych można napisać podobnie (php, java, c#) jeśli chodzi o xss, ddos etc.
Druga sprawa, informacja o tym, że na node chodzi ebay, linkedin, z tego co wiem jeszcze paypal, ale wcześniej informacja, “że nie ma jeszcze kogo atakować” Trochę niespójne.
Czekam niecierpliwie na drugą część związaną z niebezpieczeństwami korzystania z angulara na frontendzie – to będzie dopiero ubaw :)
pozdrowienia
jotka
Część pierwsza a drugiej nie widać. Można się jeszcze spodziewać jakiś tekstów na ten temat?